The Triage Problem AI Is Actually Solving
Radiology departments face a structural mismatch. Imaging volumes have grown faster than radiologist capacity for over a decade, and worklist management — the practice of reading studies in arrival order — cannot distinguish a routine knee MRI from a CT showing active intracranial hemorrhage. A radiologist opening studies sequentially may reach the most time-sensitive finding last.
CT and MRI triage AI addresses one specific part of that problem: detecting findings that require urgent attention and surfacing them to the top of the worklist, or triggering an alert before the on-call radiologist begins reading. The function is detect-and-surface, not interpret-and-diagnose. A triage AI tool that flags a suspected large vessel occlusion is not reading the scan — it is identifying a pattern associated with urgency and routing the case accordingly. The radiologist still interprets the study, confirms or overrides the alert, and communicates the finding.
Understanding that triage AI operates as a detection-and-alert layer — not a replacement for radiologist oversight — is the prerequisite for evaluating the evidence behind it. The question is not whether AI can detect a finding in a controlled dataset. The question is whether that detection translates into reliable, safe worklist prioritization in your patient population, on your scanners, with your workflow.
What FDA Clearance Does and Does Not Tell You
The majority of FDA-cleared radiology AI devices reached the market through the 510(k) pathway. 510(k) clearance requires a manufacturer to demonstrate substantial equivalence to a legally marketed predicate device — it does not require clinical data demonstrating that the device performs safely or effectively in patients. A device can be cleared on the basis of bench testing or algorithmic similarity to an earlier cleared product without a single prospective clinical study.
The practical consequence of that pathway structure is visible in a JAMA Network Open analysis of all FDA pre-market authorizations for radiology AI devices from 1995 through June 2024. Of the 723 devices reviewed, fewer than 30% underwent clinical testing, only 5% underwent prospective testing, and only 8% included a human-in-the-loop evaluation. The authors concluded that most cleared devices had not been validated against defined clinical or performance endpoints.
- 97% of cleared radiology AI devices used the 510(k) pathway, which does not require clinical performance data.
- Fewer than 30% underwent any form of clinical testing prior to clearance.
- Only 5% underwent prospective testing — the study design most relevant to real-world performance.
- Only 8% included a human-in-the-loop evaluation, despite clinical deployment always involving radiologist oversight.
This clearance-versus-evidence gap is the central frame for the rest of this article. The sections below stratify what the evidence actually shows — by indication, modality, study design, and sponsorship — for the CT and MRI triage tools most likely to appear in a procurement shortlist.
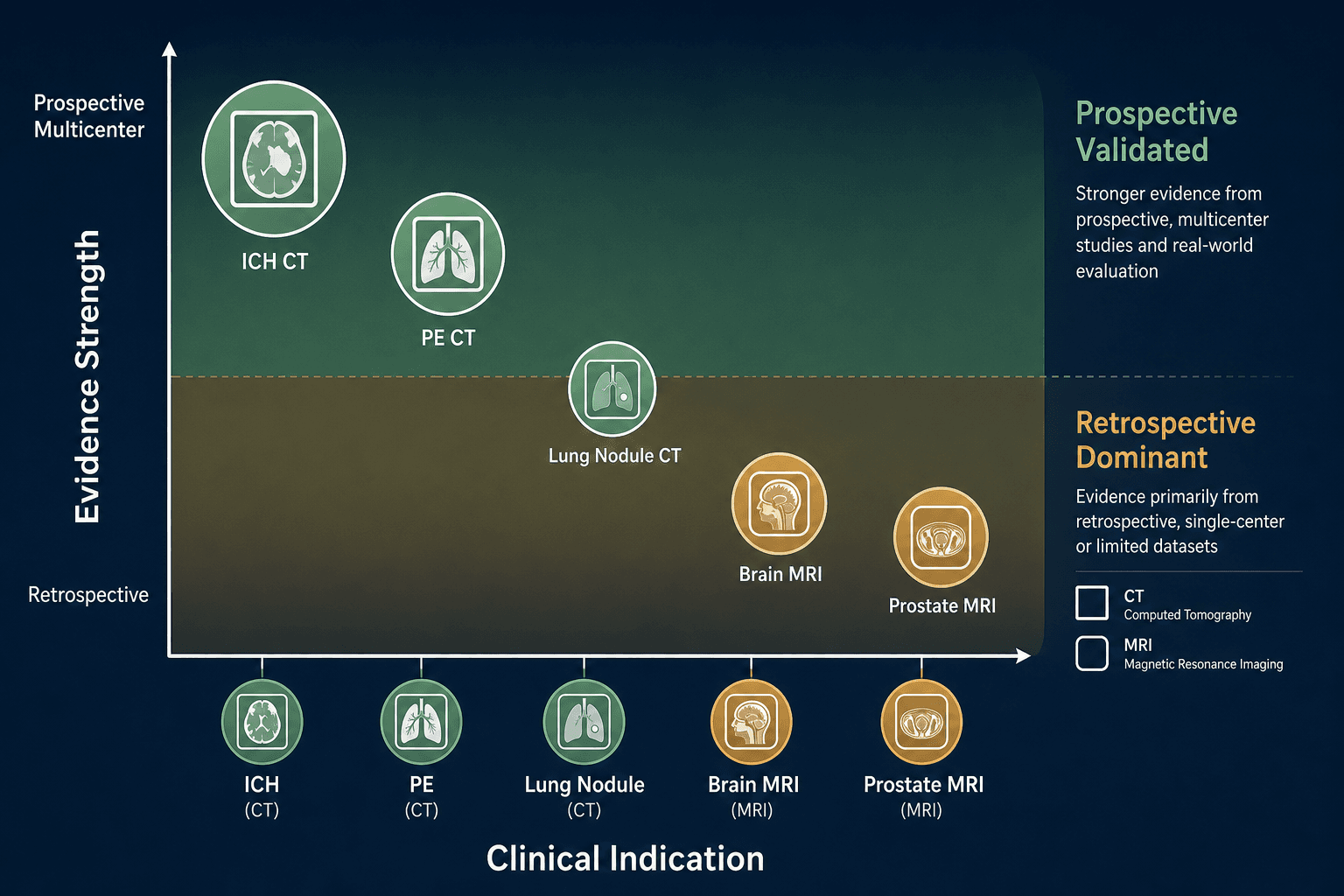
CT Triage Evidence by Indication: Where the Data Is Strongest
Intracranial Hemorrhage and Stroke: The Deepest Prospective Base
Intracranial hemorrhage (ICH) detection on non-contrast CT has accumulated more prospective, multicenter evidence than any other CT triage indication. A structured review of AI workflow automation across imaging modalities found that AI-enabled worklist prioritization has reduced time to diagnosis by up to 90% in some hospital systems for intracranial hemorrhage. That figure represents a ceiling from high-performing implementations, not a typical result — and the underlying evidence is predominantly from systems with strong baseline delays that left more room for improvement.
For large vessel occlusion (LVO) stroke, real-world multicenter data from the VALIDATE study provides the most rigorous deployment-level evidence currently available. Across 14,116 patients at 166 facilities in 17 states, median door-to-neurointerventionalist notification time was 50 minutes at AI-enabled centers versus 89.5 minutes at non-AI centers — a reduction of 39.5 minutes (p<0.001). The study design compared contemporaneous groups across different hospitals rather than pre/post at the same site, which is an important methodological distinction for interpreting the magnitude of the effect.
Comparative studies of Aidoc, RapidAI, Viz.ai, and Brainomix have found comparable LVO detection accuracy among leading platforms for proximal occlusions, with sensitivity across 29 studies ranging from 78% to 97%. Head-to-head comparisons between leading platforms show no statistically significant difference in LVO accuracy for proximal occlusions — platform differentiation at this indication rests more on workflow integration, alert routing, and institutional fit than on raw detection performance.
Pulmonary Embolism on CTPA: Prospective Evidence Now Available
PE detection on CT pulmonary angiography has historically been a retrospective-dominant evidence domain, but prospective data has emerged. A meta-analysis of deep learning systems for acute PE detection pooled data from seven studies covering 36,847 CTPA examinations and found pooled sensitivity of 0.88 and specificity of 0.86 — though all included studies in that meta-analysis were retrospective.
A large retrospective study of a clinically deployed FDA-approved and CE-marked AI algorithm across 3,316 CTPAs found AI sensitivity of 96.8% versus radiologist sensitivity of 91.6%, with the AI missing 23 PE cases compared to 60 missed by radiologists. The authors of that study were explicit that standalone AI use is not warranted — reading a CTPA requires clinical judgment and analysis well beyond PE detection — but the result supports AI's value as a safety-net layer for incidental PE on non-CTPA chest CT.
Lung Nodule CT: Detection Gains Documented, Evidence Base Retrospective-Dominant
Lung nodule detection AI on CT has a well-documented detection advantage in complex cases — studies have found AI detects 8.4% more nodules than radiologists in complex cases, with nodule detection sensitivity up to 95% in controlled evaluations. However, the evidence base for lung nodule AI as a worklist-prioritization tool — rather than a detection aid integrated into routine reads — is predominantly retrospective and single-center. Prospective multicenter outcome trials establishing impact on patient outcomes (as distinct from detection rates) are limited.
| Indication | Modality | Evidence Level | Key Evidence Type | Notable Gap |
|---|---|---|---|---|
| ICH / LVO Stroke | CT | Strongest | Prospective multicenter (VALIDATE: 14,116 patients, 166 facilities) | CTP outputs not interchangeable across platforms (see below) |
| Pulmonary Embolism | CTPA | Moderate–Strong | Large retrospective deployment study; limited prospective trials | Prospective multicenter outcome data limited |
| Lung Nodule | CT | Moderate | Retrospective-dominant; controlled detection gains documented | No prospective worklist prioritization outcome trials |
| LVO / MVO Distal | CT | Weak–Moderate | Vendor-sponsored technical briefs dominant for MVO/distal | Independent prospective evidence for distal occlusions lacking |
MRI Triage Evidence: Fewer Dedicated Triage Tools, Thinner Prospective Base
MRI has a substantially shallower triage-specific evidence base than CT. Three structural factors explain most of the gap: MRI acquisition takes longer than CT, making it less common in time-critical emergency presentations; MRI protocols vary considerably across sites and field strengths, complicating multicenter study design; and the highest-acuity emergency indications (hemorrhage, LVO stroke) are predominantly evaluated first with CT, which is faster and more accessible in acute settings.
An important distinction applies across MRI AI broadly: the majority of FDA-cleared and CE-marked MRI AI products address reconstruction, segmentation, or detection — not worklist-prioritization alert generation. A tool that accelerates MRI reconstruction or delineates a tumor boundary is not a triage tool in the same sense as an ICH detection alert system. According to a structured review of AI workflow coverage, 70% of MRI workflow steps now have available AI solutions — but deployment maturity, measured by prospective evidence and real-world outcome data, varies sharply by indication.
Prostate MRI: The Strongest Single-Domain MRI AI Evidence
The PI-CAI (Prostate Imaging: Cancer AI) trial provides the most rigorous prospective MRI AI evidence currently available in any single domain. In that trial, a prostate MRI AI system achieved AUROC 0.91 versus 0.86 for radiologists, detecting 6.8% more clinically significant cancers at equivalent specificity. This is a detection and risk stratification function, not a worklist urgency triage function in the acute sense — but it represents the gold standard for what prospective MRI AI evidence looks like when properly designed.
Brain MRI: Moderate Evidence, Predominantly Segmentation
Brain MRI AI evidence is moderate in depth, with the strongest results in tumor segmentation and lesion detection tasks. True worklist-prioritization alert generation for brain MRI — analogous to the ICH detection function on CT — is a much smaller evidence category. Most brain MRI AI tools in clinical use are detection or segmentation aids integrated into the reading workflow, not upstream alert systems that route unread studies.
- Prostate MRI AI: strongest prospective evidence (PI-CAI trial, AUROC 0.91), detection and risk stratification function.
- Brain MRI AI: moderate evidence, primarily segmentation and lesion detection; limited prospective alert-generation evidence.
- Reconstruction and denoising tools: broadly deployed, evidence focused on image quality metrics rather than clinical outcome.
- Worklist urgency prioritization (true MRI triage): sparse evidence, most time-critical cases evaluated with CT first.
CT vs. MRI Maturity: Why the Evidence Bases Diverge
The evidence asymmetry between CT and MRI triage AI is not a coincidence of research priority — it reflects structural differences in how the modalities are used clinically and how AI studies can be designed around them.
| Factor | CT | MRI |
|---|---|---|
| Acquisition speed | Seconds to minutes | Minutes to 45+ minutes |
| Emergency use cases | Common (hemorrhage, LVO, PE, trauma) | Less common; CT usually first-line |
| Protocol standardization | Higher; enables multicenter studies | Lower; field strength and protocol variation complicates pooling |
| Outcome endpoints | Clear (time-to-treatment, door-to-puncture) | Less acute; longer outcome timeframes |
| CE-marked AI products (Oct 2024) | 89 products | 66 products |
| Prospective triage AI trials | Multiple (VALIDATE, PE deployment studies) | Limited; prostate PI-CAI strongest example |
The 89 CE-marked CT AI products versus 66 for MRI — based on Health AI Register data from October 2024 — reflects this use-case concentration. The gap is not evidence that MRI AI is less capable in principle; it reflects where time-critical clinical problems and measurable outcome endpoints concentrate. Brain tumor segmentation is a meaningful clinical advance, but it does not generate the prospective time-to-treatment outcome data that stroke triage studies do.
Cross-Cutting Evidence Quality Problems
Four evidence quality problems affect CT and MRI triage AI across indications. They are not specific to any single vendor or modality — they are structural features of how this field has developed.
1. Vendor-Sponsored vs. Independent Study Divergence
The pattern is consistent across the stroke and PE literature: vendor-sponsored or manufacturer-affiliated studies report higher accuracy than independent validations. For the emerging middle vessel occlusion (MVO) and distal occlusion detection categories, most favorable detection claims originate from manufacturer-sponsored technical briefs, not independent peer-reviewed prospective studies. A claim about MVO sensitivity from a product launch brief should be weighted differently from the same metric reported in an independently conducted prospective trial.
2. CTP Non-Interchangeability: A Direct Patient Safety Issue
CT perfusion (CTP) analysis is central to treatment eligibility decisions in extended-window stroke — determining whether a patient meets criteria for thrombectomy based on ischemic core volume and penumbra estimates. The DAWN and DEFUSE 3 trials, which established the evidence basis for extended-window treatment, used RapidAI-derived CTP values as their measurement standard.
This is not a vendor performance ranking issue. It is a calibration and clinical protocol issue. Institutions switching CTP analysis platforms, or comparing outputs across platforms for the same patient, need to account for these discrepancies explicitly. The scoping review by Dorochowicz et al. documents this problem in the context of a broader review of the LVO AI landscape.
3. Alert Fatigue: An Under-Studied Dimension
Higher sensitivity for distal vessel occlusions and MVO detection increases the false-positive alert burden. Independent reviews have noted that this increase in alerts for smaller, more distal occlusions has not been accompanied by demonstrated improvement in functional outcomes on the modified Rankin Scale (mRS). The concern is that expanding AI alert coverage to lower-confidence detections may add cognitive load to radiologists managing multiple alert streams without proportionate clinical benefit.
4. Algorithm Version-Drift After Clearance
FDA clearance validates performance against a specific dataset at a specific point in time. Post-deployment model updates — whether driven by retraining, expanded indication claims, or infrastructure changes — are not automatically subject to re-validation. As one clinical AI commentator noted, regulatory clearance 'does not guarantee continued clinical performance or relevance as the model and clinical context evolve.'
Authorization reflects validation against a specific dataset at a specific point in time.
For health systems, this means the performance characteristics cited in a procurement decision may not reflect the model version currently running in production — particularly for vendors who update their algorithms continuously under a predetermined change control plan (PCCP). Version management and post-deployment monitoring policies are therefore material procurement questions, not administrative afterthoughts.
Deployment Implications: Procurement Questions Worth Asking
The evidence quality landscape described above translates into specific due-diligence questions that procurement teams, radiology department leaders, and health system informaticists should ask before committing to a triage AI platform. These are not a vendor checklist — they are open questions that require substantive answers from the vendor and from your own institution's validation capacity.
- Study design: Are the supporting studies prospective or retrospective? Single-center or multicenter? The 5% prospective testing rate across cleared radiology AI devices means the default is retrospective — ask specifically for prospective evidence.
- Sponsorship: Were the supporting studies funded or conducted by the manufacturer, or by independent investigators? Both types of evidence are useful, but they should be weighted differently.
- External validation: Were validation datasets drawn from sites with similar patient demographics, imaging protocols, and scanner hardware to your facility? Performance may degrade in populations underrepresented in training data.
- Human-in-the-loop evaluation: Only 8% of cleared radiology AI devices included human-in-the-loop evaluation. Ask whether the tool's performance claims incorporate radiologist interaction, or whether they reflect standalone algorithmic performance.
- CTP platform alignment: If evaluating CTP-based stroke AI, confirm which clinical trial thresholds your stroke protocol uses and verify they were calibrated to that platform's outputs. Do not assume interchangeability across vendors.
- Version management: How are algorithm updates communicated, documented, and validated post-deployment? What is the vendor's policy on performance re-testing after updates?
- Local validation: Does your institution have a process for validating AI tool performance in your own patient population before full clinical deployment? Published performance figures are a starting point, not a local guarantee.
The evidence quality landscape for CT and MRI triage AI is uneven — not because the technology is uniformly weak, but because the regulatory pathway that governs most clearances does not require the evidence that clinical deployment demands. ICH and LVO stroke AI on CT has a genuinely strong prospective base. PE triage AI has grown substantially. MRI triage tools outside prostate cancer detection remain thinner on prospective outcome data. Understanding which indications sit in which evidence tier — and asking the right questions about the specific tools under consideration — is what separates informed procurement from clearance-based assumption.
Comments
Join the discussion with an anonymous comment.