Why Emergency Medicine Is AI's High-Stakes Proving Ground
Emergency departments operate under conditions that concentrate AI's potential value and failure risk simultaneously. Overcrowding, time pressure, cognitive overload, and the irreversibility of delayed decisions in sepsis and stroke create a clinical environment where even modest improvements in early detection can translate directly to mortality differences — and where algorithmic errors can accelerate harm.
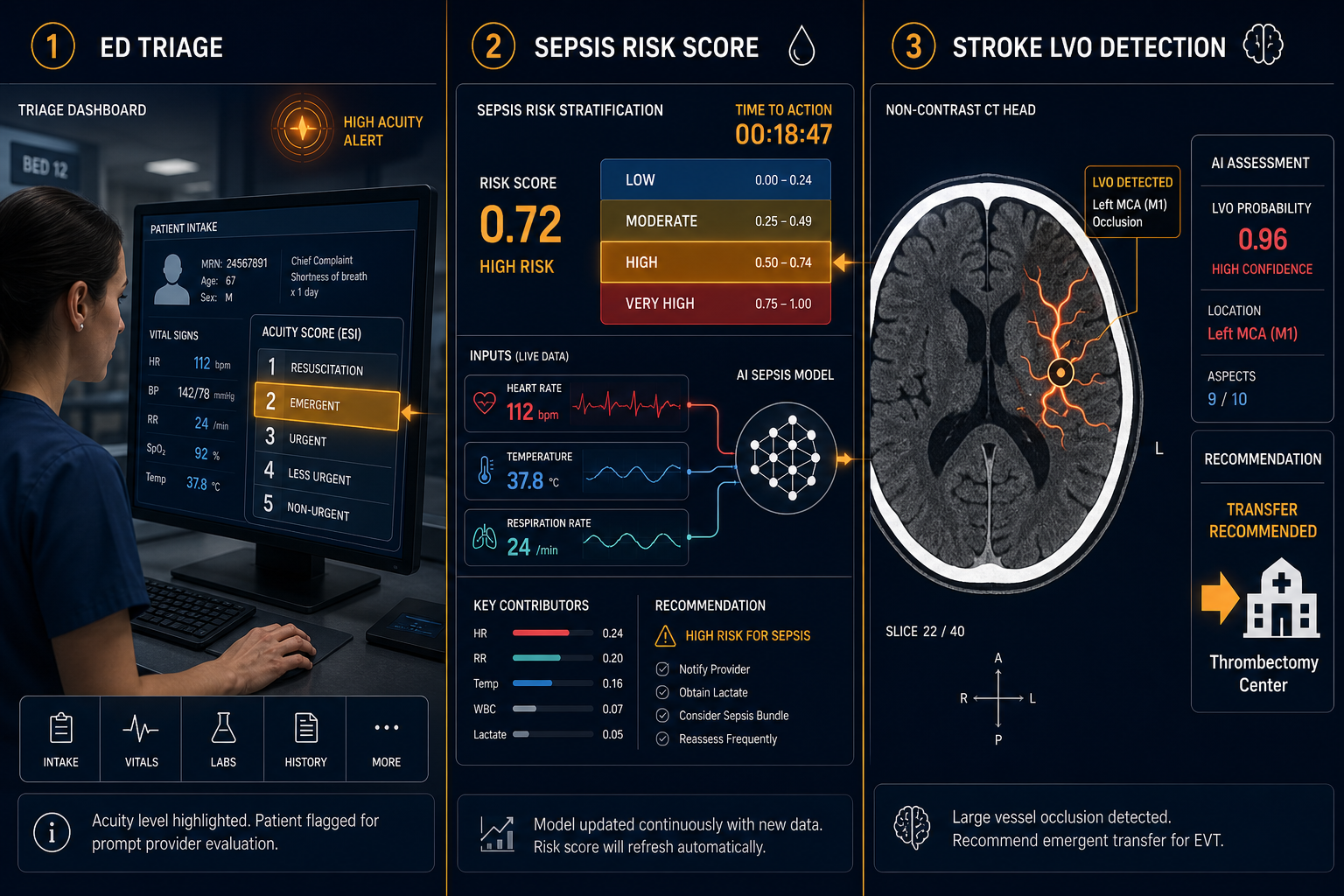
The scale of the problem is concrete. Sepsis accounts for approximately 850,000 ED presentations annually in the US. Large vessel occlusion stroke requires thrombectomy within a narrow treatment window that is routinely missed in hospitals without on-site neuroradiology. ED triage systems are making acuity decisions on tens of millions of patients per year under staffing pressure that makes systematic under-triage a known, measurable problem.
Against that backdrop, AI decision support in emergency medicine attracts both intense development interest and legitimate scrutiny. The central question for clinicians and health system administrators is not whether AI tools exist — they do, in significant numbers — but whether the evidence base for a given tool in a given use case actually justifies clinical deployment.
This article addresses that question across three use cases — ED triage augmentation, sepsis risk stratification, and stroke LVO detection — that currently occupy sharply different positions on the deployment-readiness spectrum. That differentiation, not the existence of AI tools in general, should drive procurement and governance decisions. For readers seeking broader context across additional clinical domains, the multi-domain AI clinical application brief provides a parallel overview.
AI-Augmented ED Triage: Algorithmic Promise, Limited Outcome Evidence
The most comprehensive current synthesis of AI triage evidence is a 2025 PRISMA-compliant systematic review covering six studies published between 2020 and 2025. The aggregate picture is technically encouraging but clinically premature.
Across those six studies, AI triage systems reduced mis-triage rates by 0.3–8.9% and achieved AUROCs of 0.836–0.875 for acuity and hospitalization prediction. Voice-AI documentation was 19% faster than manual entry. Those are meaningful performance signals — but the evidence base that generates them has structural limits that cannot be dismissed.
- All six studies were single-center. No multi-site prospective validation exists for AI triage at the systematic review level.
- All six studies were conducted outside the US — South Korea, Germany, Greece, Taiwan, and China. None used the Emergency Severity Index (ESI) system that governs US ED triage workflows. Generalizability to US settings is undemonstrated.
- None demonstrated RCT-level evidence of mortality or length-of-stay benefit. The evidence supports algorithmic performance on intermediate endpoints, not patient outcomes.
- Implementations ranged from pilot to early prospective phases, with limited clinician acceptance data.
One study does illustrate what AI triage can achieve when targeted at a specific high-stakes condition. A retrospective cohort of 1,059,386 adult ED encounters across four academically affiliated EDs demonstrated that NLP of nursing triage notes combined with clinical data achieved AUC 0.94 for sepsis prediction at initial presentation. The model identified sepsis in 76% of patients where clinical screening had not been initiated at triage, and in 97.9% of septic patients who subsequently required vasopressors. Positive predictive value was 0.18, reflecting the low base rate of sepsis in the broader ED population — which means false-positive management requires deliberate workflow design.
For readers interested in AI imaging support within the ED more broadly — including modalities beyond the three use cases covered here — the analysis of AI chest X-ray triage in the emergency department covers two distinct roles and their separate evidence bases.
AI Sepsis Prediction: Strong Performance Data, Deployment Gaps
The 2026 Zhang et al. systematic review and meta-analysis provides the most rigorous current quantification of AI sepsis prediction performance. Across 36 studies and 98 predictive models, AI achieved a pooled AUROC of 0.87 (95% CI 0.86–0.88) compared to 0.66–0.74 for traditional scoring systems including SIRS, qSOFA, and MEWS. Gradient boosting models performed best, reaching AUROC 0.90. The performance advantage over rule-based scores is consistent and substantial.
The important qualifier is that this performance is not the same as deployment-readiness. The meta-analysis found methodological heterogeneity exceeding I² of 99%, and most included studies lacked prospective external validation. The review explicitly identifies inadequate external validation and insufficient deployment-oriented evaluation as the primary barriers to clinical adoption, concluding that operational readiness and guidance for safe deployment remain underdeveloped.
The Sepsis ImmunoScore: First FDA-Authorized AI Sepsis Tool
The Sepsis ImmunoScore (Prenosis) represents the current regulatory high-water mark for AI sepsis tools. It received FDA De Novo marketing authorization (DEN230036) on April 2, 2024 — the first AI-based diagnostic to receive FDA authorization specifically for sepsis risk stratification.
The prospective multicenter validation enrolled 3,457 patients across five US sites, with external validation on 698 patients across three sites achieving AUROC 0.81 (95% CI 0.77–0.86). The tool stratifies patients into four risk bands with likelihood ratios ranging from 0.1 (low risk, 3% sepsis probability) to 8.3 (very high risk, 69.7% sepsis probability), and the very-high band predicts in-hospital mortality of 18.2%.
The design intent matters for deployment planning. The Sepsis ImmunoScore integrates 22 parameters via EMR and is triggered by blood culture order as a proxy for clinical suspicion of infection — it is not a passive screening tool that alerts on the broader ED population. That architecture is a deliberate response to the alert fatigue documented with passive sepsis monitoring approaches.
Alert Fatigue and the External Validation Gap
The contrast with passively deployed sepsis screening tools is instructive. The Epic Sepsis Model, widely deployed across hundreds of US hospitals, achieved AUROC 0.63 in independent external validation — requiring physicians to evaluate 109 alerted patients to detect one additional case of sepsis not otherwise identified. That gap between development-setting performance and real-world deployment performance is the central warning in the sepsis AI evidence base (see also the ESM governance case study for the institutional accountability dimensions of that deployment arc).
A 2026 narrative review from Amsterdam UMC found that despite a growing evidence base showing performance advantages for AI over traditional scores, 'a clear lack of evidence to show that AI tools for sepsis management are currently improving care' remains the primary barrier to widespread implementation. The review notes that most tools have been validated only in observational studies, with limited RCT evidence.
AI Stroke Decision Support: The Strongest Real-World Evidence in Emergency AI
Of the three use cases covered here, stroke LVO detection has traveled furthest along the path from algorithmic promise to demonstrated real-world impact. The evidence base is larger, more recent, and — in one landmark study — prospective and national in scope.
The NHS England National Study: Largest Prospective Stroke AI Evidence to Date
A prospective observational study published in The Lancet Digital Health evaluated Brainomix 360 Stroke AI software across 107 NHS hospitals in England, covering 452,952 patients over a five-year span from 2019 to 2023. The scale and design make it the largest prospective real-world evidence dataset for any emergency AI application reviewed here.
The headline finding: endovascular thrombectomy rates at evaluation sites doubled — from 2.3% to 4.6% — compared to a 62.5% relative increase at control sites over the same period. Multivariate logistic regression showed an odds ratio of 1.57 (95% CI 1.33–1.86, p<0.0001) for EVT when AI was used at the individual case level. For patients transferred for EVT, median door-in door-out time was 64 minutes shorter with AI assistance (128 vs. 192 minutes, p<0.0001).
The benefit was not uniform across hospital types. In exploratory analysis, primary stroke centers showed an odds ratio of 2.34 (95% CI 1.78–3.10) for EVT with AI — nearly double the OR at comprehensive stroke centers (1.28). That divergence has direct implications for where AI stroke deployment adds the most value.
FDA-Cleared Stroke AI Tools
The stroke AI landscape is notable for the density of FDA clearances relative to other emergency AI domains. Current FDA-cleared tools for LVO detection and stroke triage include:
- Brainomix 360 Triage Stroke — 510(k) clearances K232496 (November 2023) and K251983 (August 2026)
- Viz.ai LVO ContaCT — 510(k) clearance K223042 (October 2022)
- RAPID LVO (iSchemaView) — multiple clearances including K221248
- Methinks CTA Stroke — 510(k) clearance K251590 (August 2025)
- syngo.CT LVO Detection (Siemens) — 510(k) clearance K243145 (April 2025)
NCCT-Based LVO Detection: Complementary Evidence
The NHS study and the FDA-cleared tools above are primarily CTA-based. A complementary evidence stream covers non-contrast CT (NCCT)-based LVO detection, which matters for settings where CTA is not immediately available.
A 2026 multinational retrospective validation study of the JLK CTL algorithm across Korean (n=723) and US (n=240) cohorts found standalone AI AUC of 0.963 in the Korean cohort and 0.899 in the US cohort. In a reader study with eight physicians across training levels, AI assistance improved pooled AUC from 0.718 to 0.852, sensitivity from 46.6% to 63.7%, and specificity from 91.9% to 94.9%. Number needed to screen was 18.2 per missed LVO prevented. Automation bias was rare — 0.83% negative consultation rate — with a benefit-to-harm ratio of approximately 9:1. Neurology residents showed the largest performance gain, from AUC 0.695 to 0.880.
A separate multicenter validation of the same JLK CTL algorithm across six Korean stroke centers (n=534) confirmed AUC 0.859, sensitivity 0.787, and specificity 0.832. The JLK CTL LVO score independently predicted three-month unfavorable functional outcomes (each one-point increase associated with 2% higher likelihood of worse mRS, p=0.011) and correlated with infarct volume on diffusion-weighted imaging (r=0.54).
Cross-Cutting Limitations: What the Evidence Base Cannot Yet Tell Us
Across all three use cases, several limitations apply broadly enough to warrant explicit acknowledgment before procurement decisions.
- Geographic generalizability gaps. AI triage evidence is entirely non-US and single-center. Stroke validation studies are heavily concentrated in Korean health systems, with limited US validation for NCCT-based tools. Even the NHS England stroke study reflects a healthcare system with different transfer infrastructure than US community hospital networks.
- Retrospective-to-prospective performance degradation. The sepsis AI evidence base illustrates this most starkly: the Epic Sepsis Model's retrospective AUROC appeared clinically meaningful, but independent external validation produced 0.63. Retrospective performance metrics are necessary but not sufficient evidence for deployment decisions.
- Dataset bias and demographic representation. A 2025 JMIR Medical Informatics review flagged that AI tools developed on majority-population datasets can produce substantially worse performance for minority patients. The AI triage evidence base largely lacks explicit demographic stratification, and validation studies across all three domains rarely report performance by race or ethnicity.
- Alert fatigue as a systemic deployment challenge. Passive, population-wide sepsis screening generates alert volumes that can exceed clinical capacity to respond meaningfully. The Sepsis ImmunoScore's triggered design addresses this architecturally; tools without similar design constraints require institution-level alert governance before deployment.
- Clinician acceptance and workflow integration friction. The 2025 Cureus systematic review identified insufficient clinician acceptance metrics as a gap across AI triage studies. Evidence of technical performance does not predict adoption — or appropriate use — in live clinical workflows.
- Absence of long-term outcome data. Even the NHS stroke study — the most methodologically robust evidence reviewed here — explicitly notes the absence of long-term patient outcome data. For all three use cases, the existing evidence documents process improvements and intermediate-endpoint performance, not definitive mortality or functional outcome benefits from AI-assisted care.
- Hallucination and AI error risks in high-stakes contexts. As generative AI components are incorporated into clinical decision support interfaces, the risk of confidently stated incorrect outputs in time-pressured emergency settings requires specific governance attention — this is qualitatively different from the predictive model errors that characterize sepsis scores and LVO detection algorithms.
Deployment Readiness Across Three Use Cases: A Structured Comparison
The three use cases covered here are not interchangeable from a procurement or governance standpoint. The table below summarizes their current positions across the dimensions that matter most for health system adoption decisions.
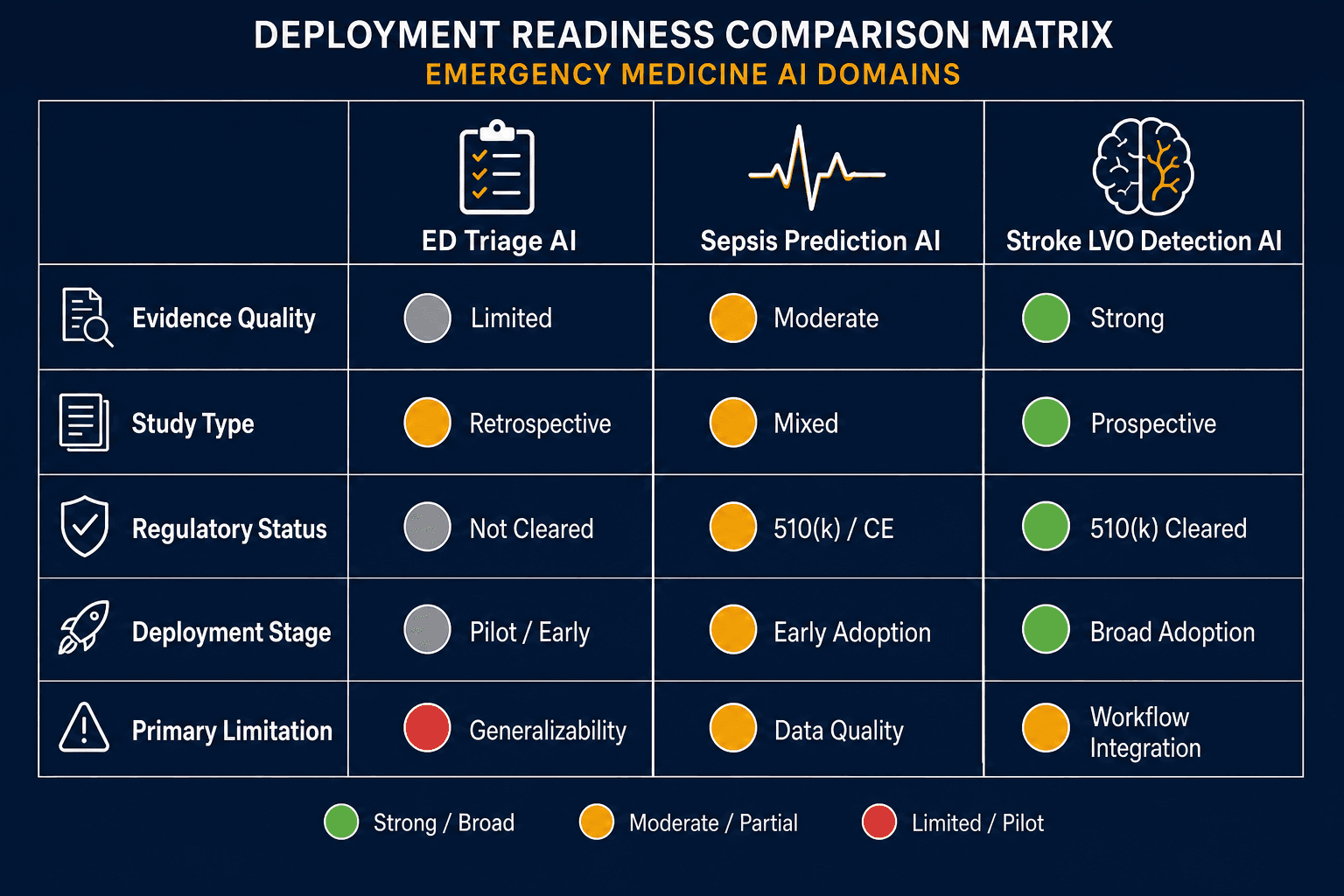
| Dimension | ED Triage AI | Sepsis Prediction AI | Stroke LVO Detection AI |
|---|---|---|---|
| Evidence Quality | Moderate — AUROCs 0.836–0.875, mis-triage reduction 0.3–8.9% | Strong on performance — pooled AUROC 0.87 across 36 studies; weak on outcomes | Strongest in the category — prospective national observational study, 452,952 patients |
| Best Available Study Type | Systematic review of 6 single-center studies; no RCT | Meta-analysis (98 models); one prospective multicenter external validation (Sepsis ImmunoScore) | Prospective national observational study (Brainomix, NHS England); multiple multicenter retrospective validations |
| Regulatory Status | No FDA-cleared AI triage classification system identified | One FDA De Novo authorization (Sepsis ImmunoScore, DEN230036, April 2024) | Multiple FDA 510(k) clearances (Brainomix, Viz.ai, RAPID LVO, Methinks, Siemens syngo) |
| Deployment Stage | Pilot and research; early prospective in selected non-US centers | Broad deployment of unvalidated tools (ESM); one FDA-authorized tool with external validation | Broad clinical deployment; standard of care at many comprehensive and primary stroke centers |
| Primary Known Limitation | No US ESI-based validation; no RCT outcome evidence; all evidence from single non-US centers | High heterogeneity (I² >99%); passive monitoring produces alert fatigue; external validation gap for most tools | Prospective observational design (not RCT); Korean-heavy NCCT validation; benefit concentration at primary stroke centers |
Clinical and Procurement Implications
The deployment-readiness analysis above translates differently for each use case. What follows is a structured framing for emergency physicians, hospitalists, clinical informaticists, and health system administrators — not clinical guidance for individual patients.
Stroke LVO AI: Supports Adoption at Primary Stroke Centers
The NHS England prospective study provides the most actionable guidance on where stroke AI adds the most value: primary stroke centers without on-site neuroradiology. The exploratory OR of 2.34 at primary centers versus 1.28 at comprehensive centers points to a structural reason — AI partially compensates for the absence of immediately available specialist interpretation and accelerates transfer decisions.
Multiple FDA-cleared tools exist across CTA and NCCT modalities. Health systems evaluating procurement should prioritize tools with evidence in patient populations and imaging infrastructure comparable to their own — the NCCT-based reader studies demonstrate that the largest performance gains accrue to neurology residents and early-career clinicians, which has direct implications for training program deployments.
Sepsis AI: One Strong FDA-Authorized Option, Governance Required
The Sepsis ImmunoScore's FDA De Novo authorization, prospective external multicenter validation, and triggered (rather than passive) design make it the most defensible current procurement option for AI sepsis risk stratification in US hospitals. The four-band likelihood ratio structure provides clinically interpretable outputs rather than a single score.
Implementation planning must address the workflow context explicitly: the tool is designed for patients where blood culture has already been ordered, signaling active clinical suspicion. Deploying it as a passive background monitor would replicate the alert-fatigue conditions that undermine broadly deployed sepsis screening tools. Health systems that have experienced high alert volumes from existing passive sepsis tools should treat the Sepsis ImmunoScore's trigger architecture as a feature, not a limitation.
ED Triage AI: Pilot and Research Context Only
The current evidence base does not justify broad deployment of AI triage augmentation in US emergency departments. The single-center, non-US, non-RCT evidence base is a structural constraint — not a temporary gap that will close without additional prospective validation work specifically in ESI-based US ED settings.
For health systems interested in AI triage, the appropriate framing is research or institutional pilot with prospective outcomes tracking. Procurement decisions should require, at minimum, prospective validation data from patient populations and triage workflows comparable to the target institution — and should specify outcome endpoints beyond acuity prediction AUROCs, including undertriage rate, length of stay, and 30-day revisit rates.
Comments
Join the discussion with an anonymous comment.