
From Documentation Tool to Clinical Advisor: How ACI Crossed a Line
Ambient Clinical Intelligence (ACI) entered clinical practice as a documentation automation tool: a microphone in the room, a transcript in the background, and a structured note waiting after the encounter. That version of ACI now has a reasonably solid evidence base. But the commercially deployed platforms of 2026 are no longer doing only that.
The term "Ambient Clinical Intelligence" is itself unstable. Some vendors use it interchangeably with ambient scribing. Others — and this distinction matters clinically — apply it to a broader platform that includes real-time decision support delivered during the encounter itself. That definitional ambiguity is not a minor labeling issue; it is a symptom of the regulatory and clinical governance problem this article addresses.
For this analysis, ACI refers to the full platform: ambient documentation (generating structured notes from live encounter transcripts) plus any real-time clinical intelligence layer that surfaces information, generates differential diagnoses, suggests exam maneuvers, or stages preliminary orders during the encounter. Both functions may live in the same product. They do not have equivalent evidence bases, and conflating them creates a patient safety exposure that is not yet widely recognized.
What ACI Decision Support Actually Does During an Encounter
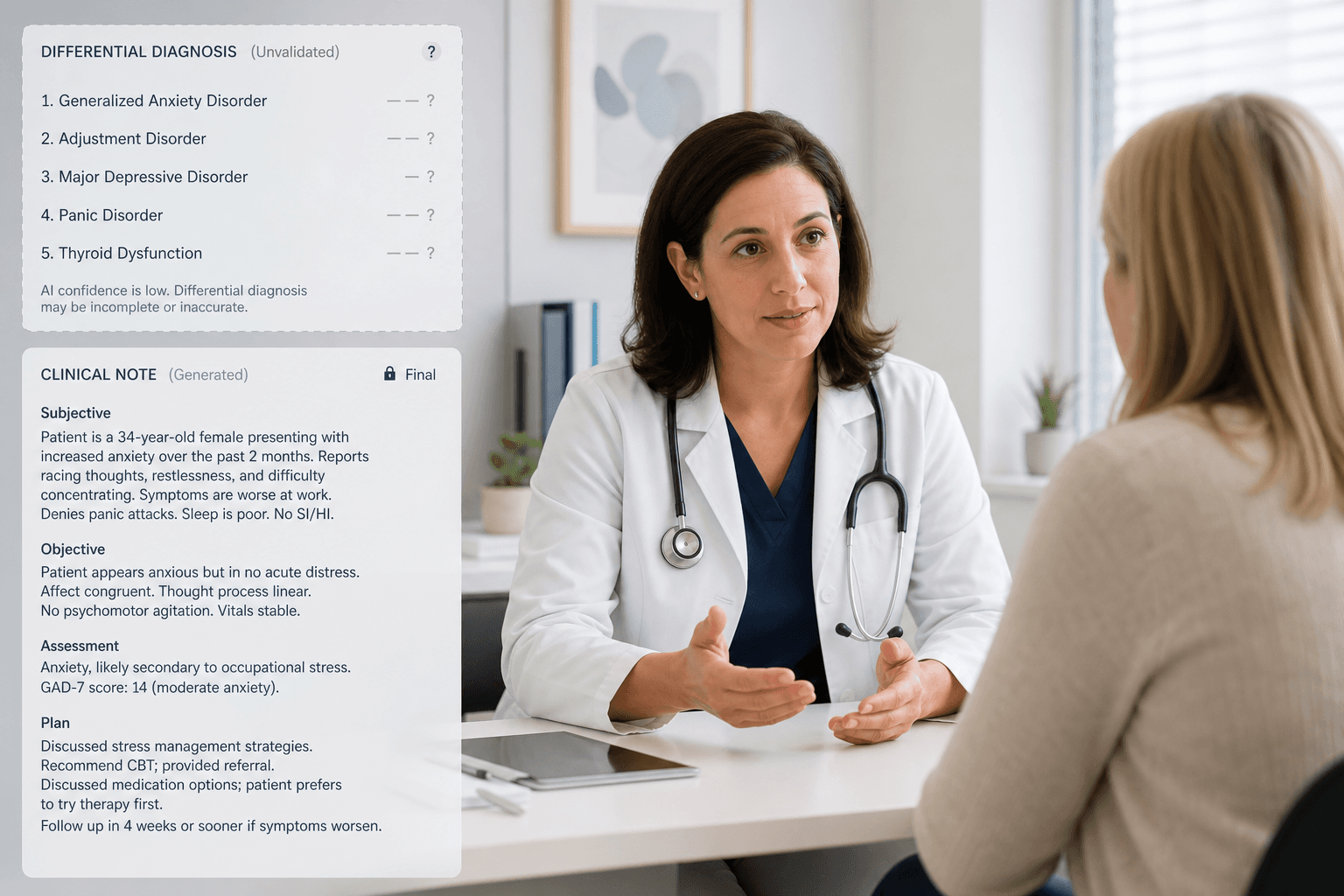
The decision-support layer of ACI is not a future roadmap feature. It is being marketed and sold now.
Glass Health's ambient CDS platform describes four categories of real-time clinical support delivered during the patient encounter, not after it:
- Evolving Differential Diagnosis — the system generates and refines a differential diagnosis in real time as patient history unfolds.
- Suggested History Questions — contextually relevant prompts for additional history questions, guided by the emerging clinical picture.
- Suggested Physical Maneuvers — recommendations for specific physical examination maneuvers based on the patient's presentation.
- Preliminary Next Steps — suggested workup, testing, and management options as the clinical picture emerges.
These features are described on Glass Health's product page as providing "evidence-based clinical decision support that improves efficiency, diagnostic accuracy, and treatment efficacy" — a claim made without citation to prospective clinical outcome data on any of these specific functions.
Microsoft Dragon Copilot markets itself as an "extensible AI workspace" that surfaces information and automates tasks. Its advertised capabilities include responses drawn from transcripts and third-party medical references, accurate coding suggestions, and clinical evidence summaries for physicians — and surfacing "key patient data and clinical insights within workflow" for nurses. These are decision-support functions by any standard clinical informatics definition.
The critical distinction for clinicians: post-encounter note generation and real-time encounter-embedded decision support are different functions with different risk profiles. A hallucination in a note is a documentation error. A hallucination in a real-time differential diagnosis suggestion is a potential contribution to diagnostic error at the moment clinical reasoning is forming.
The Evidence Asymmetry: What Is and Is Not Validated
The scribing evidence base is now substantial. Multiple prospective cohort and pre-post studies document meaningful reductions in documentation time, cognitive load, and burnout. The Sutter Health quality improvement study (n=100 clinicians, Abridge platform) showed a reduction in time in notes per appointment from 6.2 to 5.3 minutes, with statistically significant reductions across NASA-TLX cognitive load dimensions.
The Providence Health System study — a randomized step-wedge controlled design, one of the stronger study designs available in this literature — found that ACI reduced documentation burden and provider frustration, with early implementers averaging 26 fewer minutes per day in after-hours documentation ("pajama time"), and a 30.3% reduction in reported burnout. This is the kind of controlled methodology that informs reasonable adoption decisions for the scribing function.
The decision-support layer has no equivalent. As of mid-2026, no published prospective clinical outcome study has evaluated whether real-time ambient DDx generation, suggested physical maneuvers, or order staging improves diagnostic accuracy, reduces diagnostic error, or affects patient outcomes in any measurable way.
Studies of ambient scribes have mainly focused on clinician efficiency, well-being, time savings, and costs, with no evidence yet of improved clinical or patient-centered outcomes.
That finding, from the Ohde et al. perspective in npj Digital Medicine, applies to the scribing literature as a whole — and the absence of patient-centered outcome evidence is even more acute for the decision-support functions built on top of that foundation.
| Function | Evidence Type | Prospective Clinical Outcome Data | Study Design Ceiling |
|---|---|---|---|
| Ambient documentation (note generation) | Prospective cohort, pre-post, step-wedge RCT | No — efficiency and cognitive load outcomes only | Randomized step-wedge controlled study (Providence/Nuance DAX) |
| Real-time differential diagnosis generation | None published | None | No peer-reviewed study exists |
| Suggested history questions | None published | None | No peer-reviewed study exists |
| Suggested physical exam maneuvers | None published | None | No peer-reviewed study exists |
| Preliminary next steps / order staging | None published | None | No peer-reviewed study exists |
The Mayo Clinic narrative review frames the current state of AI scribe systems as operating primarily at Stages 1 and 2 — automating clinical and administrative documentation. The evolution toward stages where AI generates differential diagnoses, alerts clinicians to missed screening questions, and assists with ordering workflows is explicitly characterized as aspirational, not a validated standard. That framing should calibrate how clinicians read vendor marketing language describing these same functions as current, production features.
Why Ambient CDS Is a Structurally Different Safety Problem
Traditional clinical decision support systems (CDSS) — alert-based rules engines in the EHR, drug-drug interaction flags, sepsis screeners — deliver suggestions as discrete interruptive events. A clinician receives the alert, evaluates it, accepts or dismisses it. The alert is legible as a system output requiring a decision.
Ambient CDS works differently. Suggestions are generated and surfaced inside the same interface and workflow as note generation. The differential diagnosis emerging on screen is adjacent to, or embedded within, the documentation being produced. The cognitive boundary between "what I think" and "what the system suggested" is architecturally blurred in a way that traditional CDSS alerts are not.
Automation bias — the tendency to over-rely on automated systems, accepting outputs without sufficient independent evaluation — is a documented phenomenon in clinical AI contexts. In the ambient CDS setting, the structural conditions for automation bias are stronger than in traditional CDSS, for two reasons:
- Embedded delivery reduces decision salience. Suggestions surfaced in the note-generation flow carry no equivalent of the alert-box interruption that signals "this is a system recommendation requiring your explicit response." Passive acceptance becomes the path of least resistance, particularly under time pressure.
- Real-time delivery intersects with active clinical reasoning. A differential diagnosis suggested while a clinician is still forming their own assessment — not after — can anchor reasoning before independent judgment has fully formed.
The Topaz et al. commentary in npj Digital Medicine documents AI scribe hallucination rates of approximately 1–3% in the documentation context — and flags adoption outpacing validation as a patient safety concern. A 1–3% error rate in an administrative note is a meaningful clinical documentation problem. That same error rate in a real-time differential diagnosis suggestion carries a materially different risk profile: the erroneous output is being introduced at the point where a clinician is making decisions, not reviewed later in a chart.
The Duke SCRIBE framework evaluation provides a concrete illustration of the underlying error mode. When presented with implausible laboratory values — a negative potassium level, for example — GPT-4o retained both the value and an associated interpretation without modification in 60.1% of cases. The system did not flag or correct clinically nonsensical inputs. That failure mode in a note is a documentation accuracy problem. In a real-time DDx system processing similarly implausible or ambiguous clinical data, the same failure would shape a differential diagnosis before the clinician has had the opportunity to catch the underlying data error.
The Regulatory Classification Gap: Where Ambient CDS Currently Sits
The regulatory situation for ACI platforms with decision-support features is not ambiguous because the frameworks are absent. It is ambiguous because the frameworks that do exist have not been applied consistently to this class of tool.
Most ACI platforms — including those that now incorporate real-time DDx generation and clinical insight surfacing — are classified as administrative software rather than Software as a Medical Device (SaMD). That classification places them outside FDA premarket oversight for clinical decision support, despite offering functions that meet the ordinary language and regulatory definition of non-exempt clinical decision support under the 21st Century Cures Act.
Most AI scribes operate without specific FDA oversight, as they are often classified as administrative tools rather than medical devices, creating a regulatory gap that leaves safety and efficacy standards largely unaddressed.
The Ohde et al. perspective makes the implication explicit: tools capable of summarization and decision support "have the potential to alter what and how information is communicated and influence clinical decision-making" — and that this raises "important questions about oversight, safety standards, and accountability" that current regulatory frameworks have not resolved. The FDA's SaMD and CDS guidance has not yet provided clear, harmonized guidance on classification and risk categorization specifically for ambient AI systems that combine documentation with clinical intelligence functions.
- Administrative software classification means no premarket clinical validation requirement. Vendors can market decision-support claims without submitting evidence to any regulatory body.
- No post-market surveillance obligation is attached to administrative software classification. If an ambient DDx system consistently biases toward or against certain diagnoses in specific patient populations, there is no regulatory mechanism requiring detection or reporting.
- SaMD classification remains unresolved for ambient AI systems with both documentation and decision-support functions. The FDA's existing CDS guidance distinguishes exempt from non-exempt CDS, but the ambient format — continuous, embedded, generated from a live encounter transcript — does not map cleanly onto the framework's assumptions about how CDS is delivered.
A Two-Tier Evaluation Framework for Clinicians
The evidence asymmetry between ACI's documentation and decision-support layers calls for a two-tier approach to platform evaluation. Applying the same evidence standard to both functions is an error in both directions: it either inappropriately dismisses a documentation tool with solid efficiency evidence, or it inappropriately accepts a decision-support function on the strength of documentation evidence that does not apply to it.
| Evaluation Dimension | Tier 1: Documentation Layer | Tier 2: Decision-Support Layer |
|---|---|---|
| Evidence basis | Prospective cohort and step-wedge RCT data on efficiency, cognitive load, burnout | No published prospective clinical outcome data as of mid-2026 |
| What can be compared across vendors | Documentation time, cognitive load metrics, note accuracy, hallucination rates | Nothing — no head-to-head published data exists |
| Adoption decision basis | Sufficient evidence to inform adoption decisions with appropriate monitoring | Evidence is pre-clinical; adoption requires explicit governance, monitoring, and vendor transparency obligations |
| Key risk to manage | Hallucination and omission in notes (~1–3% error rate); privacy of ambient recording | Automation bias in clinical reasoning; unvalidated diagnostic suggestions; regulatory grey zone |
| What to ask the vendor | Hallucination rate data, note accuracy benchmarks, SCRIBE-equivalent evaluation, opt-out workflows | Clinical outcome validation studies, regulatory classification basis, how suggestions are delivered, error disclosure obligations, monitoring mechanisms |
Tier 1: Evaluating the Documentation Layer
For the documentation function, evidence is sufficient to make comparative vendor judgments — but the comparisons that matter are not always the ones vendors foreground. Documentation time reduction and satisfaction scores are the headline metrics. The more clinically consequential questions concern accuracy.
- What is the platform's documented hallucination rate in note generation, and how is it measured? Is the measurement methodology peer-reviewed or vendor-internal?
- What categories of clinical information have documented omission patterns? Medications, allergies, and social history are known weak points across multiple evaluation studies.
- How does the system handle implausible or contradictory clinical data in the transcript — does it flag inconsistencies or silently incorporate them into the note?
- What is the clinician review burden in practice, and is there documented evidence that review catches the error categories the system generates?
Tier 2: Evaluating the Decision-Support Layer
For the decision-support layer, the absence of clinical outcome evidence means the evaluation framework shifts from evidence comparison to governance requirements. The questions are not "which vendor's DDx is more accurate" — there is no published data to answer that. The questions are about what obligations the vendor accepts and what controls your institution will require.
- What is the regulatory classification of the decision-support features specifically? Administrative software or SaMD? If administrative, on what basis are clinical accuracy claims being made?
- What prospective clinical validation has been conducted for decision-support functions? Not documentation efficiency studies — studies specifically measuring whether real-time DDx or suggested maneuvers affect diagnostic accuracy or patient outcomes.
- How are decision-support suggestions visually and interactively distinct from documentation output? What UI design choices prevent passive acceptance? Is there a required explicit acknowledgment before suggestions influence the note?
- What error disclosure obligations does the vendor accept contractually? If a decision-support suggestion contributes to a documented adverse event, what reporting and disclosure obligations apply?
- What monitoring mechanisms does the vendor offer for decision-support accuracy over time? Model drift in LLM-based systems is documented; without post-deployment monitoring, accuracy degradation may not be detectable.
- Can the decision-support layer be disabled independently of the documentation layer? Platforms that bundle both functions without independent controls limit an institution's ability to adopt the validated function while withholding the unvalidated one.
The two-tier framework is not an argument against adopting ACI. The documentation evidence is real, and clinician burnout driven by documentation burden has its own patient safety consequences. The framework is an argument for precision: adopt what is validated with appropriate monitoring, and govern what is unvalidated with explicit institutional accountability rather than vendor-delegated trust.
Comments
Join the discussion with an anonymous comment.