
Why Clinicians Need a Structured Evaluation Framework for AI
The number of AI tools entering clinical environments has reached a point where passive observation is no longer viable. By 2025, approximately 80% of U.S. hospitals reported using AI in at least one clinical or operational function, according to industry surveys compiled by Uvik. Yet the same data shows that under 20% of institutions report sustained, high-success use of AI in core clinical diagnosis. The gap between adoption and reliable deployment is not a technology problem — it is an evaluation problem.
Clinicians and medical directors are being asked to assess tools that range from narrowly focused diagnostic algorithms to broad generative AI chatbots, often without a systematic way to separate robust evidence from vendor claims. The challenge is compounded by the fact that FDA clearance — the most common regulatory signal — does not equate to proven clinical efficacy. A 2025 analysis found that fewer than 2% of FDA-cleared AI devices are supported by randomized clinical trials, and many FDA summaries lack basic study design information, sample sizes, and comparator details.
This article provides a practical, evidence-grounded framework based on the AMIA AI Evaluation model, published in BMJ Quality & Safety by Jackson and Shortliffe in 2025. The framework organizes evaluation into three sequential phases — technical performance, usability and workflow, and clinical impact — and gives clinicians a structured way to ask the right questions before committing to a tool.
The AMIA Three-Phase Evaluation Framework
The AMIA framework, introduced by Jackson and Shortliffe in their 2025 BMJ Quality & Safety editorial, requires that AI solutions be assessed through three sequential phases. Skipping a phase — for example, deploying a tool with strong technical performance but poor usability — almost guarantees failure in real-world settings.
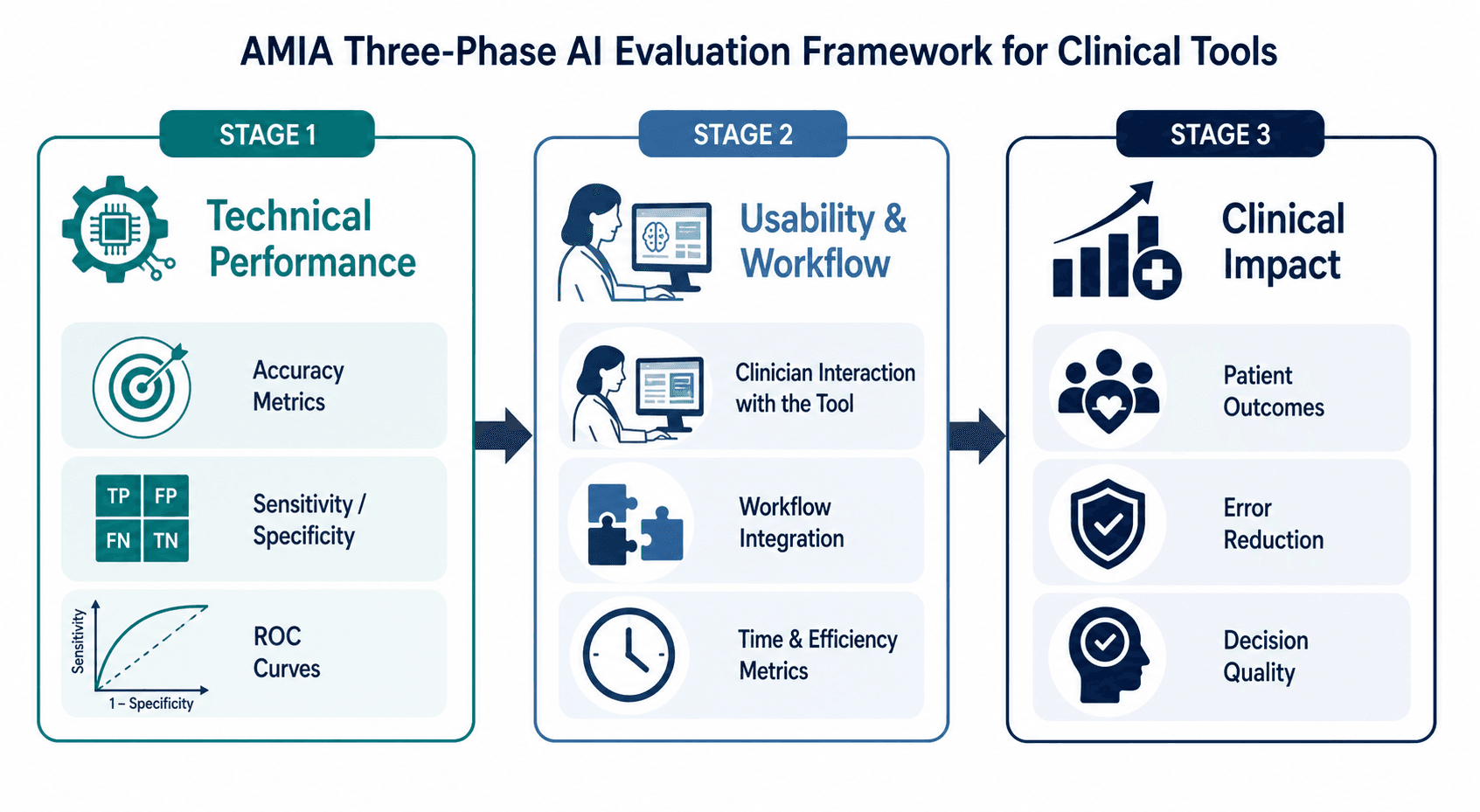
Phase 1: Technical Performance
This phase asks: Does the model actually work as intended? Key questions include: What is the model's sensitivity, specificity, and area under the receiver operating characteristic curve (AUROC)? On what dataset were these metrics calculated? Was the dataset representative of the target population? Was there external validation on an independent dataset? The editorial emphasizes that models need re-evaluation when conditions change, as performance can drift over time or with clinician behavioral changes.
Phase 2: Usability and Workflow
A technically accurate model that disrupts clinical workflow will not be adopted. This phase evaluates how the tool integrates into existing processes: Does it require additional clicks? Does it introduce alert fatigue? Does it fit into the clinician's natural decision-making sequence? The AMIA framework stresses that if usability has not been tested in real workflows, deployment is unlikely to produce the desired clinical result.
Phase 3: Clinical Impact
The ultimate question: Does using the tool improve patient outcomes? This requires studies that compare care with versus without the AI tool — not human versus machine. The editorial notes that AI solutions supporting rather than replacing clinicians should be evaluated by comparing provider performance with versus without the tool. Clinicians often prioritize evidence of effects on clinical outcomes, but if a tool is not accurate and usability has not been tested, the impact phase cannot be meaningfully assessed.
- Phase 1 — Technical Performance: Accuracy, sensitivity, specificity, external validation, dataset representativeness.
- Phase 2 — Usability & Workflow: Integration into clinical processes, alert fatigue, cognitive load, time burden.
- Phase 3 — Clinical Impact: Patient outcomes, provider performance with vs. without the tool, cost-effectiveness.
Where the Evidence Is Strong: Narrow-Task AI in Diagnostics
The strongest evidence for AI in clinical practice comes from narrow-task models — algorithms trained to perform a single, well-defined diagnostic task. These models benefit from focused training data, clear ground truth, and established evaluation protocols. Three examples illustrate what robust evidence looks like.
| Application | Performance Metric | Evidence Type | Key Source |
|---|---|---|---|
| Diabetic retinopathy detection | ~96% accuracy | Multiple prospective studies | Industry compilation (Uvik, 2026) |
| AI-assisted mammography screening | 90–92% sensitivity for early-stage breast cancer | Systematic review + 2026 RCT | BMJ Open 2025; 2026 RCT evidence |
| Ophthalmology surgical safety system | >99% authentication rate after 3 months | Large-scale prospective study (37,529 cases) | Tabuchi et al., cited in Jackson & Shortliffe (2025) |
The ophthalmology study by Tabuchi and colleagues, cited in the AMIA editorial, is particularly instructive. The AI system was deployed in a real surgical setting to verify patient identity, laterality, and lens type before cataract surgery. Initial authentication rates ranged from 67.4% to 96.3% depending on the verification task. Over three months, as the system was refined and clinicians adapted to the workflow, authentication rates exceeded 99%. This study demonstrates that technical performance can improve post-deployment — but only if the system is monitored and re-evaluated.
For a deeper look at the mammography evidence, see our detailed review of AI in breast cancer screening, which covers the BMJ Open 2025 systematic review and the 2026 RCT evidence.
Where the Evidence Is Thin: FDA Clearance Gaps and Missing RCTs
FDA clearance is often treated as a proxy for clinical validity, but the evidence base behind cleared devices is far thinner than most clinicians assume. A systematic analysis of FDA 510(k) and De Novo authorizations for AI/ML-enabled medical devices found that fewer than 2% are supported by randomized clinical trials. Many FDA summaries do not report sample sizes, comparator groups, or basic study design features.
| Evidence Type | Proportion of FDA-Cleared AI Devices | Implication for Clinicians |
|---|---|---|
| Randomized clinical trial (RCT) | < 2% | Regulatory clearance does not guarantee proven clinical benefit |
| Prospective validation study | ~15–20% (estimated) | Most devices lack pre-market prospective data |
| Retrospective single-center study | ~40–50% (estimated) | Limited generalizability; risk of overfitting |
| No published peer-reviewed evidence | ~30–40% (estimated) | Vendor claims cannot be independently verified |
This does not mean FDA-cleared devices are ineffective. It means that regulatory clearance answers a different question than clinical efficacy. The FDA evaluates whether a device is "substantially equivalent" to a predicate device (510(k) pathway) or whether it has reasonable assurance of safety and effectiveness (De Novo pathway). Neither pathway requires demonstration of improved patient outcomes.
For clinicians evaluating a device, the regulatory status is a starting point, not an endpoint. The AMIA framework's three phases provide a more complete picture than any single regulatory designation.
Workflow AI: Documentation, Error Reduction, and ROI
Beyond diagnostic tools, a growing category of AI applications targets clinical workflow — reducing documentation burden, minimizing errors, and improving operational efficiency. These tools are often evaluated differently than diagnostic algorithms, with metrics focused on time savings, error reduction, and return on investment.
| Workflow AI Metric | Reported Figure | Source Type | Caveat |
|---|---|---|---|
| Reduction in physician charting time | 40–45% | Industry compilation / vendor surveys | Not from peer-reviewed studies; may reflect optimal conditions |
| Reduction in clinical note error rates | 25–30% | Industry compilation / vendor surveys | Error definition varies across studies |
| Average ROI on healthcare AI investments | 3.2:1 | Industry compilation / vendor surveys | ROI calculation methodology varies; 12–18 month payback period reported |
| Hospital adoption of AI in at least one function | ~80% | Industry survey (2024–25) | Includes administrative and operational AI, not just clinical |
The 40–45% reduction in charting time and 25–30% reduction in error rates are frequently cited by vendors, but clinicians should note that these figures come from industry compilations and vendor surveys, not from independently conducted peer-reviewed studies. The ROI figure of 3.2:1 with a 12–18 month payback period similarly lacks rigorous independent validation.
This is where Phase 2 of the AMIA framework — usability and workflow evaluation — becomes critical. A tool that reduces documentation time by 40% in a controlled pilot may introduce new burdens in a real clinical environment: additional clicks to verify AI-generated notes, time spent correcting errors, or cognitive load from managing yet another interface. The AMIA editorial's emphasis on re-evaluation when conditions change applies directly here: a workflow AI that performs well in one clinic may fail in another with different patient volume, EHR configuration, or staff composition.
Generative AI: The Evidence Gap and Hallucination Risks
Generative AI — large language models and multimodal foundation models — represents the most hyped and least evidenced category of AI in healthcare. The contrast with narrow-task AI is stark.
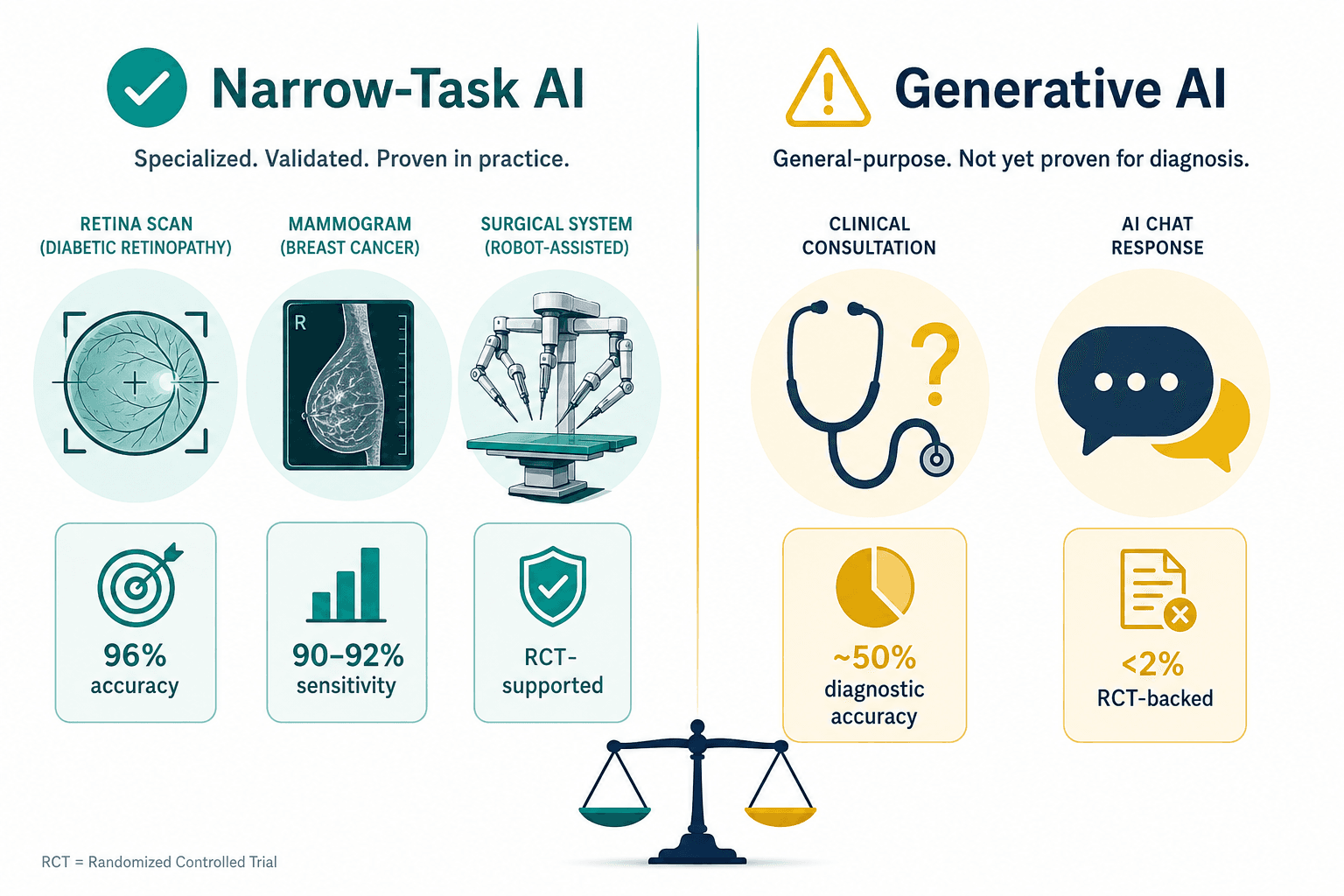
Meta-analyses of generative AI models in clinical diagnostic tasks report average accuracy of approximately 50% — comparable to non-expert clinicians but well below specialist performance. This figure, cited in the Uvik compilation, aggregates across varied clinical tasks and model types, so the specific performance of any single model may differ. However, the pattern is consistent: generative AI is not yet reliable enough for independent clinical decision-making.
The Wolters Kluwer expert insights, published in December 2025, highlight a critical risk: "Users still struggle to identify responses that sound authoritative but are clinically invalid, even with credible sources cited." This phenomenon — hallucination — is not a bug that will be fixed in the next update; it is a fundamental characteristic of current generative AI architectures. The same piece warns of the "emerging risk of clinical deskilling from GenAI use," as clinicians may become over-reliant on outputs they cannot independently verify.
- Generative AI diagnostic accuracy averages ~50% in meta-analyses — comparable to non-expert clinicians, below specialists.
- Hallucination risk: models produce clinically invalid responses that sound authoritative, and users struggle to identify them.
- Clinical deskilling: over-reliance on AI outputs may erode clinician diagnostic skills over time.
- Shadow AI: clinicians are adopting generative AI tools without organizational oversight, creating governance and liability gaps.
- Fewer than 2% of FDA-cleared AI devices are supported by RCTs — and most generative AI tools are not FDA-cleared at all.
How to Read an AI Study: Key Questions for Clinicians
Evaluating AI research requires a different lens than evaluating traditional clinical trials. The following questions, derived from the AMIA framework and common pitfalls identified in the literature, provide a structured approach.
| Question | Why It Matters | What to Look For |
|---|---|---|
| What is the false positive and false negative rate? | Accuracy alone is misleading when disease prevalence is low. A 99% accurate test for a condition with 1% prevalence still produces more false positives than true positives. | Reported sensitivity, specificity, positive predictive value, and negative predictive value for the target population. |
| What is the baseline human performance? | AI studies often compare the model to an unstated or weak human baseline. The clinically relevant comparison is human + AI vs. human alone, not human vs. machine. | Studies should report the performance of clinicians with and without the AI tool. |
| Was the model externally validated? | Models perform worse on populations different from their training data. External validation on an independent, diverse dataset is essential. | Look for validation on data from a different institution, geographic region, or time period. |
| Has the model been re-evaluated after deployment? | Performance can drift over time due to changes in patient population, clinical practice, or data distribution. | Studies or reports should include post-deployment monitoring data, not just pre-market performance. |
| Is the study funded by the vendor? | Industry-funded studies are more likely to report positive results. Disclosure does not invalidate the study, but it should be noted. | Funding and conflict-of-interest statements should be clearly reported. |
The AMIA editorial specifically cautions that AI solutions supporting rather than replacing clinicians should be evaluated by comparing provider performance with versus without the tool. A study that only compares the AI model to unaided human performance tells you nothing about whether the tool improves care in practice.
For a broader overview of AI applications across medical domains, see our clinical application brief.
A Practical Checklist for Evaluating AI Tools
The following checklist translates the AMIA three-phase framework into actionable questions that clinicians and medical directors can use in procurement discussions, clinical evaluation committees, or when reviewing a vendor proposal.
| Phase | Question | What to Ask the Vendor or Researcher |
|---|---|---|
| 1. Technical Performance | What is the model's sensitivity and specificity on an external validation dataset? | Request the exact metrics, dataset size, population demographics, and validation method. |
| 1. Technical Performance | Was the training dataset representative of our patient population? | Ask for demographic breakdown (age, sex, race/ethnicity, comorbidities) of the training and validation datasets. |
| 1. Technical Performance | Has the model been re-evaluated after deployment? | Request post-market surveillance data or published re-evaluation studies. |
| 2. Usability & Workflow | How does the tool integrate into our existing EHR and workflow? | Request a live demonstration in a clinical environment, not a scripted demo. |
| 2. Usability & Workflow | What is the additional time burden per clinical encounter? | Ask for time-motion study data comparing workflow with and without the tool. |
| 2. Usability & Workflow | Does the tool introduce alert fatigue or cognitive overload? | Request data on alert rates, override rates, and clinician satisfaction surveys. |
| 3. Clinical Impact | Does using the tool improve patient outcomes? | Look for RCTs or prospective studies comparing care with vs. without the tool. |
| 3. Clinical Impact | What is the ROI and payback period? | Request a detailed cost-benefit analysis with transparent methodology, not a vendor-provided estimate. |
| 3. Clinical Impact | What are the known failure modes and safety incidents? | Ask for documented failure modes, adverse events, and how they were addressed. |
For a practical example of how this framework applies to a specific clinical domain, see our analysis of AI clinical decision support in primary care, which walks through the AMIA phases in the context of preventive care and diagnostic applications.
The AMIA framework does not guarantee that every evaluated tool will succeed, but it provides a systematic way to ask the right questions — and to recognize when the answers are not yet available. In a field where hype often outpaces evidence, that discipline is the most valuable tool a clinician can have.
Comments
Join the discussion with an anonymous comment.