What Is Algorithmic Bias in Clinical AI?
Algorithmic bias in clinical AI is not a single defect introduced at model training. It is a lifecycle issue — bias can originate at any stage from data collection through post-deployment monitoring, and each source requires a distinct detection and mitigation strategy. When left unaddressed, biased models can systematically underdiagnose or misdiagnose patient subgroups, widen existing health disparities, and erode the trust that clinicians and patients place in AI-assisted decision-making.
The clinical stakes are concrete. The Epic Sepsis Model, a widely deployed commercial algorithm, demonstrated significant real-world deterioration after deployment: it missed two-thirds of sepsis cases while frequently issuing false alarms (Wong et al., 2021, cited in Cross et al., 2024). This is not an isolated case. A 2022 analysis by Celi et al. found that over 50% of published clinical AI models used training data drawn from only the United States or China, raising fundamental questions about generalizability to other populations and care settings.
This glossary-guide provides a structured reference for healthcare professionals, researchers, compliance officers, and health IT decision-makers. It covers a taxonomy of bias sources across the AI pipeline, the major audit frameworks available for detecting bias (including the novel G-AUDIT framework co-developed with the FDA CDRH), stage-specific mitigation methods, the current regulatory landscape, and practical steps for healthcare organizations.
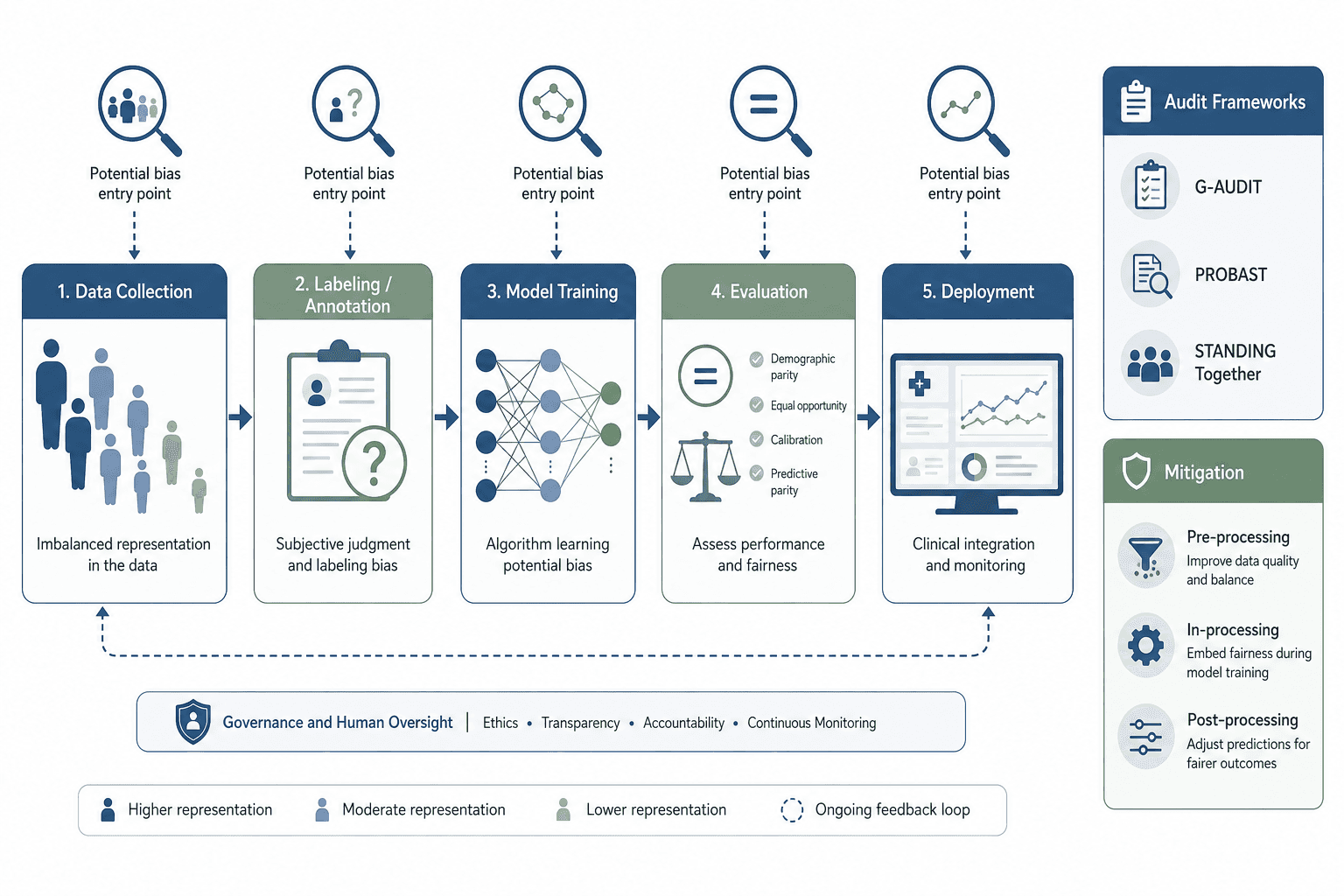
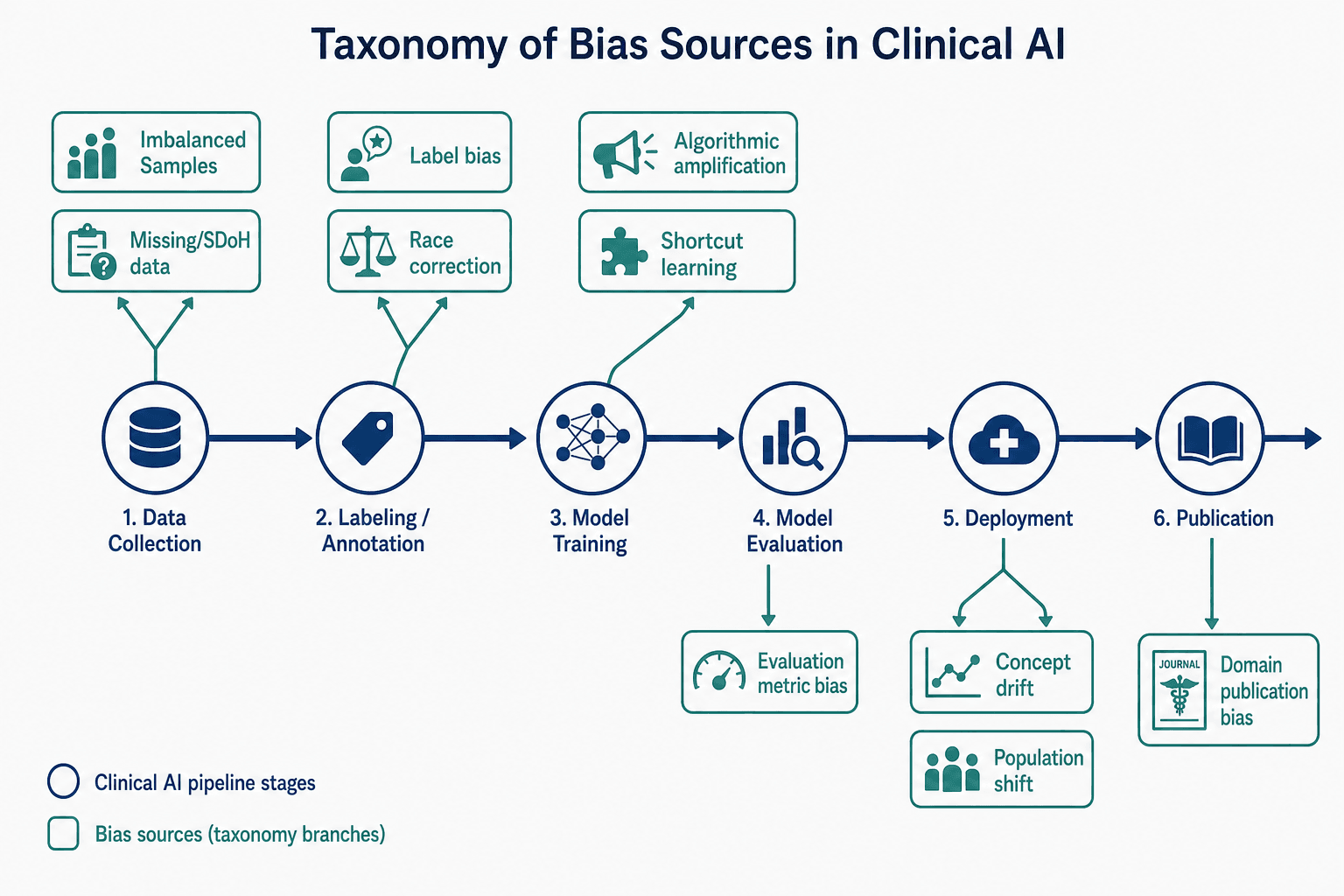
A Taxonomy of Bias Sources Across the AI Pipeline
Understanding where bias enters the pipeline is the first step toward managing it. The taxonomy developed by Cross et al. (2024) maps bias sources to six stages of the clinical AI lifecycle. Each stage presents distinct failure modes that require different detection tools and mitigation strategies.
| Pipeline Stage | Bias Source | Example | Key Reference |
|---|---|---|---|
| Data Collection | Imbalanced sample sizes | A dermatology AI trained on 90% light skin images, 10% dark skin images | Cross et al., 2024 |
| Data Collection | Missing or nonrandomly missing data | EHR data lacking social determinants of health (SDoH) fields | Cross et al., 2024 |
| Labeling | Label bias / annotator subjectivity | Radiologists labeling chest X-rays differently based on prior clinical context | Cross et al., 2024 |
| Labeling | Race correction in clinical algorithms | Historical race-based adjustments in eGFR and pulmonary function equations | AHA PREVENT Equations (Cross et al., 2024) |
| Model Training | Shortcut learning | Model learns to associate hospital site markers with disease rather than pathology | Drenkow et al., 2025 (G-AUDIT) |
| Model Training | Algorithmic amplification | Model magnifies small imbalances in training data into large prediction disparities | Cross et al., 2024 |
| Evaluation | Overreliance on whole-cohort metrics | AUC of 0.92 overall masks 0.78 AUC for a specific demographic subgroup | Cross et al., 2024 |
| Deployment | Concept drift | Sepsis prediction model degrades as clinical protocols change over time | Wong et al., 2021 (Epic Sepsis Model) |
| Deployment | Population shift | Model trained on academic medical center data deployed in a community hospital | Cross et al., 2024 |
| Publication | Domain publication bias | Radiology accounted for over 40% of AI publications in 2019, skewing the evidence base | Cross et al., 2024 |
The G-AUDIT framework (Drenkow et al., 2025) provides empirical evidence for how these biases manifest. Applied to the ISIC 2019 skin lesion dataset (25,331 images), G-AUDIT found that non-patient attributes — image height, image width, and year of acquisition — had the highest combination of utility and detectability, meaning they posed a greater shortcut risk than patient demographics like age, sex, or skin color. In the JHM EHR dataset for stigmatizing language prediction, clinical specialty had higher utility than patient race or sex, suggesting models were more likely to exploit clinical-domain shortcuts than demographic ones. For MIMIC-III ICU mortality prediction, missing data indicators (e.g., temperature not recorded) and intervention attributes (ventilator use, vasopressin administration) were highly detectable potential shortcuts.
Key Audit Frameworks for Detecting Bias
Several formal audit frameworks have been developed to help clinical AI teams detect bias systematically. Each framework is designed for a specific purpose and pipeline stage. Choosing the right framework — or combining multiple frameworks — depends on what you are auditing and when.
| Framework | Developer / Year | Purpose | Pipeline Stage | Key Output |
|---|---|---|---|---|
| G-AUDIT | Drenkow et al., JHU & FDA CDRH, 2025 | Quantitative dataset auditing; identifies shortcut risks via attribute utility and detectability | Data collection / Pre-training | Utility-detectability scores for each attribute; worst-case AUC drop estimates (~0.2 or more for high-utility attributes) |
| PROBAST | Wolff et al., 2019 | Risk-of-bias assessment for prediction model studies | Evaluation / Publication | Overall risk-of-bias rating (low, high, unclear) across four domains: participants, predictors, outcome, analysis |
| STANDING Together | International consortium, launched Sept 2022 | Develop recommendations for dataset composition and reporting standards | Data collection / Publication | Standards for documenting dataset diversity, intended use, and population characteristics |
| Algorithmic Impact Assessment (AIA) | Various (e.g., Government of Canada, 2019) | Pre-deployment impact assessment covering bias, transparency, and accountability | Pre-deployment | Impact level rating and mitigation plan |
| FDA SaMD Action Plan | FDA, January 2021 | Regulatory framework emphasizing bias identification and mitigation throughout the product lifecycle | All stages | Guidance on predetermined change control plans and transparency |
PROBAST (Prediction model Risk Of Bias ASsessment Tool) is a widely used framework for evaluating the risk of bias in studies that develop or validate clinical prediction models. It assesses four domains: participants, predictors, outcome, and analysis. While PROBAST is designed for evaluating published research rather than auditing datasets directly, it provides a structured way to assess whether a model study is likely to produce biased results.
The STANDING Together initiative (launched September 2022) addresses a critical gap: the lack of standards for documenting dataset composition and diversity. Its recommendations aim to ensure that datasets used for clinical AI are described in sufficient detail — including population demographics, data collection methods, and intended use — so that downstream users can assess whether the dataset is appropriate for their target population.
Mitigation Methods by Pipeline Stage
No single mitigation method is sufficient to address all bias sources. Effective bias management requires a stage-appropriate combination of strategies applied across the pipeline. The following table organizes mitigation methods by where they intervene, with specific techniques and their primary use cases.
| Category | Method | Description | Best For |
|---|---|---|---|
| Pre-processing | SMOTE (Synthetic Minority Over-sampling Technique) | Generates synthetic samples for underrepresented classes | Imbalanced datasets in classification tasks |
| Pre-processing | ADASYN (Adaptive Synthetic Sampling) | Adaptively generates synthetic samples for harder-to-learn minority examples | Imbalanced datasets with class overlap |
| Pre-processing | Data augmentation | Creates modified versions of existing data (rotation, cropping, color adjustment) | Medical imaging datasets with limited diversity |
| Pre-processing | Imputation | Fills missing values using statistical or model-based methods | EHR data with nonrandomly missing fields |
| Pre-processing | SDoH capture via NLP/LLMs | Extracts social determinants of health from unstructured clinical notes | Datasets lacking structured SDoH fields |
| Pre-processing | Expert consensus labeling | Uses multiple annotators and reconciliation to reduce label bias | Subjective labeling tasks (e.g., pathology grading) |
| Pre-processing | Replace race correction with social deprivation indices | Substitutes race-based adjustments with area-level deprivation measures | Clinical algorithms historically using race correction (e.g., eGFR, AHA PREVENT Equations) |
| In-processing | Adversarial debiasing | Trains a model to predict the target while an adversary tries to predict the protected attribute | When protected attributes are available in training data |
| In-processing | Fairness constraints | Adds constraints to the optimization objective to enforce fairness metrics | When specific fairness criteria (e.g., equalized odds) are required |
| In-processing | Prejudice regularization | Adds a regularization term that penalizes reliance on protected attributes | When you want to reduce model sensitivity to sensitive features |
| In-processing | TWIX method | Requires model to predict importance of input segments (e.g., video clips) for skill assessment | Surgical AI and other video-based assessments; improved SAIS model performance for disadvantaged surgeon sub-cohorts (npj Digital Medicine, 2023) |
| Post-processing | Calibration | Adjusts model output probabilities to match observed frequencies | When model confidence scores are miscalibrated for subgroups |
| Post-processing | Threshold tuning | Adjusts decision thresholds to achieve parity in false positive or false negative rates across groups | Deployment-stage bias correction; used by NYC Health + Hospitals |
| Post-processing | Continuous monitoring with dashboards | Tracks subgroup performance metrics over time and alerts to drift | Post-deployment surveillance |
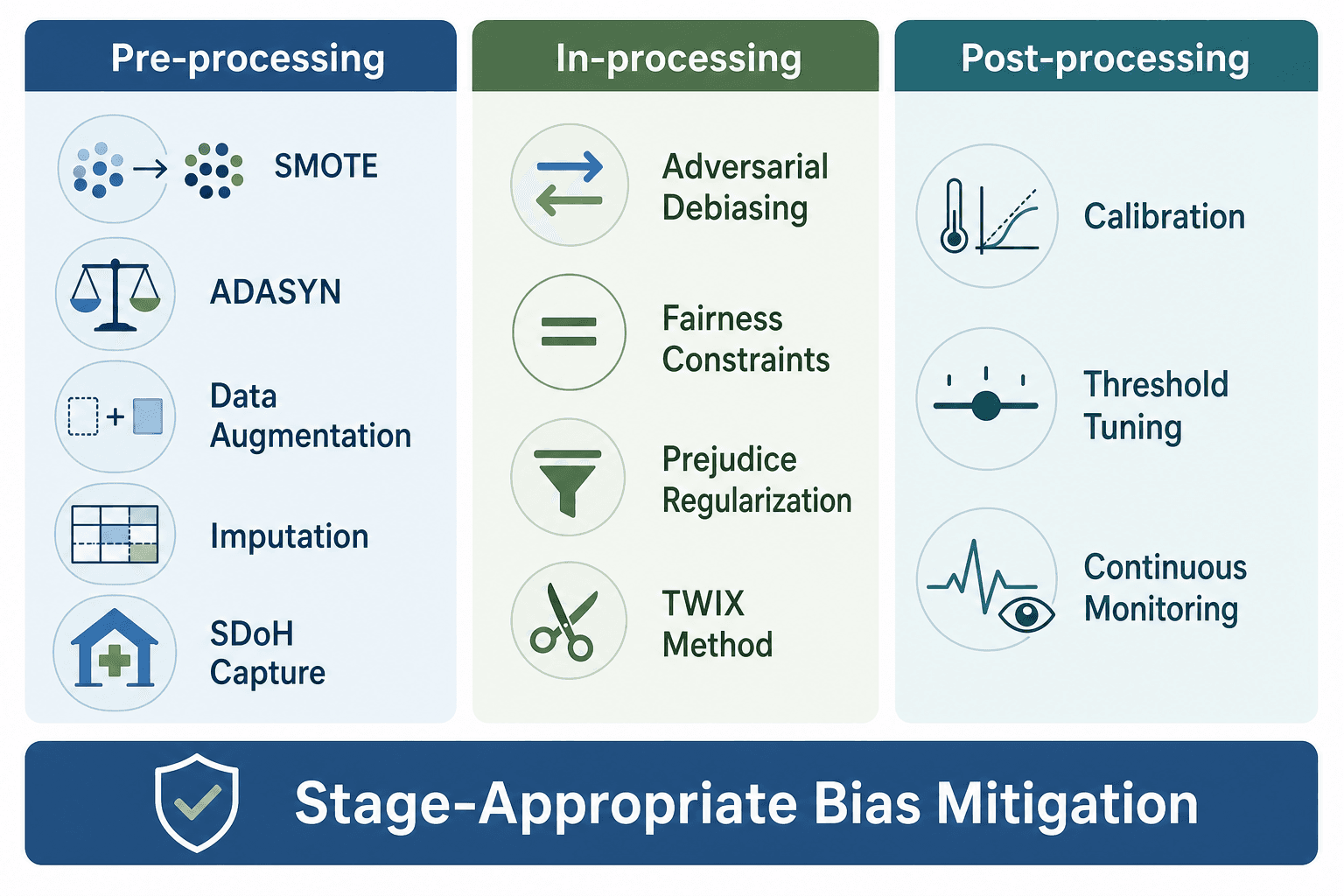
The TWIX method, developed by Kiyasseh et al. and discussed in Mittermaier, Raza, and Kvedar (2023), is a notable example of an in-processing technique designed for a specific clinical context. TWIX is an add-on application that mitigates bias by requiring the model to predict the importance of video clips used to assess surgical skill. It improved the SAIS model's performance both for disadvantaged surgeon sub-cohorts and for overall skill assessment, demonstrating that targeted in-processing methods can address bias without sacrificing overall accuracy.
The Regulatory Landscape: FDA and EU AI Act
Regulatory expectations for bias management in clinical AI are rapidly evolving. The FDA's AI/ML SaMD Action Plan (January 2021) explicitly emphasizes bias identification and mitigation as a key component of the regulatory framework. The agency's Good Machine Learning Practice (GMLP) draft guidance (January 2025) further elaborates on expectations for bias management throughout the product lifecycle, including dataset auditing, model validation across subgroups, and post-market monitoring.
The G-AUDIT framework's co-development with the FDA CDRH signals the agency's interest in quantitative, modality-agnostic auditing tools that can be applied consistently across different types of AI devices. This is a significant development: rather than relying on qualitative assessments or institution-specific checklists, the FDA is supporting the development of standardized, measurable auditing methods.
The European Union's AI Act, which entered into force in 2024, classifies medical AI systems as high-risk and imposes requirements for bias detection, transparency, and human oversight. For clinical AI developers and deployers operating in or serving the EU market, compliance with the AI Act's bias management provisions is mandatory. The Act requires that high-risk AI systems be tested for bias across the intended population and that mitigation measures be documented and maintained throughout the system's lifecycle.
The WHO's ethics and governance guidance for AI in healthcare (2021) provides an additional layer of international consensus. Its six core principles — protecting autonomy, promoting human well-being and safety, ensuring transparency, fostering accountability, ensuring inclusiveness and equity, and promoting AI that is responsive and sustainable — directly inform bias management expectations. While the WHO guidance is not legally binding, it shapes the normative environment in which clinical AI is developed and deployed globally.
Practical Recommendations for Healthcare Organizations
Translating the frameworks and methods described above into organizational practice requires a structured approach. The following recommendations are drawn from the 2025 practical guide by Censinet and the broader literature on algorithmic bias management.
- Assemble cross-functional AI risk teams. Include patients, clinicians, data scientists, ethicists, and legal/compliance representatives. Bias detection is not solely a technical problem — it requires clinical context, ethical reasoning, and regulatory awareness.
- Document AI use cases and testing scope. For each AI tool, specify the intended population, clinical setting, and decision context. This documentation is the foundation for selecting appropriate audit frameworks and fairness metrics.
- Select fairness metrics aligned with your use case. Common metrics include demographic parity (equal prediction rates across groups), equalized odds (equal true positive and false positive rates), equal opportunity (equal true positive rates), and predictive parity (equal positive predictive values). No single metric is universally appropriate — the choice depends on the clinical context and the specific harm you are trying to prevent.
- Integrate audit frameworks into procurement and deployment workflows. Require vendors to provide G-AUDIT or equivalent dataset audit results, PROBAST assessments for published evidence, and documentation of mitigation strategies. The STANDING Together standards can be used to evaluate dataset diversity claims.
- Establish continuous monitoring with human-in-the-loop review. Post-deployment monitoring should track subgroup performance metrics over time and flag drift. Dashboards should display real-time metrics and trigger alerts when performance falls below predefined thresholds. Human reviewers should investigate alerts and determine whether threshold adjustments, retraining, or recall is needed.
- Use interpretability tools (SHAP, LIME) to understand model behavior. These tools can help identify which features drive predictions for specific subgroups, revealing potential shortcut learning or unexpected bias sources.
The NYC Health + Hospitals case study provides a real-world example of how these recommendations can be implemented in practice. The health system applied post-processing threshold adjustment to correct for disparities in a clinical AI model, combined with continuous governance and human-in-the-loop review. While that case study focuses on a single post-processing technique, it demonstrates the broader principle that bias management is an ongoing operational commitment, not a one-time pre-deployment check.
Algorithmic bias in clinical AI is a lifecycle issue that demands lifecycle solutions. By understanding the taxonomy of bias sources, applying appropriate audit frameworks at each stage, selecting stage-specific mitigation methods, and building organizational governance structures, healthcare organizations can move from reactive bias detection to proactive bias management. The regulatory landscape is moving in the same direction — toward standardized, auditable, and continuously monitored fairness in clinical AI. Organizations that invest in these capabilities now will be better positioned to deploy AI tools that are not only accurate but equitable.
Comments
Join the discussion with an anonymous comment.