The Promise and the Gap: AI in Digital Pathology
The application of artificial intelligence to whole slide images (WSIs) has generated considerable enthusiasm in pathology. Published studies routinely report diagnostic accuracy figures above 90%, suggesting that deep learning models can detect, grade, and classify cancer from digitized tissue sections with near-human or even super-human performance. For laboratory directors and pathologists evaluating whether to invest in these tools, the headline numbers are compelling.
But a closer examination of the evidence base reveals a more complicated picture. The same literature that reports pooled sensitivity of 96.3% also shows that 99% of studies carry significant risk of bias, and fewer than half of commercially available products have been validated on data from outside the development site. This article provides an evidence-quality critique for clinical decision-makers — not a technology overview — by examining what the published literature actually supports and where the gaps remain.
Scale of the Evidence Base: 100 Studies, 152,000+ Whole Slide Images
The most comprehensive synthesis of AI diagnostic accuracy in digital pathology to date is the systematic review and meta-analysis by McGenity and colleagues, published in 2024. The review identified 100 studies meeting inclusion criteria, of which 48 provided sufficient data for meta-analysis. In total, these studies analyzed over 152,000 whole slide images drawn from multiple countries, covering a range of cancer types and organ systems.
The scope of the evidence is summarized below:
| Metric | Value |
|---|---|
| Studies included in systematic review | 100 |
| Studies included in meta-analysis | 48 |
| Total whole slide images analyzed | 152,000+ |
| Geographic scope | Multiple countries (predominantly high-income) |
| Cancer types covered | Multiple (GI, uropathology, breast, others) |
| Studies using only 1–2 data sources | Majority |
The scale of this evidence base is substantial, but the concentration of data sources is a concern. The majority of studies drew from only one or two institutional datasets, which limits generalizability and raises questions about how well these models would perform on slides from different scanners, staining protocols, or patient populations.
Pooled Diagnostic Accuracy: Sensitivity and Specificity by Subspecialty
Across all disease types, the meta-analysis reported a pooled mean sensitivity of 96.3% (95% CI 94.1–97.7) and a pooled mean specificity of 93.3% (95% CI 90.5–95.4). These figures are impressive on their face and have been widely cited as evidence that AI is ready for clinical deployment in pathology.
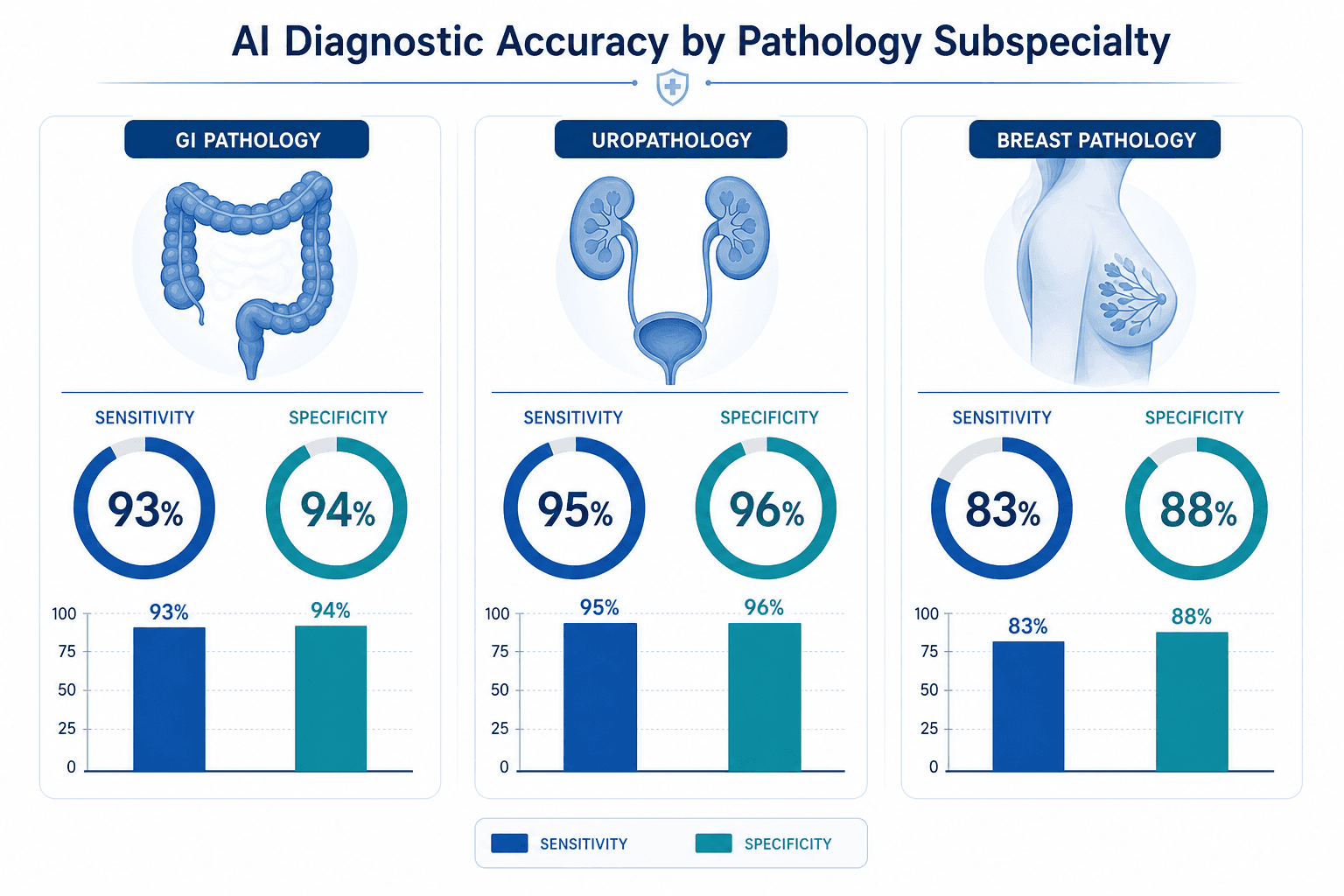
However, performance varied significantly by subspecialty. The table below breaks down the pooled sensitivity and specificity for the three most-studied organ systems:
| Subspecialty | Pooled Sensitivity | Pooled Specificity |
|---|---|---|
| Gastrointestinal pathology | 93% | 94% |
| Uropathology | 95% | 96% |
| Breast pathology | 83% | 88% |
The lower performance in breast pathology (sensitivity 83%, specificity 88%) is notable. Breast cancer diagnosis involves nuanced morphological features, and the heterogeneity of breast tissue — including variable stromal patterns, ductal vs. lobular subtypes, and the presence of in situ vs. invasive components — may pose greater challenges for current AI models. This subspecialty-specific variation underscores the importance of evaluating AI tools within their intended clinical context rather than relying on aggregate metrics.
An additional finding from the meta-analysis is that performance was higher in studies that included external validation. Studies with external validation achieved a pooled sensitivity of 95% and specificity of 92%, compared to 91% and 87% in studies without external validation. This 4–5 percentage point gap suggests that models tested only on internal data may overestimate their real-world performance.
The Risk of Bias Problem: 99% of Studies Affected
The most concerning finding from the McGenity review is not about accuracy — it is about the quality of the evidence underlying those accuracy figures. Of the 100 studies included in the systematic review, 99% had at least one domain rated at high or unclear risk of bias. This is not a minor methodological concern; it fundamentally limits the confidence that can be placed in the pooled accuracy estimates.
Common sources of bias identified across the studies include:
- Single-center data collection: Most studies used slides from a single institution, often the same institution where the model was developed, creating a risk of overfitting to site-specific staining and scanning characteristics.
- Small sample sizes: Many studies included fewer than 500 WSIs, which is insufficient to estimate diagnostic accuracy with narrow confidence intervals, particularly for rare cancer subtypes.
- Lack of blinding: In several studies, the pathologists providing the reference standard were aware of the AI model's output, introducing potential confirmation bias.
- Inadequate reference standards: Some studies used pathology reports or existing clinical diagnoses as the ground truth rather than independent re-review by a panel of expert pathologists.
- Selective reporting: Studies were more likely to report favorable results for the specific cancer type or task the model was designed to address, while less favorable results for secondary endpoints were often omitted.
The implications of this widespread bias are straightforward: the true diagnostic accuracy of AI models in real-world clinical settings may be meaningfully lower than the pooled figures suggest. A model that achieves 96% sensitivity on a curated, single-institution dataset may perform substantially worse when deployed on slides from a different scanner, a different staining protocol, or a patient population with different demographic characteristics.

The External Validation Gap for Commercial Products
The risk-of-bias problem in the academic literature is compounded by a validation gap in the commercial products that pathologists and laboratory directors are being asked to adopt. A 2024 review by Matthews and colleagues identified 26 AI-based products for H&E digital pathology on the European Economic Area and Great Britain markets. The findings on the state of evidence for these products are sobering.
| Evidence Category | Number of Products (n=26) | Percentage |
|---|---|---|
| Peer-reviewed internal validation study available | 10 | 38% |
| Peer-reviewed external validation study available | 11 | 42% |
| Tested on UK data | 2 | 8% |
| Publications independent of vendor | 4 of 23 publications | 17% |
Several observations stand out. First, fewer than half of the products had any peer-reviewed external validation — meaning that for the majority of commercially available AI tools, there is no published evidence that they perform adequately on data from a different institution. Second, only 2 of 26 products had been tested on UK data, raising questions about generalizability to health systems with different demographic profiles and diagnostic practices. Third, of the 23 publications identified for these products, only 4 (17%) were independent of the vendor, suggesting that the available evidence is predominantly generated by the companies selling the tools.
It is also worth noting that 24 of the 26 products had been approved under the European In Vitro Diagnostic Directive (IVDD) self-certification route, which does not require submission of clinical performance data to a regulatory body. This means that the products reached the market with no independent assessment of their diagnostic accuracy.
Regulatory Landscape: FDA-Cleared and CE-Marked Solutions
The regulatory environment for AI in pathology has evolved significantly since the FDA permitted marketing of the first whole slide imaging system for primary diagnosis — the Philips IntelliSite Pathology Solution — through the de novo pathway in April 2017. That decision was based on a clinical study of approximately 2,000 surgical pathology cases from multiple anatomic sites, demonstrating that clinical interpretations based on digital images were comparable to those using glass slides.
Since then, the number of FDA-authorized AI solutions for pathology has grown slowly. A 2026 review by Matzko and colleagues identified only approximately four FDA-approved whole slide image cancer solutions for a narrow range of applications. Key regulatory milestones include:
- Philips IntelliSite Pathology Solution (2017): First WSI system cleared for primary diagnosis via de novo pathway.
- Leica Aperio AT2 DX (2019): Second WSI system cleared for primary diagnosis.
- Paige Prostate (2021): First AI-based pathology tool for prostate cancer detection, cleared via 510(k) pathway.
- Paige PanCancer Detect (April 2025): Received FDA Breakthrough Device designation for pan-cancer detection.
- Modella AI PathChat DX (January 2025): Received FDA Breakthrough Device designation for AI-powered pathology chat.
It is important to distinguish between regulatory clearance and proven clinical efficacy. FDA 510(k) clearance, for example, requires demonstration of substantial equivalence to a predicate device — not independent evidence of clinical benefit. Breakthrough Device designation accelerates development and review but does not constitute approval. Laboratory directors should not interpret regulatory status as a substitute for rigorous local validation.
Implications for Clinical Deployment: What the Evidence Actually Supports
Given the evidence-quality critique presented above, what can pathologists and laboratory directors reasonably conclude about the readiness of AI for clinical deployment? The answer depends on the specific use case, the quality of available validation data, and the institution's tolerance for diagnostic error.
For well-validated use cases in gastrointestinal and uropathology, where pooled sensitivity and specificity exceed 93%, and where multiple studies with external validation have been published, the evidence supports cautious adoption — provided that the institution conducts its own local validation study before full deployment. The higher performance in studies with external validation (sensitivity 95%, specificity 92%) suggests that models can generalize when properly developed, but this generalization must be confirmed locally.
For breast pathology, where pooled sensitivity drops to 83% and specificity to 88%, the evidence base is weaker. Laboratory directors should be particularly cautious about deploying AI for breast cancer diagnosis without robust local validation and clear protocols for when the AI's output should be overridden by human review.
Across all use cases, the following principles should guide deployment decisions:
- Require external validation: Do not adopt a product that has not been validated on data from at least one institution other than the development site.
- Conduct local validation: Even for products with strong external validation, run a local study using your own slides, scanners, and staining protocols to confirm performance.
- Monitor for drift: Model performance can degrade over time as staining protocols, scanner settings, or patient populations change. Implement ongoing performance monitoring.
- Plan for the edge cases: AI models may perform poorly on rare cancer subtypes, unusual morphologies, or low-quality slides. Have clear escalation pathways for cases where the AI is uncertain.
- Do not conflate regulatory clearance with clinical efficacy: FDA clearance or CE marking indicates that a product meets regulatory requirements for market access, not that it has been proven to improve patient outcomes.
The Path Forward: STARD-AI, Multi-Source Datasets, and Independent Validation
Closing the gap between published promise and real-world evidence will require systematic improvements in how AI pathology studies are designed, conducted, and reported. The following methodological advances are urgently needed:
- Adoption of STARD-AI reporting guidelines: The STARD-AI (Standards for Reporting of Diagnostic Accuracy Studies — AI) extension provides a framework for transparent reporting of AI diagnostic accuracy studies. Widespread adoption would reduce the risk of selective reporting and improve comparability across studies.
- Multi-source, diverse datasets: The majority of current studies use data from one or two institutions. Future studies should draw from multiple institutions across different geographic regions, with diverse patient populations, to assess generalizability.
- Independent validation studies: Only 17% of publications for CE-marked products are independent of vendors. Funding agencies and journals should prioritize independent validation studies that are not sponsored by the companies developing the AI tools.
- Prospective clinical trials: Most published studies are retrospective. Prospective trials, in which the AI is used in real-time clinical workflows and its impact on diagnostic accuracy, turnaround time, and patient outcomes is measured, are needed to establish clinical utility.
- Standardized performance benchmarks: The field would benefit from publicly available benchmark datasets and standardized evaluation protocols, similar to those used in radiology AI (e.g., the RSNA challenge datasets).
The path forward is not to abandon AI in pathology — the technology has genuine potential to improve diagnostic accuracy, reduce turnaround times, and address workforce shortages. But that potential will only be realized if the evidence base is strengthened to a level that supports confident clinical decision-making. For now, the responsible position is one of cautious optimism: the pooled accuracy figures are promising, but the widespread risk of bias and limited external validation mean that every deployment should be accompanied by rigorous local evaluation and ongoing performance monitoring.
As the field matures, the distinction between regulatory clearance and clinical evidence will become increasingly important. Laboratory directors and pathologists who invest the time to understand the evidence base — and its limitations — will be best positioned to make informed decisions about when and how to integrate AI into their practice.
Comments
Join the discussion with an anonymous comment.