The Medical Coding Problem: Scale, Error Rates, and Cost
Medical coding is the process of translating clinical documentation — physician notes, lab results, procedure reports — into standardized alphanumeric codes. These codes (ICD-10-CM for diagnoses, CPT for procedures, HCPCS for supplies and services) drive reimbursement, population health analytics, clinical research, and regulatory reporting. The scale of the task is staggering: the current ICD-10-CM code set contains over 74,000 codes, each with precise inclusion and exclusion rules, hierarchical relationships, and documentation requirements.
Manual coding is error-prone. Published studies consistently report error rates ranging from 10% to 20% in real-world settings, depending on the clinical specialty and coding complexity. These errors carry real consequences: denied claims, delayed reimbursement, audit risk, and inaccurate data for quality measurement and research. The financial impact is substantial. Industry estimates place the annual cost of coding inaccuracies in the U.S. healthcare system at approximately $18.2 billion, encompassing rework, penalties, and lost revenue.
Given these pressures, health systems have been exploring automation for decades. Early computer-assisted coding (CAC) tools used rules-based engines and natural language processing (NLP) to suggest codes, but their accuracy plateaued. The emergence of large language models (LLMs) — GPT-4, Gemini, Llama — raised the possibility of a step-change improvement. But as the evidence from 2024 and 2025 makes clear, the gap between promise and proven performance remains wide, and the path to reliable deployment requires more than just plugging in a foundation model.
The Mount Sinai Benchmark: How Base LLMs Perform on Medical Code Querying
In April 2024, researchers at the Icahn School of Medicine at Mount Sinai published a landmark study in NEJM AI that established the first rigorous benchmark for LLM performance on medical code querying. The study evaluated four models — GPT-4, GPT-3.5, Gemini Pro, and Llama-2-70b Chat — across more than 27,000 unique codes spanning three code systems: 7,697 ICD-9-CM codes, 15,950 ICD-10-CM codes, and 3,673 CPT codes. The task was straightforward: given a structured description of a diagnosis or procedure, the model had to return the correct code.
The results were sobering. No model exceeded 50% exact-match accuracy on any code set. GPT-4 (November 2023 version) performed best, achieving 45.9% on ICD-9-CM, 33.9% on ICD-10-CM, and 49.8% on CPT. Gemini Pro scored lower across all categories, and Llama-2-70b Chat brought up the rear with exact-match rates of 1.2% (ICD-9-CM), 1.5% (ICD-10-CM), and 2.6% (CPT).
| Model | ICD-9-CM Exact Match | ICD-10-CM Exact Match | CPT Exact Match |
|---|---|---|---|
| GPT-4 (Nov 2023) | 45.9% | 33.9% | 49.8% |
| GPT-3.5 | ~30% (estimated from figure) | ~18% (estimated from figure) | ~35% (estimated from figure) |
| Gemini Pro | ~15% (estimated from figure) | ~10% (estimated from figure) | ~20% (estimated from figure) |
| Llama-2-70b Chat | 1.2% | 1.5% | 2.6% |
The study also analyzed the types of errors the models made. GPT-4 generated the highest proportion of "equivalent" codes — codes that were clinically related but not exact matches (7.0% for ICD-9-CM, 10.9% for ICD-10-CM). GPT-3.5 produced the most "generalized" codes — non-specific codes that captured a broader category than the description warranted (29.9% for ICD-9-CM, 18.5% for ICD-10-CM). Llama-2-70b Chat fabricated codes at an alarming rate: 45.9% of its ICD-9-CM outputs were entirely invented codes that did not exist in the code set.
Factors associated with higher accuracy included shorter code descriptions, higher code frequency in electronic health records, and shorter code lengths. These findings suggest that base LLMs perform better on common, simple codes and struggle with the long, hierarchical, and rare codes that make up the bulk of the medical coding challenge.
"This study sheds light on the current capabilities and challenges of AI in health care, emphasizing the need for careful consideration and additional refinement prior to widespread adoption." — Girish Nadkarni, co-senior author, Mount Sinai (press release, April 22, 2024)
Why Base LLMs Fail at Medical Coding
The poor performance of base LLMs on medical coding is not a surprise to researchers familiar with the limitations of foundation models. Several structural factors explain why these models, despite their impressive performance on general knowledge tasks, struggle with this specific domain.
- Tokenization limitations. Medical code descriptions are often long and hierarchical. An ICD-10-CM code like "E11.9" (Type 2 diabetes mellitus without complications) has a short description, but many codes have descriptions exceeding 100 characters. LLMs tokenize input text into fixed-size tokens, and long, unfamiliar code descriptions can exceed the model's effective context window or be fragmented in ways that lose meaning.
- Lack of domain-specific knowledge. Base LLMs are trained on general internet text, not on the structured, rule-based knowledge that human coders learn through certification programs (e.g., AAPC, AHIMA). They do not inherently understand coding conventions like "excludes1" vs. "excludes2" notes, sequencing rules, or the distinction between a principal diagnosis and a secondary diagnosis.
- Code fabrication (hallucination). As the Mount Sinai study showed, Llama-2-70b Chat fabricated codes 45.9% of the time on ICD-9-CM queries. Even GPT-4, the best performer, fabricated codes at a rate of 2.9%. These are not near-misses — they are codes that do not exist in any code set, which would be immediately rejected by claims processing systems.
- Overgeneralization to non-specific codes. GPT-3.5 frequently defaulted to non-specific codes (e.g., "unspecified" codes) when the description called for a precise code. This is a clinically dangerous pattern: using unspecified codes can mask the true clinical picture and lead to inaccurate risk adjustment and reimbursement.
The Fine-Tuning Breakthrough: 97%+ on Structured Descriptions
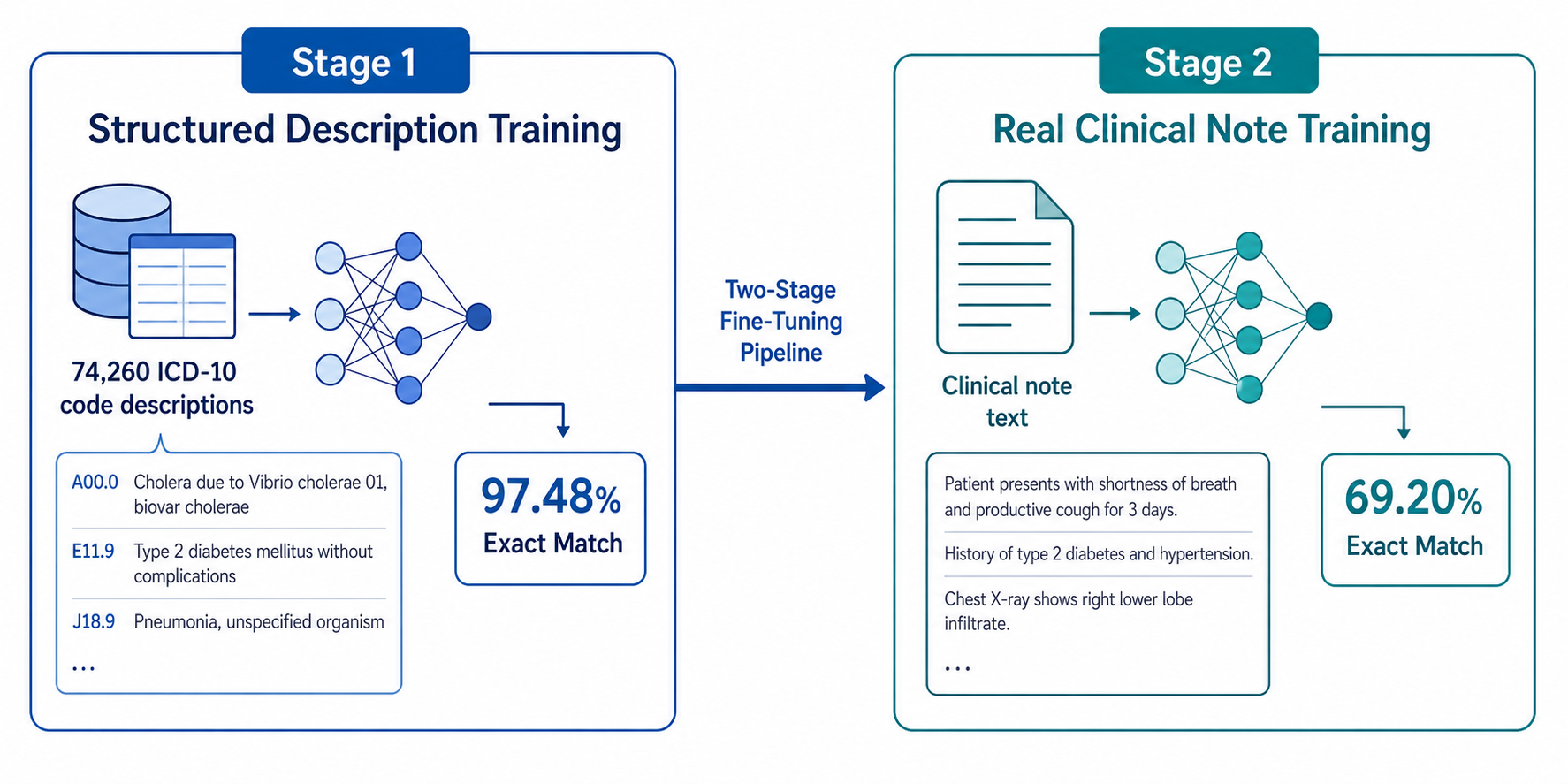
If base LLMs are poor medical coders, can they be trained to become good ones? A study published in npj Health Systems in May 2025 by Hou et al. provides the clearest answer to date: yes, but with important caveats.
The researchers employed a two-stage fine-tuning approach. In the first stage, they fine-tuned several base models (GPT-4o mini, Llama-3.2-1B, Llama-3.2-3B) on the complete set of 74,260 ICD-10-CM codes, using structured descriptions as input. The results were dramatic. Exact-match accuracy on structured descriptions jumped from less than 1% (base model performance) to 97.48% for GPT-4o mini and 98.80–98.83% for the Llama models.
The second stage focused on handling complex variations — descriptions that included multiple conditions, anatomical modifiers, or temporal qualifiers. Enhanced fine-tuning on GPT-4o mini improved performance on multiple-condition descriptions from 10.9% to 94.07%. For Llama-3.2-1B, the improvement was even starker: from 3.85% to 98.04%.
| Model | Base Accuracy (Structured) | Fine-Tuned Accuracy (Structured) | Multiple Conditions (Before) | Multiple Conditions (After) |
|---|---|---|---|---|
| GPT-4o mini | <1% | 97.48% | 10.9% | 94.07% |
| Llama-3.2-1B | <1% | 98.80% | 3.85% | 98.04% |
| Llama-3.2-3B | <1% | 98.83% | Not reported | Not reported |

These results demonstrate that domain-specific fine-tuning can effectively teach LLMs the mapping between clinical descriptions and ICD-10 codes. The models are not just memorizing codes — they are learning the underlying structure of the code set, including hierarchical relationships and coding conventions. This is a fundamentally different capability from what base LLMs exhibit.
From Structured Descriptions to Real Clinical Notes: The Performance Gap
The 97%+ accuracy on structured descriptions is impressive, but structured descriptions are not what medical coders work with. Real clinical notes are messy: they contain abbreviations, negations, uncertain language, irrelevant information, and implicit clinical reasoning. The gap between controlled benchmarks and real-world performance is the critical test for any AI coding system.
Hou et al. addressed this directly by evaluating their best-performing fine-tuned model (Llama-3.2-1B) on 10,000 clinical notes from the MIMIC-IV database. The results: 69.20% top-1 exact-match accuracy and 87.16% category-level match accuracy. Category-level match means the model assigned the correct three-digit category (e.g., E11 for Type 2 diabetes) but not necessarily the correct full code (e.g., E11.9 vs. E11.21).
This 28-percentage-point drop from structured descriptions to real notes is the single most important finding for anyone evaluating AI coding tools. It means that even the best fine-tuned models, when faced with the complexity of actual clinical documentation, still make errors on roughly 3 out of 10 codes. For a health system processing millions of encounters per year, that error rate translates into a substantial volume of incorrect codes.
Industry Approaches: Knowledge Layers, RAG, and Hybrid Systems
The gap between fine-tuned model performance and production-ready accuracy has led vendors to develop hybrid approaches that combine LLMs with structured clinical knowledge. These systems do not rely on the LLM alone — they augment it with external knowledge bases, retrieval-augmented generation (RAG), and rule-based validation layers.
IMO Health has published the most detailed account of this approach. Their system combines a rich clinical terminology layer (covering 24 active domains with millions of concepts, used by 89% of U.S. physicians), RAG, prompt engineering with 22 summarized coding rules, and fine-tuning. In a head-to-head test, the top out-of-the-box LLM achieved 55% ICD-10-CM accuracy. IMO Health's knowledge-layer solution reached 92% accuracy. Notably, the system reduced LLM usage to 25.1% of input terms while increasing dataset accuracy from 82.9% to 90.0% — suggesting that the knowledge layer is doing most of the work, with the LLM handling only the most ambiguous cases.
| Approach | Reported Accuracy | Key Components | Source Type |
|---|---|---|---|
| Base LLM (out-of-the-box) | ~34% (ICD-10-CM) | No domain adaptation | Peer-reviewed (Mount Sinai / NEJM AI) |
| Fine-tuned LLM (structured descriptions) | 97.48% | Two-stage fine-tuning on full ICD-10 set | Peer-reviewed (Hou et al., npj Health Systems) |
| Fine-tuned LLM (real clinical notes) | 69.20% | Fine-tuning + MIMIC-IV notes | Peer-reviewed (Hou et al., npj Health Systems) |
| Knowledge-layer + RAG + fine-tuning | ~92% | Clinical terminology, RAG, prompt engineering, fine-tuning | Vendor-published (IMO Health) |
Other vendors are pursuing similar strategies. RAG-based solutions retrieve relevant coding guidelines and historical examples from a knowledge base before generating a code, reducing the model's reliance on its internal (and often incomplete) knowledge. Hybrid human-AI workflows route high-confidence codes to automated processing and flag low-confidence codes for human review. These approaches acknowledge a fundamental reality: current AI coding systems are not reliable enough to operate without human oversight.
Persistent Limitations: What the Errors Tell Us
The Hou et al. study included a detailed error analysis of 535 incorrect codes generated by their fine-tuned model on real clinical notes. The breakdown reveals four distinct failure modes, each with different implications for deployment.

- Information absence (42%). The clinical note simply did not contain the information needed to assign the correct code. This is not a model failure per se — it reflects incomplete documentation. However, the model cannot distinguish between "information not present" and "information present but not coded," which means it may generate plausible-sounding codes based on insufficient evidence.
- Diagnostic criteria insufficiency (38%). The note mentioned a condition but did not include enough detail to determine the correct code. For example, a note might say "patient has diabetes" without specifying type, complications, or control status. Human coders would query the provider; AI models cannot (yet) do this effectively.
- Coding rule violations (12%). The model assigned a code that violated official coding guidelines — for example, coding a symptom when a definitive diagnosis was documented, or failing to apply the "excludes1" note that prevents coding two mutually exclusive conditions together. These errors require deep knowledge of coding conventions that fine-tuning alone may not fully instill.
- Clinical context misinterpretation (8%). The model misunderstood the clinical meaning of the text. This category includes errors like coding a family history as a current diagnosis, or misinterpreting a negated statement ("no evidence of pneumonia") as a positive finding. These are the most clinically dangerous errors because they can lead to incorrect treatment decisions if the coded data is used for clinical decision support.
The distribution of errors is instructive. The two largest categories — information absence and diagnostic criteria insufficiency — are not model problems in the traditional sense. They are documentation problems. An AI coding system cannot code what is not documented. This means that even a perfect AI coding system would still produce errors if the underlying clinical documentation is incomplete or ambiguous. Improving AI coding accuracy therefore requires not just better models, but better clinical documentation practices.
Implications for Deployment Readiness and Human Oversight
The evidence from 2024–2025 paints a clear picture of where AI medical coding stands and where it does not. The field has made remarkable progress in a short time: from base LLMs scoring below 50% to fine-tuned models exceeding 97% on structured tasks. But the transition from structured benchmarks to real clinical notes reveals a persistent performance gap that no amount of fine-tuning on structured data alone can close.
For health IT decision-makers, the implications are straightforward. Current AI coding systems are best positioned as assistive tools that augment human coders rather than replace them. A realistic deployment model might involve:
- AI-generated code suggestions presented to human coders for validation, with confidence scores and audit trails.
- Automated coding of high-confidence cases (e.g., routine encounters with clear documentation) with human review of the remainder.
- Continuous monitoring of model performance across different clinical specialties, documentation styles, and patient populations to detect drift or bias.
- Integration with clinical documentation improvement (CDI) programs to address the information absence and diagnostic criteria insufficiency errors that account for 80% of remaining mistakes.
The regulatory landscape for AI medical coding tools remains undefined. As of mid-2026, no FDA-cleared AI medical coding devices have been identified. Most coding AI tools operate as administrative or software tools rather than regulated medical devices, though this boundary may shift as the FDA continues to refine its approach to AI/ML-enabled software. Health systems should verify the regulatory status of any coding AI tool they evaluate and understand the implications for liability and compliance.
Looking ahead, the trajectory is toward higher accuracy through continued fine-tuning on real clinical notes, integration of structured knowledge bases, and hybrid human-AI workflows. The 69.20% exact-match figure from Hou et al. is not a ceiling — it is a baseline that will likely improve as models are trained on larger and more diverse clinical datasets. But the remaining error categories, particularly those rooted in documentation quality and clinical context, will require solutions that go beyond model architecture.
Comments
Join the discussion with an anonymous comment.