

The Promise and the Peril: Why ML Diagnosis Can Widen Health Inequities
Machine learning diagnostic tools have demonstrated remarkable performance in controlled settings. A 2021 meta-analysis by Aggarwal et al. reviewing 503 studies reported area under the curve (AUC) values ranging from 0.87 to 1.0 across ophthalmology, respiratory imaging, and breast imaging — figures that suggest near-perfect accuracy in some applications. A 2025 meta-analysis by Takita et al. of 83 studies found that generative AI models achieved an overall pooled diagnostic accuracy of 52.1%, with top-tier models like GPT-4 and Claude 3 Opus performing comparably to non-expert physicians.
These aggregate numbers, however, mask a troubling pattern: the same tools frequently underperform for historically underserved populations. The root cause is not the algorithms themselves but the data used to train them. When training datasets lack diversity — when they overrepresent certain demographics and underrepresent others — the resulting models learn patterns that do not generalize equally across all patient groups.
The stakes are not theoretical. A 2019 study by Obermeyer et al. published in Science found that a widely used hospital algorithm systematically underestimated illness severity in Black patients, directly affecting resource allocation for millions. As of 2026, with the FDA having authorized over 1,300 AI medical devices and approximately 32% of U.S. adults reportedly using AI chatbots for health information according to a 2026 KFF survey, the urgency of addressing algorithmic bias has never been greater.
This article examines the mechanisms through which bias enters ML diagnostic systems, documents specific disparities across clinical specialties, analyzes the insufficiency of current FDA clearance processes in detecting these gaps, and outlines evidence-based mitigation strategies for clinicians, health equity researchers, and policy professionals.
Sources of Bias in ML Diagnostic Tools
Bias in ML diagnostic systems does not arise from a single cause. It emerges from at least four distinct mechanisms, each operating at a different point in the development and deployment pipeline. Understanding these mechanisms is a prerequisite for designing effective interventions.
Data Composition Bias
The most fundamental source of bias is the training data itself. If a dataset used to train a melanoma detection model contains 90% images of fair skin and 10% images of darker skin, the model will inevitably learn features that are more predictive for the majority group. This is not a failure of the algorithm — it is a failure of data collection. The problem is compounded by the fact that many publicly available medical imaging datasets originate from institutions serving predominantly white populations, creating a structural skew that propagates through the entire research ecosystem.
Algorithmic Amplification
Even when datasets are reasonably diverse, certain modeling choices can amplify existing disparities. A 2022 study by Maleki et al. quantitatively demonstrated how three methodological pitfalls — violation of the independence assumption (data leakage), use of inappropriate performance metrics, and batch effects — can produce dramatically overoptimistic results. In one example, a model trained on a batch effect dataset achieved an F1 score of 98.7% on internal testing but correctly classified only 3.86% of new healthy pediatric samples. When such models are deployed without rigorous external validation, disparities that were invisible during development become apparent in clinical practice.
Clinician Interaction Bias
ML diagnostic tools do not operate in isolation. They are used by clinicians whose own decision-making patterns may vary across patient populations. If a radiologist is more likely to override an AI recommendation for one demographic group than another, the effective performance of the system differs from its technical performance. This interaction effect is rarely measured in pre-market studies, yet it can substantially alter real-world outcomes.
Patient Access Bias
Healthcare access patterns create systematic differences in the data available for training. Patients who have regular access to advanced imaging are more likely to be represented in training datasets than those who face barriers to care. This means that populations with lower healthcare utilization — often the same populations that experience worse health outcomes — are underrepresented in the very data used to build diagnostic tools intended to serve them.
- Data composition bias: training datasets that underrepresent certain demographics
- Algorithmic amplification: methodological choices that magnify existing disparities
- Clinician interaction bias: differential human-AI interaction patterns across populations
- Patient access bias: differential data availability due to healthcare access patterns
Documented Diagnostic Disparities Across Specialties
The theoretical mechanisms described above are not hypothetical. Multiple peer-reviewed studies have documented measurable disparities in AI diagnostic performance across demographic groups. Three examples spanning different specialties illustrate the breadth of the problem.
Dermatology AI and Skin Tone Bias
Dermatological AI systems for melanoma detection have consistently shown lower accuracy on darker skin tones. The primary cause is straightforward: most publicly available dermatology image datasets are composed predominantly of images from fair-skinned patients. Lesions that appear as high-contrast, well-defined features on light skin may present as subtle, low-contrast variations on darker skin. A model trained primarily on the former will miss or misclassify the latter. This is not a marginal issue — melanoma mortality rates are already higher in Black and Hispanic populations in the United States, partly due to delayed diagnosis. An AI tool that performs worse for these groups risks widening an existing mortality gap.
Resource Allocation Algorithms and Racial Bias
The most widely cited example of algorithmic bias in healthcare comes from a 2019 study by Obermeyer et al. published in Science. The researchers analyzed a commercial algorithm used by hospitals and health systems to identify patients who would benefit from intensive care management programs. The algorithm systematically underestimated illness severity in Black patients relative to white patients with the same level of objective health needs. The root cause was that the algorithm used healthcare costs as a proxy for health needs — and because Black patients historically have lower healthcare spending due to access barriers, the algorithm concluded they were healthier than they actually were. This affected resource allocation for millions of patients.
Pathology AI and Demographic Performance Gaps
A 2025 study from Harvard researchers found that pathology AI models for cancer diagnosis performed unequally across demographic groups. While the specific performance metrics and demographic categories were not fully detailed in the available sources, the finding aligns with a broader pattern: models trained on homogeneous tissue sample datasets may not generalize to the histological variations present across different populations. This is particularly concerning for cancer diagnosis, where delayed or incorrect diagnosis has life-threatening consequences.
| Specialty | Documented Disparity | Key Source |
|---|---|---|
| Dermatology | Lower melanoma detection accuracy on darker skin | Multiple studies (training data imbalance) |
| Population health management | Algorithm underestimated illness severity in Black patients | Obermeyer et al., Science, 2019 |
| Pathology | Unequal cancer diagnosis performance across demographic groups | Harvard 2025 study |
The Regulatory Gap: What FDA Clearance Processes Miss
If biased training data is the root cause of diagnostic disparities, then regulatory oversight should serve as a safety net — catching these problems before devices reach clinical use. The available evidence suggests that current FDA clearance processes are not equipped to perform this function.
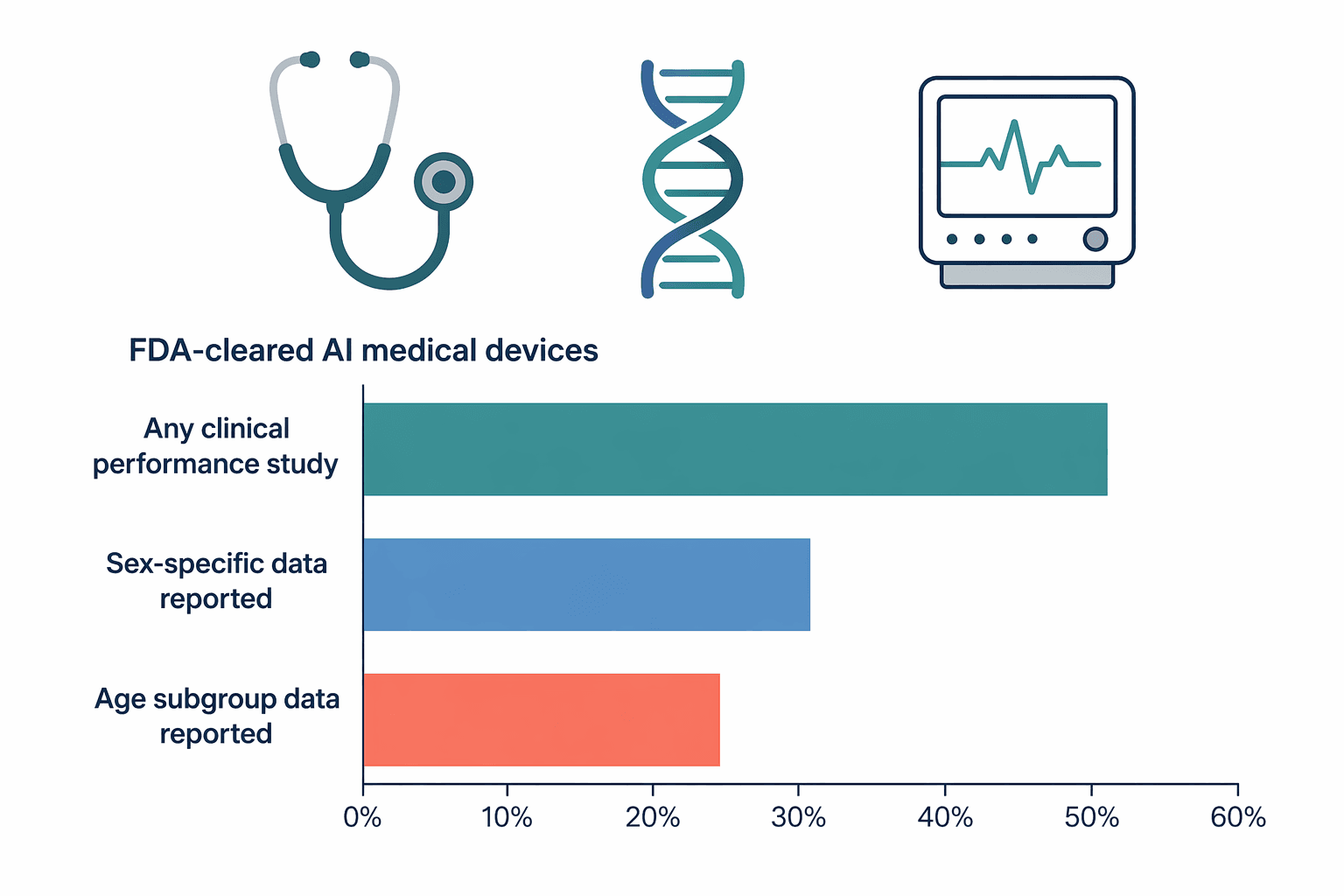
A 2025 study published in JAMA Network Open examined 903 FDA-approved AI medical devices and found that clinical performance studies were reported for only about half of them. Fewer than one-third provided sex-specific data, and only one-quarter addressed age-related subgroups. This means that for the majority of FDA-cleared AI diagnostic tools, there is no publicly available information about whether they perform equally well across men and women, or across different age groups.
A separate 2025 study in npj Digital Medicine by Singh et al. reviewed 1,016 FDA authorizations of AI/ML-enabled medical devices and found that nearly half did not describe the study design used for validation, and over half omitted the sample size. The study also noted that 84.4% of authorized devices use images as input, and 85.6% are for data analysis rather than generation. No authorized device used a large language model (LLM) as of the data cutoff in September 2024.
These findings point to a structural gap in the regulatory framework. The FDA does not currently mandate subgroup performance reporting as a condition of clearance. A device can receive 510(k) clearance or De Novo authorization without demonstrating that it performs equally well across racial, ethnic, sex, or age groups. As a result, disparities that could be detected during pre-market evaluation remain invisible until the device is deployed in diverse clinical settings — at which point the burden of detection falls on individual health systems and clinicians.
| Reporting Requirement | Percentage of Devices | Source |
|---|---|---|
| Any clinical performance study reported | ~50% | JAMA Network Open 2025 (n=903) |
| Sex-specific data reported | <33% | JAMA Network Open 2025 (n=903) |
| Age subgroup data reported | ~25% | JAMA Network Open 2025 (n=903) |
| Study design described | ~50% | npj Digital Medicine 2025 (n=1,016) |
| Sample size reported | <50% | npj Digital Medicine 2025 (n=1,016) |
Mitigation Strategies: From Data Collection to Deployment
Addressing algorithmic bias requires action at multiple stages of the ML lifecycle. No single intervention is sufficient, but a combination of strategies can substantially reduce the risk of diagnostic disparities.
Diverse, Representative Training Datasets
The most effective intervention is at the source: ensuring that training datasets reflect the demographic diversity of the populations in which the tool will be deployed. This requires intentional data collection strategies that oversample underrepresented groups, explicit demographic reporting in dataset documentation, and the use of standardized demographic categories that allow for meaningful subgroup analysis. Funding agencies and journal publishers can accelerate this shift by requiring demographic reporting as a condition of grant support or publication.
Pre-Deployment Fairness Audits
Before a diagnostic tool is deployed in a clinical setting, it should undergo a fairness audit that evaluates performance across predefined demographic subgroups. This audit should report stratified metrics — sensitivity, specificity, positive predictive value, and AUC — for each subgroup, not just aggregate performance. If disparities exceed a predefined threshold, the tool should not be deployed until the underlying cause is identified and addressed.
Explainable AI Techniques
Explainable AI methods can help surface potential bias by revealing which features a model is using to make decisions. If a model is relying on features that correlate with demographic characteristics — such as skin color in dermatology or hair texture in pathology — this can be detected and corrected. However, explainability is a tool, not a solution: it can flag potential problems but cannot by itself resolve the underlying data imbalances.
Federated Learning
Federated learning allows models to be trained across multiple institutions without centralizing sensitive patient data. This approach can improve demographic diversity by incorporating data from institutions that serve different populations, without requiring data to leave each institution's secure environment. While federated learning introduces technical challenges — including communication overhead and heterogeneous data distributions — it offers a practical pathway to more representative training without compromising privacy.

| Strategy | Stage of ML Lifecycle | Key Action |
|---|---|---|
| Diverse training datasets | Data collection | Oversample underrepresented groups; require demographic reporting |
| Fairness audits | Pre-deployment | Evaluate stratified performance metrics across subgroups |
| Explainable AI | Model development | Surface features correlated with demographic characteristics |
| Federated learning | Model training | Train across diverse institutions without centralizing data |
Policy Proposals and the Path Forward
The evidence reviewed in this article points to a clear conclusion: current regulatory frameworks are insufficient to ensure that ML diagnostic tools perform equitably across all patient populations. Closing this gap requires specific, enforceable policy changes.
- Mandatory subgroup performance reporting in FDA 510(k) and De Novo submissions, including stratified metrics by race, ethnicity, sex, and age group
- Standardized bias audit requirements before clearance, with predefined thresholds for acceptable performance gaps
- Post-market surveillance mandates that require ongoing demographic performance monitoring after deployment
- Alignment with international frameworks, including the EU AI Act's requirements for high-risk AI systems and WHO guidance on ethics and governance of AI in healthcare
- Transparency requirements for vendors to disclose training data composition, validation methods, and known limitations
These proposals are not radical. They are consistent with the FDA's own stated commitment to advancing health equity and with the broader movement toward algorithmic accountability in healthcare. The 2025 studies documenting the extent of reporting gaps provide an empirical basis for action that did not exist even a few years ago.
The path forward requires coordinated action from regulators, vendors, health systems, and clinicians. The technical solutions exist — diverse datasets, fairness audits, explainable AI, federated learning. What has been missing is the regulatory mandate to apply them systematically. The evidence is now clear enough to justify that mandate.
Comments
Join the discussion with an anonymous comment.