 AI in Primary Care Evidence-Graded Survey
AI in Primary Care Evidence-Graded Survey
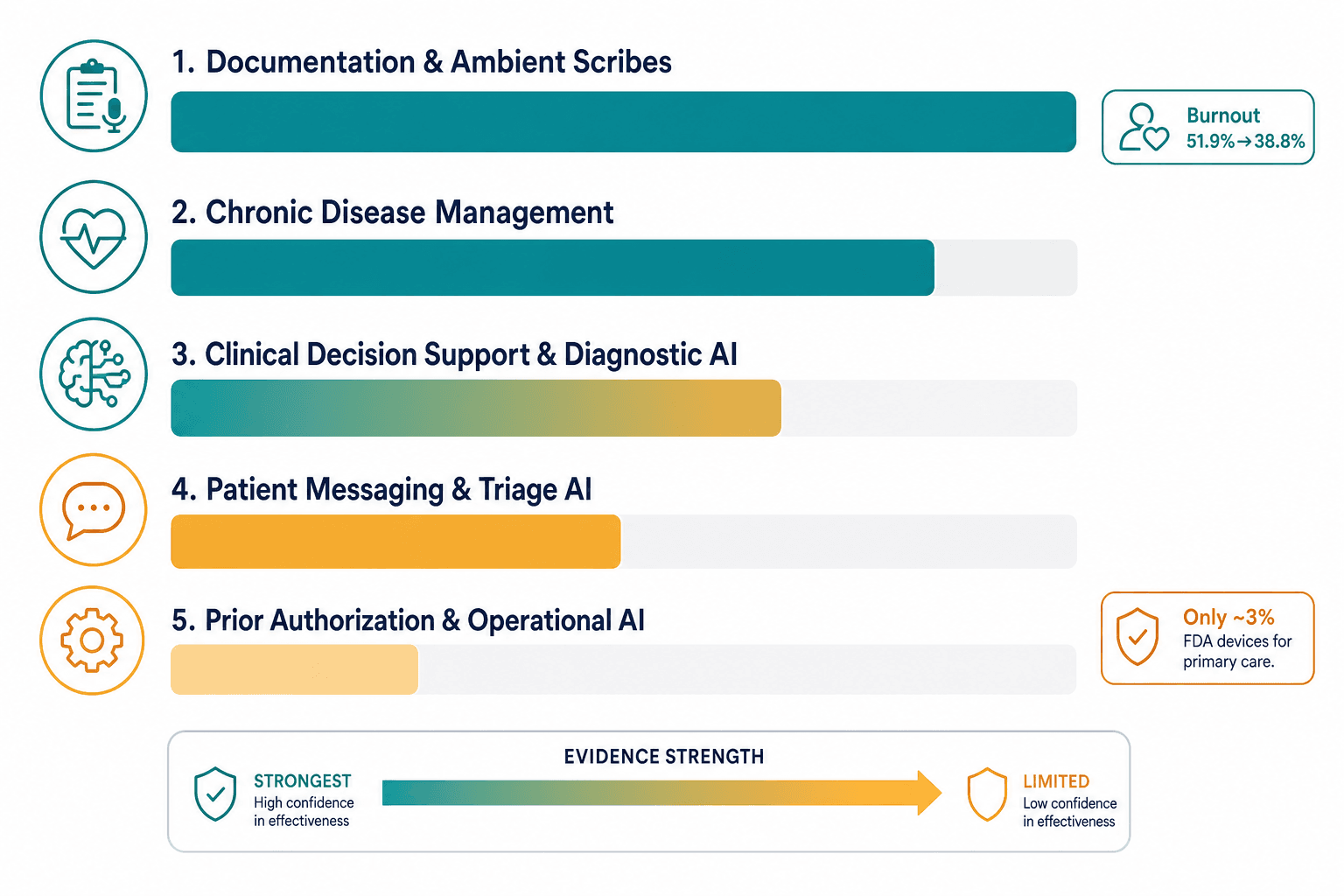
Landscape Overview: Rapid Adoption, Uneven Evidence
Primary care is the setting where most people encounter the healthcare system, yet it has been an afterthought in the AI device market. According to the Stanford Healthcare AI Applied Research Team (HEA₃RT), only about 3% of FDA-approved AI/ML medical devices are designed for primary care, even though roughly half of all healthcare delivery occurs in that setting. That mismatch is starting to close — but not because the device pipeline has shifted dramatically. Instead, clinicians themselves are driving adoption.
The American Medical Association's 2024 survey of nearly 1,200 physicians found that 66% reported using some form of healthcare AI, a 78% increase from 38% in 2023. The top uses were documentation and billing code generation (21%, up from 13%), creation of discharge instructions and care plans (20%), and translation services (14%). Only 12% reported using AI for assistive diagnosis. The enthusiasm gap is also narrowing: 35% of physicians said their enthusiasm for health AI exceeded their concerns, up from 30% in 2023, while only 25% said concerns exceeded enthusiasm.
But adoption is not the same as evidence. A 2025 scoping review published in the Journal of Medical Internet Research (JMIR) examined 73 empirical studies on AI in primary care and found a consistent pattern: AI tools frequently demonstrated strong technical accuracy in controlled settings, but implementation in routine practice was limited by usability barriers, workflow misalignment, clinician trust, equity gaps, and financial constraints. The evidence base is not uniform across applications. Some categories — ambient documentation, for example — have multicenter implementation data with clinically meaningful outcomes. Others, such as prior authorization automation, have barely been studied in primary care at all.
This article surveys five major AI application categories in primary care, grading each on the strength of its real-world evidence. It is designed for clinicians, practice managers, and health-system decision-makers who need to separate the signal from the noise in a fast-moving but unevenly supported field. For readers new to the topic, the AI in healthcare clinical application overview provides a broader foundation.
Documentation & Ambient Scribes: The Strongest Implementation Evidence
Of all AI applications in primary care, ambient scribes have the most compelling real-world evidence for reducing clinician burnout and documentation burden. A 2025 study published in JAMA Network Open (Olson KD et al.) tracked 263 clinicians across six health systems and found that burnout rates dropped from 51.9% to 38.8% after 30 days of ambient scribe use. A separate analysis in NEJM Catalyst (2025) covering 7,260 physicians over 63 weeks found that high users of AI scribes saved 2.5 times more time per note than low users.
The JMIR scoping review also identified an ambient voice technology that reduced documentation time by 28.8%. A 2025 pilot study in the Journal of the American Medical Informatics Association (JAMIA), cited in the California Health Care Safety Net Institute's 2026 guide, confirmed reduced burnout and improved satisfaction scores with ambient scribe use in primary care settings.
The evidence is not uniformly positive, however. The same studies show that accuracy varies by clinical scenario, and error taxonomies — particularly around hallucinated clinical details — remain an active area of investigation. For a deeper analysis of accuracy, safety, and error patterns, see the dedicated LLM-powered ambient AI scribe evidence review. For the evolution of these tools beyond scribing into broader clinical intelligence, see the ambient clinical intelligence article.
Clinical Decision Support & Diagnostic AI: High Accuracy, Limited Real-World RCTs
AI clinical decision support (CDS) tools have generated considerable excitement for their technical performance in diagnostic tasks. The JMIR scoping review documented several examples: an AI model for colorectal cancer prediction achieved 73% sensitivity and 84% specificity; a text-note classifier identified primary headache disorders with 85% accuracy compared to 66% for general practitioners; and an ensemble model detected liver fibrosis with 94% overall accuracy and a 98% negative predictive value. A UTI management tool boosted treatment success from 75% to 84% across 36 practices.
But technical accuracy in a research dataset is not the same as clinical utility in a busy practice. A 2024 review in the European Journal of Investigation in Health Psychology and Education (EJIHPE) found that only six studies of AI CDS systems have been tested in real primary care settings. The JMIR review's analysis of 73 studies confirmed that implementation was consistently limited by usability barriers, workflow misalignment, and clinician trust — not by model performance.
The gap between in silico accuracy and real-world adoption is partly a regulatory and market issue. Most FDA-cleared AI diagnostic tools target radiology, cardiology, and pathology — specialties with high-volume, standardized image interpretation tasks. Primary care, by contrast, deals with undifferentiated symptoms, multiple comorbidities, and fragmented data sources that do not fit neatly into a single AI model's training distribution. The existing deep-dive on AI CDS in primary care covers the mechanisms, validation challenges, and deployment realities in greater detail.
| AI CDS Application | Reported Performance | Real-World Testing |
|---|---|---|
| Colorectal cancer prediction | 73% sensitivity, 84% specificity | JMIR scoping review (2025) |
| Primary headache classification | 85% accuracy vs. 66% for GPs | JMIR scoping review (2025) |
| Liver fibrosis detection | 94% accuracy, 98% NPV | JMIR scoping review (2025) |
| UTI management | Treatment success 75% → 84% | 36 practices (JMIR 2025) |
| AI CDS in primary care overall | — | Only 6 studies in real primary care settings (EJIHPE 2024) |
Chronic Disease Management AI: Diabetic Retinopathy Screening Leads the Way
Chronic disease management is the category where AI has the longest track record in primary care, largely because of diabetic retinopathy screening. The JMIR scoping review reported that AI systems for diabetic retinopathy detection achieved 87–100% sensitivity and 89–98% specificity across multiple studies. The Lancet Primary Care review described diabetic retinopathy screening as "one of the first successful AI applications with impact across trials."
Other chronic disease applications are less mature but show promise. Skin lesion detection AI has been studied extensively, though the Lancet review noted that only 2 of 272 skin cancer AI studies used primary-care-representative training data. Liver fibrosis prediction using ensemble AI models (94% accuracy in the JMIR review) and AI-assisted hypertension and diabetes management tools are in earlier stages of real-world validation.
For detailed implementation evidence on diabetic retinopathy screening in community health centers, see the AI diabetic retinopathy screening deployment report. For skin lesion detection, the AI-enabled skin lesion detection article covers regulatory status and deployment limitations.
- Diabetic retinopathy: 87–100% sensitivity, 89–98% specificity (JMIR 2025)
- Skin cancer detection: strong technical accuracy, but only 2 of 272 studies used primary-care-representative data (Lancet 2025)
- Liver fibrosis: 94% accuracy, 98% negative predictive value (JMIR 2025)
- Hypertension and diabetes management: limited real-world RCT evidence in primary care settings
Patient Messaging & Triage AI: Mixed Evidence and Safety Concerns
AI-drafted responses to patient portal messages and AI triage tools represent one of the most controversial application categories in primary care. The evidence is genuinely mixed, and some findings are concerning.
A 2025 study in npj Digital Medicine found that 35–45% of AI-drafted patient message replies that contained errors were submitted entirely unedited by primary care physicians. This suggests that the efficiency gains of AI drafting may come at the cost of reduced vigilance in reviewing AI-generated output — a phenomenon sometimes called "automation bias" in clinical settings.
The JMIR scoping review reported that an AI triage tool matched physician assessments in only 17% of cases overall, though performance varied by urgency level: 74% agreement for nonurgent cases but only 42% for urgent cases. The Lancet review noted that AI-drafted portal messages showed no evidence of time savings despite perceived efficiency, and a 2024 JAMA Network Open study cited in the California SNI guide found a 20% utilization rate for portal message triage AI, with improved burnout scores but no change in time spent.
| Metric | Finding | Source |
|---|---|---|
| Error-containing AI drafts submitted unedited | 35–45% | npj Digital Medicine (2025) |
| AI triage agreement with physicians (overall) | 17% | JMIR scoping review (2025) |
| AI triage agreement (nonurgent) | 74% | JMIR scoping review (2025) |
| AI triage agreement (urgent) | 42% | JMIR scoping review (2025) |
| Portal message AI utilization rate | ~20% | JAMA Network Open (2024) |
| Time savings from AI-drafted messages | None demonstrated | Lancet Primary Care review (2025) |
Prior Authorization & Operational AI: Emerging but Understudied
The fifth category — AI for prior authorization, clinical coding, appointment scheduling, and revenue cycle management — has the weakest evidence base in primary care. Most published data come from pilot programs and vendor case studies rather than peer-reviewed implementation research.
A notable exception is the UK National Health Service (NHS) pilot of a predictive AI tool for missed appointments ("did not attends," or DNAs). According to a May 2026 editorial in BJGP Open, the tool (Deep Medical) used risk stratification for non-attendance and reported a 30% reduction in DNAs over six months, freeing nearly 2,000 additional appointments. The same editorial noted that AI-enabled triage tools could reduce administrative time by up to 43 minutes per staff member per day, based on a UK Department of Health and Social Care evaluation.
AI for clinical coding — converting unstructured clinical text into structured coded data — is also emerging, with tools like MedPromptExtract cited in the BJGP Open editorial. But peer-reviewed evidence on accuracy, cost savings, and workflow impact in primary care remains sparse.
- Predictive AI for missed appointments: 30% reduction in DNAs over 6 months (NHS pilot, cited in BJGP Open 2026)
- AI-enabled triage tools: up to 43 minutes saved per staff member per day (UK DHSC evaluation, cited in BJGP Open 2026)
- AI clinical coding: emerging tools (e.g., MedPromptExtract) but limited peer-reviewed evidence in primary care
- Prior authorization automation: no published primary-care-specific RCTs identified as of mid-2026
Equity and Bias Considerations in Primary Care AI
The equity dimensions of AI in primary care are not an afterthought — they are central to whether these tools will reduce or widen existing disparities. Several structural issues are specific to primary care.
First, the device pipeline itself is skewed. Only about 3% of FDA-approved AI/ML tools are built for primary care, meaning that most AI tools available to primary care clinicians were designed for other specialties and may not generalize to primary care populations. The Lancet review documented this problem explicitly: a systematic review found that only 2 of 272 skin cancer AI studies used primary-care-representative training data. The same review noted that a large proportion of medical datasets over-represent individuals of European ancestry.
Second, well-resourced health systems are adopting AI faster than safety-net providers, as the California Health Care Foundation (CHCF) brief emphasized. This creates a risk that AI will primarily benefit patients who already have better access to care, while safety-net clinics — which serve disproportionately Black, Latinx, and low-income populations — fall further behind.
Third, there are documented cases of algorithmic bias with direct relevance to primary care. The Lancet review cited an algorithm trained on patient-reported knee pain (rather than radiologist X-ray readings) that doubled the proportion of Black individuals eligible for knee replacement, published in Nature Medicine in 2021. AI has also been shown to predict self-reported race from medical images, raising concerns about race-based algorithmic bias in diagnostic tools.
The Stanford HEA₃RT team's work with Google on DermAssist — testing the app's performance across diverse skin tones in partnership with Santa Clara Family Health Plan's Latinx and Vietnamese communities — is one example of how equity-focused implementation research can address these gaps. For readers seeking audit frameworks and mitigation methods, the algorithmic bias glossary entry provides a structured overview.
Practical Guidance for Practices Evaluating AI Tools
The evidence surveyed in this article supports a clear conclusion: AI adoption in primary care is happening rapidly, but the quality of evidence varies enormously by application category. Practices should match their tool selection to their specific workflow needs and evidence thresholds, not to vendor marketing claims.
Dr. Amelia Sattler of Stanford Medicine HEA₃RT, speaking at a California Health Care Safety Net Institute event in 2026, offered practical adoption advice that aligns with the evidence: start with a clearly defined problem, involve stakeholders early, look to the EHR first, and add an intelligence layer only when needed. The Commure vendor guide proposes a six-step framework over four weeks for evaluating an AI tool, emphasizing that the process should begin with problem identification, not tool shopping.
- Start with a clearly defined problem: What specific workflow pain point are you trying to address? Documentation burden? Diagnostic support? Patient triage?
- Involve stakeholders early: Clinicians, nurses, medical assistants, and IT staff should all have input before a tool is selected.
- Look to the EHR first: Many EHR platforms already include AI features (e.g., Epic's ambient scribe integration). Assess what is already available before adding a new vendor.
- Add an intelligence layer when needed: If the native EHR AI features are insufficient, evaluate third-party tools that integrate with your existing infrastructure.
- Demand evidence, not promises: Ask vendors for peer-reviewed studies conducted in primary care settings, not just in silico accuracy figures or specialty-clinic data.
- Plan for ongoing evaluation: AI model performance can drift over time, and patient populations change. Regular audits are essential.
The AMA's 2024 survey identified two practical priorities that should guide tool selection: 87% of physicians rated data privacy assurances as a top priority, and 84% rated EHR integration as critical. Tools that lack either should be deprioritized regardless of their technical performance.
The CHCF brief and the Lancet review both emphasize that AI should augment, not replace, the patient-physician relationship. The California SNI guide's framing is worth repeating: AI can enhance rather than replace trusted connections between patients and care teams. The future primary care workforce will likely include new roles focused on AI implementation and oversight, as the BJGP Open editorial notes — non-clinical staff will be central to AI governance and operational integration.
Comments
Join the discussion with an anonymous comment.