 MIT
MIT
MIT's AI-in-Healthcare Research Infrastructure
When clinicians and researchers ask where the most concentrated academic effort in healthcare AI resides, MIT's ecosystem is one of the first answers — but it is not a single lab or department. The institutional landscape spans at least four distinct organizational units, each with a different relationship to clinical translation.
The MIT Jameel Clinic, founded in 2018, serves as the primary translational engine. Its explicit mission is to pioneer research in clinical AI and AI-driven drug discovery that can be applied regardless of geography, socioeconomic status, or access to care. As of mid-2026, the clinic reports working with 110 hospitals across 31 countries on five continents, providing free access to AI tools and research expertise. This scale makes the Jameel Clinic arguably the largest academic healthcare AI deployment network in operation.
Surrounding the clinic are MIT's longer-standing research powerhouses. The Computer Science and Artificial Intelligence Laboratory (CSAIL) houses foundational machine learning work that often finds clinical applications. The Institute for Medical Engineering and Science (IMES) bridges engineering and clinical departments. The Department of Electrical Engineering and Computer Science (EECS) supplies much of the algorithmic talent, and the Media Lab contributes human-computer interaction and novel sensing approaches. What distinguishes MIT from other academic AI centers is not just the volume of research output, but the deliberate infrastructure for moving tools from code repositories into hospital workflows.
Key Research Domains: Clinical AI and AI-Driven Drug Discovery
MIT's healthcare AI research portfolio clusters into two broad thrusts, each with distinct methodological approaches, evidence standards, and regulatory pathways.
| Domain | Primary Labs / Faculty | Example Applications | Regulatory Pathway |
|---|---|---|---|
| Clinical AI (Imaging, Risk Prediction, NLP) | Barzilay Lab, Ghassemi Group, Jameel Clinic | Cancer risk prediction from mammograms, lung cancer screening triage, sepsis early warning, ambient documentation | FDA 510(k) clearance for imaging tools; clinical decision support software regulated as SaMD in some cases |
| AI-Driven Drug Discovery | Collins Lab, Jameel Clinic | Antibiotic discovery (halicin, abaucin), target identification, molecular property prediction | Preclinical validation; no FDA-cleared AI-discovered drug as of mid-2026 |
The clinical AI domain has produced the most visible deployed tools. Regina Barzilay's group, for instance, has developed deep learning models that analyze mammograms to predict breast cancer risk up to five years in advance — a capability that shifts the paradigm from reactive detection to prospective risk stratification. In lung cancer, the same lab developed Sybil, a model that predicts future lung cancer risk from a single low-dose CT scan. These tools operate in a regulatory environment where the FDA had approved nearly 1,000 AI-enabled medical devices as of October 2024, up from just one device in 1995 (the PAPNET Testing System for cervical smear re-screening).
The drug discovery domain operates on a different timeline and evidence standard. James Collins's lab at MIT used deep learning to identify halicin — a molecule that showed broad-spectrum antibiotic activity against drug-resistant pathogens — and later abaucin, which targets Acinetobacter baumannii specifically. These discoveries generated enormous scientific and media attention, but neither has yet completed the clinical trial pipeline required for FDA approval as a therapeutic. The gap between a computational prediction and a clinically available drug remains wide, and MIT's own researchers are candid about this.
Landmark Projects with Concrete Evidence
Several MIT-developed AI tools have published performance data that meet the threshold for rigorous evaluation. The following table summarizes the most significant projects with peer-reviewed or pre-publication evidence.
| Project | Clinical Problem | AI Approach | Key Performance Metric | Study Type | Source |
|---|---|---|---|---|---|
| Sybil | Lung cancer risk prediction from low-dose CT | Deep learning on single CT scan | AUC not publicly specified in available sources; predicts future risk from single scan | Retrospective validation | MIT Sloan / Barzilay Lab |
| Mammography-based breast cancer risk | Breast cancer risk prediction up to 5 years in advance | Deep learning on mammogram images | Identifies high-risk patients; allows 95% of healthy people to forgo unnecessary screenings (per Barzilay) | Retrospective studies | MIT Sloan / Barzilay Lab |
| Halicin | Broad-spectrum antibiotic discovery against drug-resistant pathogens | Deep learning on molecular libraries | Identified molecule with activity against Mycobacterium tuberculosis and carbapenem-resistant Enterobacteriaceae | Computational screen + in vitro validation | Collins Lab / Jameel Clinic |
| Abaucin | Antibiotic against Acinetobacter baumannii | Deep learning on molecular libraries | Narrow-spectrum activity against A. baumannii | Computational screen + in vitro validation | Collins Lab / Jameel Clinic |
| MultiverSeg | Rapid medical image segmentation | Interactive AI segmentation with user clicks, scribbles, boxes | 90% accuracy with ~2/3 fewer scribbles and ~3/4 fewer clicks than ScribblePrompt; zero-user-input by 9th image | Benchmark study (presented at International Conference on Computer Vision) | MIT News (2025) |
| TREWS | Sepsis early warning in hospital settings | Machine learning on EHR data | Published in peer-reviewed literature; specific metrics vary by study | Prospective and retrospective studies | Jameel Clinic / multiple hospitals |
MultiverSeg, developed by MIT researchers and presented at the International Conference on Computer Vision, illustrates a particularly clean evidence story. The system achieves 90% segmentation accuracy with roughly two-thirds fewer scribbles and three-quarters fewer clicks than prior tools like ScribblePrompt. By the ninth new image, it can reach zero-user-input segmentation — meaning the model learns the user's annotation style rapidly enough to automate the task. Critically, the system does not require a pre-segmented dataset for training and can segment 2D images without retraining, which lowers the barrier for clinical adoption in resource-constrained settings.
The Evidence Gap: Accuracy Is Not Patient Outcomes
The central tension in MIT's healthcare AI story — and in the field more broadly — is that model accuracy does not equal improved patient outcomes. A 2026 paper in Nature Medicine by Wiens (University of Michigan) and Goldenberg (University of Toronto) — both of whom have deep ties to the MIT research community — argues that growing numbers of AI tools are deployed in clinical settings without rigorous assessment of whether they actually improve patient health outcomes. The paper's DOI (s41591-026-04329-2) places it at the center of an accelerating debate.
The scale of the problem is measurable. A January 2025 study by Paige Nong found that approximately 65% of US hospitals use AI-assisted predictive tools, but only two-thirds of those hospitals evaluate the accuracy of the tools they deploy, and even fewer assess for algorithmic bias. This means that tens of millions of patient encounters each year are influenced by AI systems whose real-world performance — and potential for harm — is essentially unmonitored.
MIT's own researchers have been among the most vocal critics of this gap. Marzyeh Ghassemi, an MIT assistant professor, has published extensively on how machine learning models often perform worse for populations including Black women, precisely because health disparities in training data translate into model disparities. Her 2022 paper in Patterns cautioned that if AI is not used carefully, it could worsen care and reduce health equity. One of the most concrete examples she has highlighted involves pulse oximeters: devices calibrated predominantly on light-skinned individuals that do not accurately measure blood oxygen levels for people with darker skin, with deficiencies most acute when oxygen levels are low. When AI models are trained on data from such devices, the resulting algorithms inherit and potentially amplify these measurement biases.
Health-care AI is here. We don't know if it actually helps patients. — MIT Technology Review, April 2026
This headline from MIT's own publication captures the paradox precisely. The same institution that produces breakthrough AI tools also publishes the most pointed critiques of the evidence base. That tension is not a contradiction — it is a sign of intellectual honesty, but it also means that clinicians and health IT professionals evaluating MIT-developed tools must distinguish between published performance metrics and proven clinical utility.
MIT's Role in Regulatory and Policy Discourse
MIT researchers have not limited their engagement to building tools and publishing critiques — they have also entered the regulatory and policy arena directly. In December 2024, Ghassemi, Hightower, and colleagues published a commentary in NEJM AI addressing the implications of the ACA nondiscrimination rule (May 2024), which covers both AI and non-AI patient care decision support tools. The commentary noted that 65% of U.S. physicians use clinical risk scores on a monthly basis, yet there is no regulatory body specifically overseeing these algorithms — a gap the ACA rule attempts to address, but only partially.
The Jameel Clinic has also hosted regulatory conferences in 2024 and 2025, bringing together FDA officials, health system leaders, and AI researchers to discuss the evolving framework for AI device oversight. These convenings matter because the regulatory environment directly shapes which MIT-developed tools can reach clinical settings and under what conditions. With nearly 1,000 FDA-approved AI-enabled devices as of October 2024 — the vast majority cleared through the 510(k) pathway, which requires demonstration of substantial equivalence to a predicate device rather than independent clinical efficacy — the bar for market entry is lower than many clinicians assume.
- The ACA nondiscrimination rule (May 2024) applies to both AI and non-AI clinical decision support tools used in patient care decisions.
- No single regulatory body oversees clinical risk scores, despite their widespread use by 65% of U.S. physicians monthly.
- The Jameel Clinic's regulatory conferences (2024, 2025) serve as a rare forum where academic researchers, FDA officials, and hospital administrators discuss AI governance.
- FDA clearance (510(k)) does not require demonstration of improved patient outcomes — only substantial equivalence to an already-cleared device.
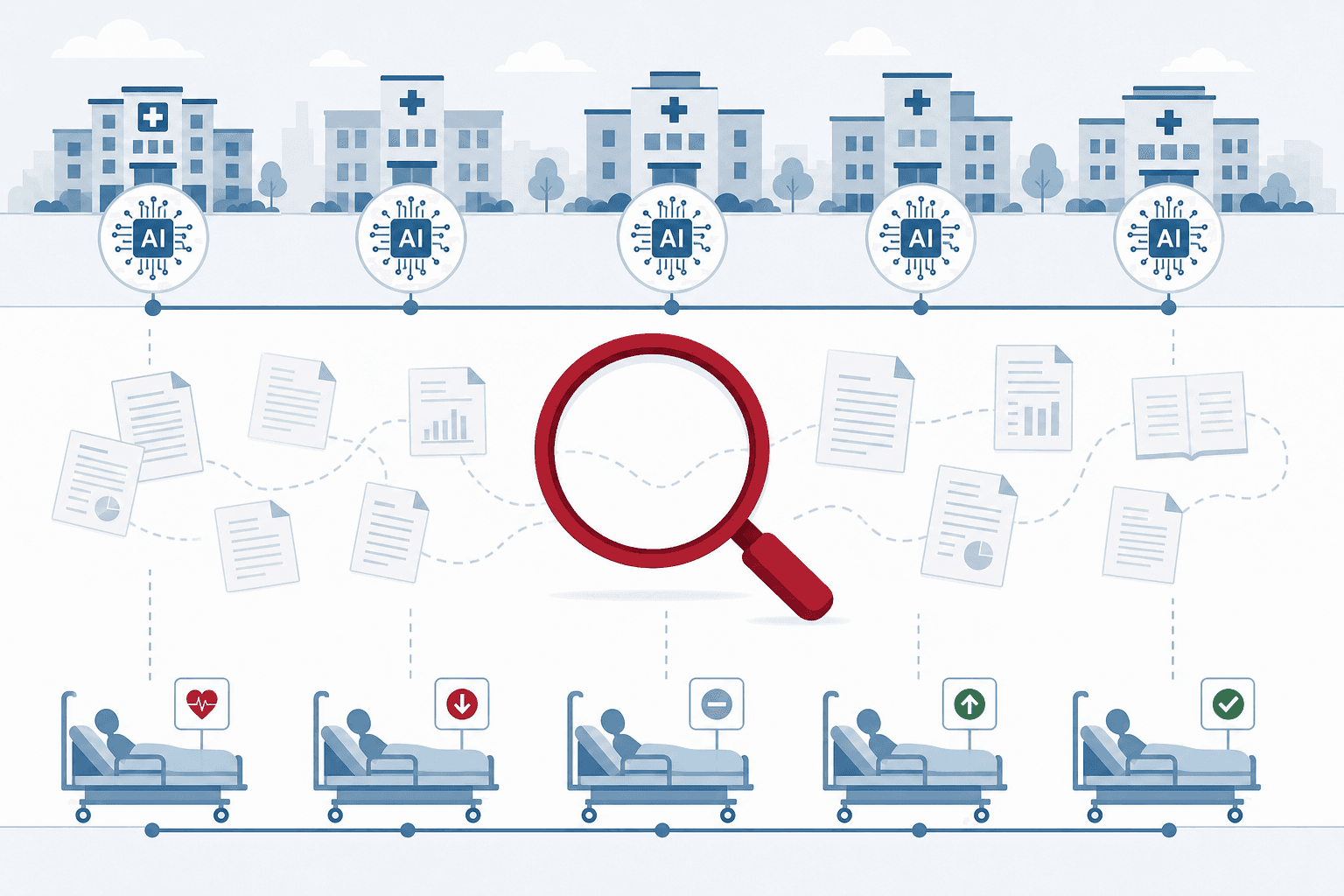
Translation to Practice: From Lab to 110 Hospitals
The Jameel Clinic's model for translating research into practice is distinctive: rather than licensing its tools exclusively to commercial vendors, the clinic provides free access to AI tools and research expertise across its network of 110 hospitals in 31 countries. This approach removes cost as a barrier to adoption, particularly for hospitals in low-resource settings that would otherwise be priced out of the AI market.
The deployment contexts within this network vary enormously. Some partner hospitals are major academic medical centers with dedicated data science teams and robust EHR infrastructure. Others are district hospitals in sub-Saharan Africa or South Asia where internet connectivity is intermittent and clinical staff are already stretched thin. The same AI tool that performs well in a Boston teaching hospital may degrade significantly when deployed in a setting with different patient demographics, imaging equipment, or documentation practices.
This variation is both a strength and a vulnerability. It means that MIT's tools are being tested across a broader range of real-world conditions than most commercial AI products, which tend to be deployed first in well-resourced health systems. But it also means that the evidence emerging from these deployments is heterogeneous and difficult to aggregate into a single performance narrative. Some partner hospitals may have published implementation studies; others may be using the tools without any formal evaluation infrastructure.
- 110 hospitals across 31 countries on 5 continents receive free access to Jameel Clinic AI tools and research expertise.
- Deployment settings range from major academic medical centers to resource-constrained district hospitals.
- The model prioritizes equity of access over commercial return, but this creates challenges for systematic evidence collection.
- Real-world performance data from these deployments is not yet publicly aggregated in a single, auditable registry.
Tensions and Open Questions
Synthesizing MIT's healthcare AI landscape reveals several unresolved tensions that clinicians, researchers, and health IT professionals should track closely. These are not failures of MIT's research program — they are active areas of investigation that define the frontier of the field.
The accuracy-outcomes gap remains the most consequential. A model that achieves 90% segmentation accuracy or an AUC of 0.95 in a retrospective study may have no measurable effect on patient mortality, length of stay, or diagnostic error rates when deployed prospectively. The Wiens and Goldenberg Nature Medicine paper (2026) and the Nong et al. study (2025) both document that the majority of US hospitals deploying AI tools do not evaluate their impact on outcomes. MIT's own tools are not exempt from this critique — the evidence that Sybil or the mammography risk models reduce cancer mortality or improve treatment decisions has not yet been published in a prospective, controlled trial.
Bias in training data is a second unresolved tension. Ghassemi's work on pulse oximeter disparities is a concrete example of how measurement bias propagates into AI models, but it is far from the only one. Training datasets for medical imaging AI are known to underrepresent darker skin tones, certain age groups, and rare diseases. When MIT's tools are deployed across 31 countries with vastly different patient populations, the risk of performance degradation for specific subgroups is real and largely unmeasured.
The need for prospective clinical trials of AI tools is widely acknowledged but rarely funded or executed. Randomized controlled trials of AI interventions are expensive, logistically complex, and difficult to design in a way that accounts for the rapid iteration cycles of machine learning models. The result is that most AI tools — including those from MIT — enter clinical use based on retrospective evidence and bench testing, not the kind of prospective randomized evidence that would be required for a new drug or surgical technique.
Finally, there is the question of cognitive impact on clinicians. As ambient AI scribes and clinical decision support tools become more prevalent — MIT's Barzilay lab has contributed to this space — the concern is not just whether the tools are accurate, but how they change the way doctors think. The MIT Technology Review article (April 2026) raised the specific concern that AI tools may affect how clinicians cognitively process information, potentially deskilling or altering clinical judgment in ways that are difficult to measure. This is a research question, not a settled finding, but it is one that MIT's own researchers are beginning to investigate.
For the clinicians, researchers, and health IT professionals who constitute ClinicalMind's primary audience, the takeaway is not that MIT's AI work is overhyped or underperforming. It is that the field has reached a stage where technical performance and clinical benefit have decoupled, and MIT — to its credit — is one of the few institutions producing both the breakthroughs and the critical evidence framework needed to evaluate them. The next five years will determine whether the Jameel Clinic's 110-hospital network becomes a model for evidence generation or a cautionary tale about deployment without evaluation.
Comments
Join the discussion with an anonymous comment.