Two Numbers, One Paradox
Consider two numbers. The first comes from the MASAI trial—a randomized controlled trial of more than 100,000 women in Sweden. AI-supported mammography screening reduced interval cancers by 12%. The second: roughly 40 million U.S. adults—about 12% of the adult population—use an AI chatbot every day for health information. The first number comes from a peer-reviewed trial with hard endpoints. The second comes from a survey, and behind it there are no outcome data at all.
This is the paradox: the medical AI with the strongest evidence—deep-learning imaging tools validated in multiple RCTs—is the one that has been slowest to reach routine clinical practice. Meanwhile, generative AI, with an evidence base that is thin and biased, is being adopted by tens of millions of patients and a majority of physicians. I find this inversion not just interesting, but consequential. It tells us that deployment does not follow proof, and that adoption does not equal efficacy.
What the Evidence Actually Shows
Start with imaging AI. The MASAI trial is the strongest single piece of evidence for AI in screening. Over 100,000 women, AI-supported reading detected 81% of cancers at screening versus 74% with standard double reading. Interval cancers—those that appear between screenings, often aggressive—fell by 12% (1.55 vs 1.76 per 1,000). False-positive rates were essentially identical: 1.5% in the AI group, 1.4% in control. That is not a surrogate endpoint. It is a direct measure of patient harm averted. I would call that strong evidence.
The result is not an outlier. A German mammography RCT (Eisemann et al., Nature Medicine, 2025) found that radiologists who could optionally consult AI detected more cancers without increasing false alarms. Four randomized trials for colonoscopy AI-assist have consistently shown improved adenoma detection rates. In one hospital-based study, an AI model trained on continuous wearable vital signs predicted deterioration 8 to 24 hours before standard alerts, identifying patients at risk for ICU transfer or cardiac arrest (Scheid et al., Nature Communications, 2025).
These studies are prospective, randomized or well-controlled, measure patient-relevant outcomes, and were conducted in real clinical settings. That is the kind of evidence that should drive adoption. Yet as of early 2026, despite more than 1,200 FDA-cleared AI devices—the vast majority for radiology—integration into routine workflow remains patchy. Clearance is not deployment.
Now consider generative AI. A meta-analysis published in npj Digital Medicine in 2025 pooled 83 studies evaluating diagnostic accuracy of large language models. The pooled accuracy: 52.1% (95% CI, 47.0–57.1%). That is barely above chance for a multiple-choice test. More telling, 76% of the studies (63 out of 83) were rated at high risk of bias using the PROBAST tool. When compared head-to-head, the models performed significantly worse than expert physicians—a gap of 15.8 percentage points (p=0.007). Against non-expert physicians, the difference was not significant (p=0.93). The models were essentially indistinguishable from a generalist, but far from a specialist.
The ARISE State of Clinical AI Report from Stanford and Harvard reviewed over 500 medical AI studies and found that nearly half tested models using medical exam–style questions. Only 5% used real patient data. Few assessed whether the model recognized its own uncertainty. Even fewer examined bias or fairness. This is a critical limitation. If a model has only been tested on exam questions, we have no idea how it will behave when a patient presents with an atypical symptom or a rare condition. The evidence base for generative AI is not just thin—it is structurally biased toward easy cases.
What Adoption Actually Measures
Despite this, physician use of generative AI has surged. The Doximity 2026 State of AI in Medicine Report, based on 3,151 U.S. physicians, found 54% currently using AI—up from 47% in early 2025. 37% use it at least daily. 75% of users report that AI has reduced administrative burden and improved job satisfaction. 69% say it has led to better patient care and outcomes. These are self-reported perceptions, not measured outcomes. “Better patient care” in a survey is not the same as fewer interval cancers or lower mortality. I would not confuse the 69% figure with evidence of clinical effectiveness. It tells us that physicians believe they are delivering better care. It does not tell us that patients are actually better off.
The MASAI trial measured what happened to patients. The Doximity survey measures what physicians think happened. Those are different orders of evidence—and we need to keep them separate.

Proportional Evidence – A Way Forward
Nature Medicine's April 2026 editorial addressed this directly. It argued for “proportional evidence”: stronger claims of clinical impact require stronger evidence. Retrospective validation alone is insufficient for claims of improved outcomes. The editorial laid out four tiers: analytic performance (requires robust validation in intended setting), clinical actionability (requires evidence outputs are interpretable), workflow benefit (requires implementation studies), and improved outcomes (requires prospective comparative evaluations).
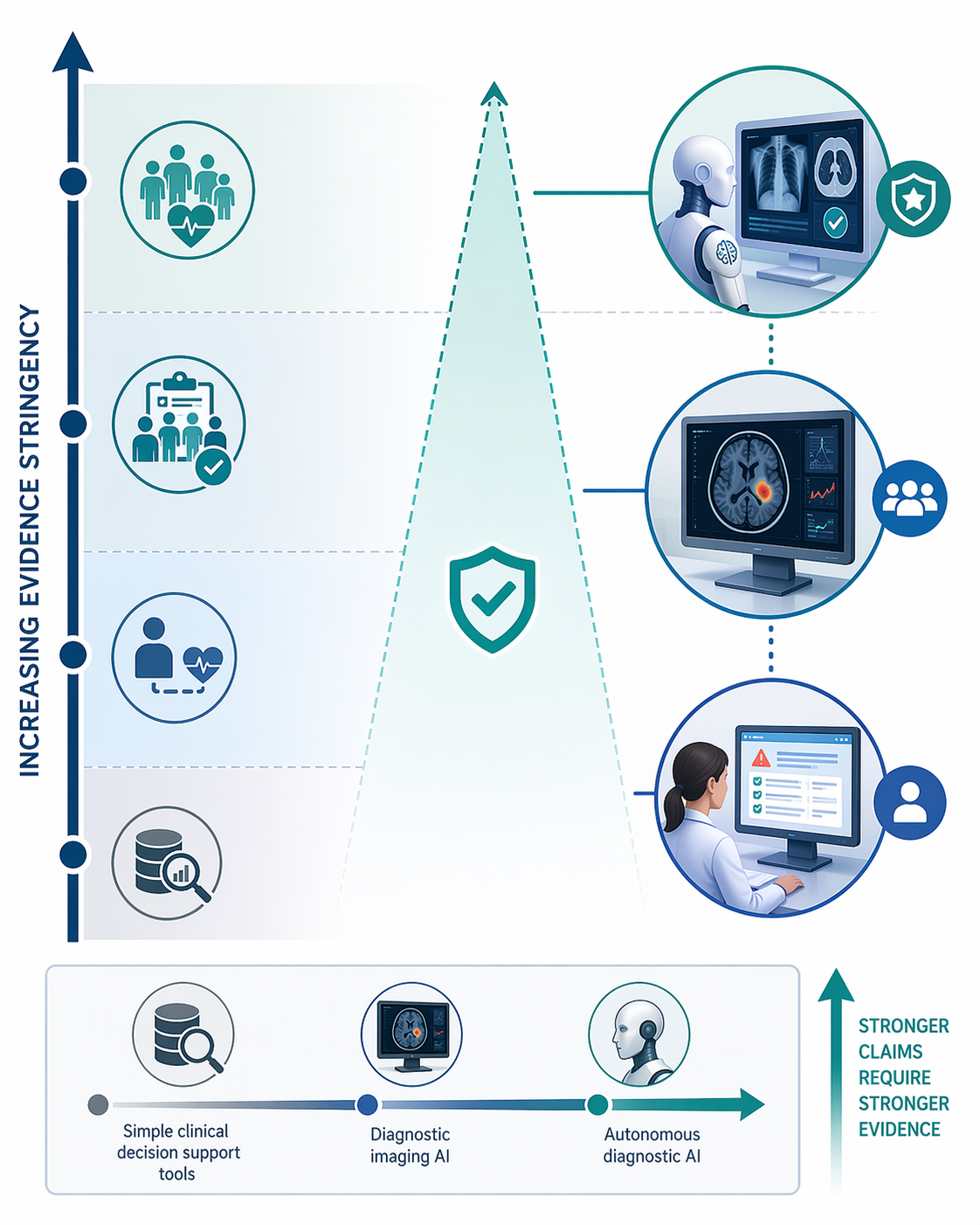
Under this framework, imaging AI tools that have completed RCTs can reasonably claim improved outcomes. Generative AI tools that have only been tested on exam-style questions cannot yet claim clinical actionability. The gap is not a matter of time. It is a matter of study design.
What does this mean for health systems evaluating AI tools? Ask your vendor: Was this model tested on real patient data, or on exam questions? Does the vendor have a prospective study comparing outcomes? What are the documented failure modes? The npj meta-analysis found 76% of studies at high risk of bias—your vendor should be able to explain how their own evidence avoids those same pitfalls. For imaging AI, the barrier is no longer evidence; it is workflow integration, reimbursement, and implementation inertia. Ask why a proven tool is not yet in your clinic.
The path forward is not to reject generative AI. It is to insist that the evidence catches up to the adoption rate. And for imaging AI, it is to address the implementation barriers that keep proven tools from reaching patients. Both gaps need closing—not with more hype, but with more rigor.
Comments
Join the discussion with an anonymous comment.