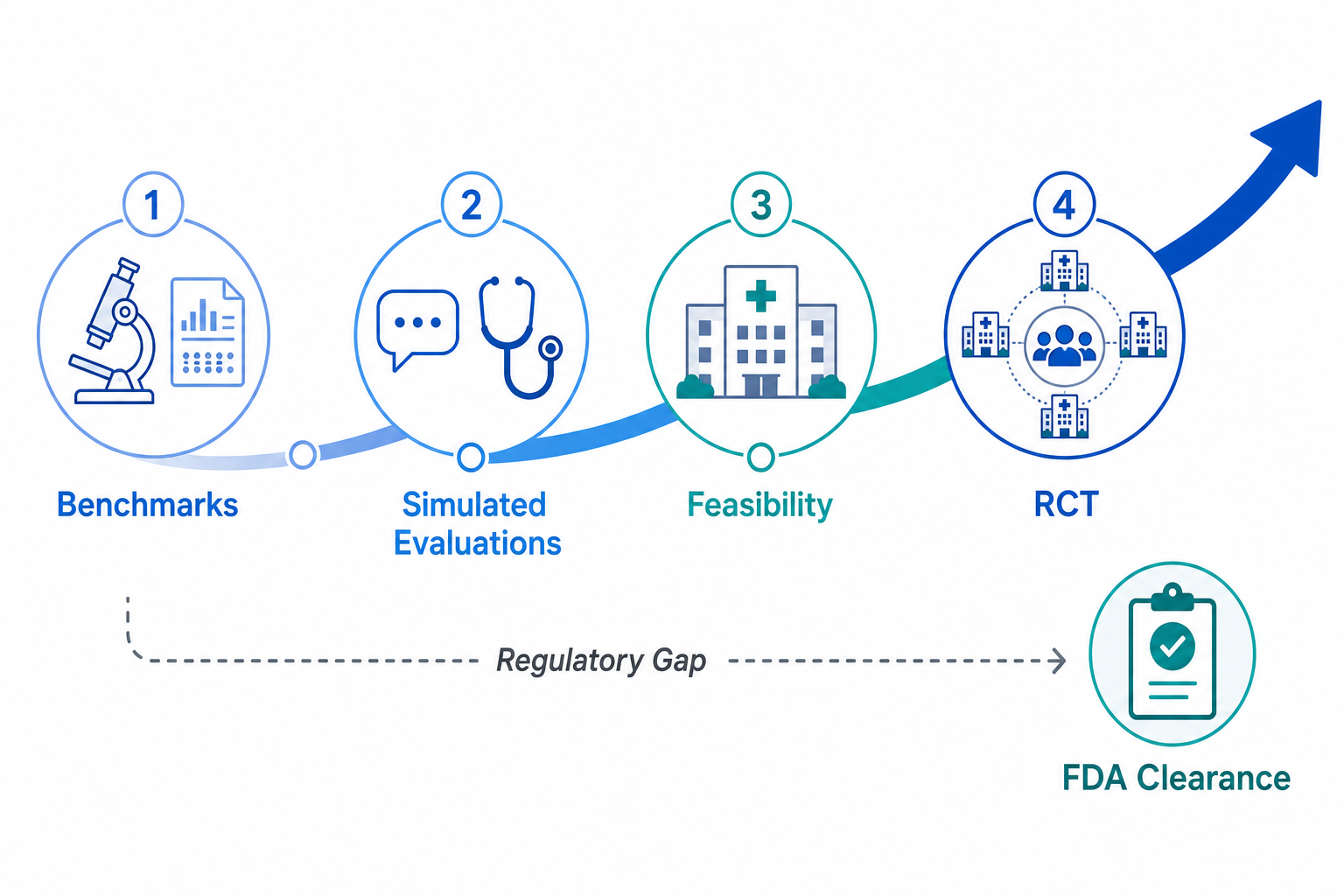

The Staged Evidence Framework: A Lens for Assessing Google's Clinical AI Research
Evaluating the clinical readiness of an AI system requires more than a tally of benchmark scores or a list of published papers. For health systems, evidence reviewers, and regulatory professionals, the critical question is not simply whether an AI model performs well in a controlled setting, but how far along the path from laboratory demonstration to real-world clinical validation it has traveled. This article applies a four-stage evidence pipeline — benchmarks, simulated clinical evaluations, real-world feasibility studies, and randomized controlled trials — as an organizing framework to assess the maturity of Google's healthcare AI research.
This staged framework is an analytical tool applied by this article, not an official Google classification. It is designed to make explicit what each piece of evidence actually demonstrates and, just as importantly, what it does not. A benchmark result shows that a model can answer exam-style questions. A simulated consultation study shows that a model can converse with standardized patients. A single-center feasibility study shows that a model can operate under real clinical conditions with a safety supervisor. A nationwide RCT shows that a model improves patient outcomes across diverse populations and settings. Each stage answers a different question, and skipping stages carries real risk.
The article focuses specifically on Google's clinical AI research — the models and systems intended for direct patient care or clinical decision support, including AMIE, MedGemma, and the AI co-clinician. It does not provide a general portfolio overview of all Google health AI products, nor does it trace the chronological model evolution from Med-PaLM to the AI co-clinician. Those topics are covered in companion articles. Instead, the goal is to assess where each initiative sits in the evidence pipeline, what gaps remain, and what the regulatory landscape means for health systems evaluating these tools for procurement.
Stage 1: Benchmarks — USMLE, MedVidQA, and RxQA OpenFDA
Benchmark evaluations represent the earliest and most common form of AI assessment in medicine. They measure a model's ability to answer standardized questions drawn from medical licensing exams, clinical vignettes, or drug information databases. Google's models have achieved notable results at this stage, but benchmark performance is a necessary condition for clinical deployment, not a sufficient one.
| Benchmark | Model | Performance | Significance |
|---|---|---|---|
| USMLE-style questions | Gemini fine-tuned | 91.1% accuracy | Improved from 86.5% (Med-PaLM 2); demonstrates strong medical knowledge recall |
| MedVidQA | Gemini-based | State-of-the-art | Tests ability to answer clinical questions from video content |
| RxQA OpenFDA | AI co-clinician | Surpassed other frontier AI systems | Open-ended question-answering about medications using FDA drug labeling data |
The USMLE-style result — 91.1% accuracy on a fine-tuned Gemini model — represents a meaningful improvement over the 86.5% achieved by Med-PaLM 2, but it measures knowledge recall, not clinical reasoning in an interactive patient encounter. Similarly, the RxQA OpenFDA benchmark evaluates the AI co-clinician's ability to answer medication-related questions using structured FDA labeling data, a task that tests information retrieval and synthesis rather than diagnostic reasoning or shared decision-making.
Benchmarks are useful for tracking technical progress and comparing model families, but they do not predict real-world clinical performance. A model that scores 91% on USMLE-style questions may still miss critical red flags in a live patient conversation, fail to adapt to a patient's health literacy level, or produce confidently wrong answers in edge cases. The staged evidence framework treats benchmarks as Stage 1 precisely because they answer a narrow question: can the model recall and apply medical knowledge in a structured format? The answer for Google's models is yes, and convincingly so. But the harder questions begin at Stage 2.
Stage 2: Simulated Clinical Evaluations — AMIE in Nature and Specialist Studies
Simulated clinical evaluations move beyond static question-answering to assess how an AI system performs in interactive, conversation-based clinical scenarios. Google's AMIE (Articulate Medical Intelligence Explorer) has been the subject of several such evaluations, including a landmark study published in Nature and specialist-care collaborations with Stanford Medicine and Houston Methodist Hospital.
AMIE vs. Primary Care Physicians: The Nature Study
In the most prominent of these studies, published in Nature in 2024, AMIE was evaluated against primary care physicians (PCPs) in simulated, text-based consultations using validated OSCE (Objective Structured Clinical Examination) style cases. The study used patient actors and employed a rigorous blinded evaluation design. AMIE outperformed PCPs on 52 of 58 evaluation axes, covering dimensions such as diagnostic accuracy, conversational quality, empathy, and information gathering.
This result generated significant attention, and for good reason: it demonstrated that a large language model could engage in extended diagnostic conversations, ask relevant follow-up questions, and maintain a conversational tone that evaluators rated as more empathetic than that of human physicians. However, the study's simulated nature is critical to interpreting its results. The consultations were text-based, conducted with standardized patient actors rather than real patients, and did not include physical examination, nonverbal cues, or the time pressures of actual clinical practice.
Google Research extended AMIE's evaluation into specialist care through two collaborations in 2024. At Stanford Center for Inherited Cardiovascular Disease, researchers curated a real-world de-identified dataset of 204 consecutive patients with suspected cardiomyopathy. AMIE's responses were preferred over general cardiologists' responses in 5 of 10 evaluation domains and were rated equivalent in the remaining 5. Notably, when cardiologists had access to AMIE's response before formulating their own, overall response quality improved in 63.7% of cases and worsened in only 3.4%.
At Houston Methodist Hospital, AMIE was evaluated on 50 synthetic breast cancer vignettes. The results followed a clear hierarchy: AMIE's responses outperformed internal medicine trainees and oncology fellows but remained inferior to responses from attending oncologists. This finding is consistent with the pattern observed in many AI-in-medicine studies: the technology tends to raise the performance of less experienced clinicians closer to that of experts, but does not yet surpass expert-level performance in complex specialist domains.
| Study | Setting | Key Finding | Limitation |
|---|---|---|---|
| AMIE vs. PCPs (Nature 2024) | Simulated OSCE consultations with patient actors | AMIE outperformed PCPs on 52 of 58 axes | Text-based, simulated patients, no physical exam |
| Stanford Cardiology | 204 real cardiomyopathy cases, de-identified | AMIE preferred over general cardiologists in 5 of 10 domains; improved cardiologist responses in 63.7% of cases | Retrospective dataset, not live clinical workflow |
| Houston Methodist Oncology | 50 synthetic breast cancer vignettes | AMIE outperformed trainees/fellows but inferior to attending oncologists | Synthetic vignettes, not real patient encounters |
Stage 3: Real-World Feasibility — The BIDMC Single-Center AMIE Study
The transition from simulated evaluations to real-world feasibility testing is the most consequential step in the evidence pipeline. Google's partnership with Beth Israel Deaconess Medical Center (BIDMC) represents this transition for AMIE. The study is a prospective, single-center evaluation in which AMIE interacts with real patients in a clinical setting, with a supervising doctor present who can intervene at any time.
As of the available public information, the BIDMC study has shown "strong indications of safety" based on outcome measures such as safety supervisor interruptions. However, the full results have not yet been published in a peer-reviewed journal. The study design — prospective, real-world, with a safety supervisor — is methodologically appropriate for a first-in-human feasibility assessment, but the lack of published data means that independent evaluation of the safety and performance findings is not yet possible.
The BIDMC study is a single-center investigation, which limits generalizability. A single academic medical center with a specific patient population, clinician culture, and technical infrastructure cannot represent the diversity of settings in which AI tools would need to operate if deployed broadly. Nonetheless, the study is a necessary step: without evidence that AMIE can function safely in even one real clinical environment, larger-scale trials would be premature.
Stage 4: Nationwide RCT — The Included Health Partnership
The highest stage in the evidence pipeline is the randomized controlled trial, and Google's partnership with Included Health represents the first prospective randomized evaluation of conversational AI in real-world virtual care at scale. The study is described as a nationwide randomized controlled trial, with IRB approval pending at the time of the announcement.
The scale and design of this trial are significant. Included Health provides virtual care to a large, geographically diverse patient population across the United States. A randomized design comparing AI-assisted virtual care to standard virtual care would, if executed rigorously, provide the strongest evidence to date on whether conversational AI improves clinical outcomes, patient experience, or healthcare utilization in real-world settings.
However, several important caveats apply. First, the trial is IRB-pending, meaning the study protocol has not yet received ethical approval, let alone begun enrollment. Second, the specific AI system being evaluated has not been explicitly named in public communications, though it is reasonable to infer that AMIE or a derivative system is involved. Third, the outcome measures, sample size, and statistical power calculations have not been disclosed. Without these details, it is impossible to assess whether the trial will be adequately powered to detect clinically meaningful differences.
The progression from the BIDMC single-center feasibility study to the Included Health nationwide RCT follows a logical evidence-development pathway. If the BIDMC study demonstrates safety and feasibility, and the Included Health trial demonstrates efficacy and generalizability, Google's conversational AI would have generated evidence at all four stages of the pipeline. But neither study has published results yet, and the gap between study registration and published evidence is where many promising AI interventions have stalled.
What Has Been Published and What Hasn't: Evidence Gaps
A transparent assessment of Google's clinical AI evidence base requires a clear distinction between published, peer-reviewed studies and ongoing or pre-registered studies with pending results. The following table summarizes the current evidence landscape.
| Study | Stage | Status | Key Limitation |
|---|---|---|---|
| AMIE vs. PCPs (Nature 2024) | Stage 2: Simulated | Published, peer-reviewed | Simulated patients, text-based, no physical exam |
| Stanford Cardiology | Stage 2: Simulated | Published, peer-reviewed | Retrospective dataset, not live clinical workflow |
| Houston Methodist Oncology | Stage 2: Simulated | Published, peer-reviewed | Synthetic vignettes, not real patient encounters |
| BIDMC Feasibility | Stage 3: Real-world feasibility | Ongoing, results pending | Single-center, limited generalizability |
| Included Health RCT | Stage 4: Nationwide RCT | IRB-pending, not yet enrolled | No results available; study design details not fully disclosed |
Several evidence gaps are immediately apparent. First, there is no published prospective multi-center evidence for any Google conversational AI system. The BIDMC study, if completed and published, would provide single-center prospective evidence, but multi-center replication is needed to assess generalizability across different patient populations, clinical workflows, and health system contexts.
Second, there is no published evidence on performance across diverse demographic groups. The Stanford cardiology study used a real-world dataset, but the demographic composition of that dataset has not been publicly analyzed in the context of algorithmic fairness. Given well-documented concerns about bias in AI models, the absence of published subgroup analyses is a significant gap.
Third, there is no published evidence on the AI co-clinician system in real clinical settings. The AI co-clinician, announced in April 2026, has been evaluated in head-to-head blind evaluations of 98 realistic primary care queries, recording zero critical errors in 97 cases, and in 120 simulated telemedical encounters. These are Stage 2 evaluations. The system has not yet progressed to Stage 3 or Stage 4.
Regulatory Context: No FDA-Authorized Generative AI Devices as of March 2026

The regulatory context for Google's clinical AI research is defined by a striking fact: as of the March 2026 FDA database update, no device authorized for marketing uses generative AI or is powered by large language models. This includes all 1,451 cumulative AI/ML-enabled medical device authorizations through the end of 2025. Every FDA-authorized AI device today uses traditional machine learning techniques — convolutional neural networks for image analysis, gradient-boosted trees for risk prediction, or similar approaches — not foundation models or generative architectures.
The scale of FDA AI/ML device authorizations has grown rapidly. In 2025 alone, the FDA cleared 295 AI/ML-enabled devices from 221 unique manufacturers, with a median clearance time of 142 days. Radiology dominates, accounting for approximately 76% of all authorized devices (1,104 of 1,451). Cardiovascular follows at 141 devices, and neurology at 67. The 510(k) pathway accounts for 1,396 of the 1,451 authorizations, reflecting the predominance of devices that are substantially equivalent to predicate devices rather than novel technologies requiring De Novo classification.
The absence of FDA-authorized generative AI devices has direct implications for Google's clinical AI portfolio. AMIE, the AI co-clinician, MedGemma, and related systems are all research-stage tools. None has been submitted for FDA clearance as a medical device, and the regulatory pathway for LLM-based clinical decision support remains uncertain. The FDA has issued draft guidance on predetermined change control plans (PCCPs) for AI/ML devices, and 10% of 2025 clearances used PCCPs, but these apply to traditional ML models, not generative systems.
This regulatory gap is not necessarily a reflection on the quality of Google's research. It reflects the early stage of the technology and the absence of an established regulatory framework for generative AI in healthcare. The FDA has not yet determined what evidence standard will apply to LLM-based devices, how to evaluate the safety of systems that produce different outputs for the same input, or how to manage post-market surveillance for models that can be updated without a traditional software change. Until these questions are resolved, the regulatory pathway for Google's clinical AI remains unclear.
Implications for Health Systems Evaluating Google's AI
For clinical researchers, evidence reviewers, health technology assessors, and regulatory professionals, the staged evidence pipeline provides a structured way to evaluate where Google's clinical AI research stands and what gaps remain before these tools can be considered for procurement or deployment. The following implications emerge from this assessment.
- Evidence maturity is concentrated in Stages 1 and 2. Google has published strong benchmark results and compelling simulated clinical evaluations, including a Nature publication and specialist-care studies. These demonstrate technical capability and provide a foundation for further research, but they do not constitute evidence of real-world clinical safety or efficacy.
- Real-world evidence is pending, not published. The BIDMC feasibility study and the Included Health RCT represent the critical next steps in the evidence pipeline, but neither has published results. Health systems should monitor these studies closely but should not treat pre-registration or interim safety signals as equivalent to published, peer-reviewed evidence.
- Regulatory clearance is absent and the pathway is uncertain. No FDA-authorized device uses generative AI or LLMs. Health systems that require FDA clearance for clinical AI tools cannot currently procure Google's conversational AI systems. The timeline for regulatory clearance depends on both Google's submission strategy and the FDA's development of an appropriate framework for generative AI devices.
- Generalizability across diverse populations is unproven. The published studies do not provide subgroup analyses by race, ethnicity, socioeconomic status, or other demographic variables. Given documented disparities in AI model performance across demographic groups, this is a significant evidence gap that should be addressed before deployment in diverse patient populations.
- The AI co-clinician is at an earlier evidence stage than AMIE. Announced in April 2026, the AI co-clinician has been evaluated in simulated settings with promising results — zero critical errors in 97 of 98 primary care queries — but has not yet progressed to real-world feasibility studies. Its evidence pipeline is approximately one to two years behind AMIE's.
The staged evidence framework reveals that Google's clinical AI research is following a methodologically sound progression, but the gap between published evidence and regulatory/commercial readiness remains substantial. Health systems should engage with Google's research as a promising development to monitor, not as a solution ready for procurement. The next 12 to 24 months — during which the BIDMC feasibility results and the Included Health RCT results may become available — will be decisive in determining whether conversational AI can make the transition from simulated success to real-world clinical impact.
Comments
Join the discussion with an anonymous comment.