Why the Quality of AI Research Matters as Much as the Results
The volume of published research on artificial intelligence in clinical medicine has expanded at a pace that few subfields have matched. But volume and reliability are not the same thing. A growing body of meta-research now asks a question that clinicians and regulators cannot afford to ignore: how much of this evidence is actually fit for purpose?
This article takes a meta-research perspective, drawing primarily on a large-scale overview of 161 systematic reviews (SRs) encompassing approximately 7,672 primary studies on AI in clinical medicine, published up to January 2024. The analysis, published in Frontiers in Digital Health in March 2025, applies a novel classification framework called CLASMOD-AI to assess how completely these reviews report critical AI-specific methodological details. The findings are sobering: the evidence base is far less robust than the publication count suggests.
The Growth Trajectory of AI in Clinical Medicine
The number of AI-related clinical research publications has followed a clear quadratic growth curve, with a marked acceleration beginning around 2018. The overview of reviews identified an average annual growth rate of approximately 10.4% in the volume of published systematic reviews on AI in clinical medicine. This trajectory places AI among the fastest-growing topics in the biomedical literature.
The 161 SRs included in the analysis collectively cover 7,672 primary studies, providing a broad lens on the field. However, the sheer scale of this literature also creates a problem: the more studies are published, the harder it becomes for clinicians, researchers, and policymakers to distinguish methodologically sound evidence from work that is incomplete or misleading. The growth in volume has not been matched by a corresponding improvement in reporting standards.
Which Medical Fields and Clinical Processes Are Being Studied?
AI research in clinical medicine is not evenly distributed. The overview of reviews mapped studies across 41 distinct medical fields, but a small number of specialties account for a disproportionate share of the literature.
| Medical Field | Proportion of SRs | Clinical Process | Proportion of Studies |
|---|---|---|---|
| Oncology | 13.9% | Diagnosis | 44.4% |
| Neurology | 7.9% | Prognosis | 13.9% |
| Radiology | 7.9% | Screening | 9.3% |
| Gastroenterology | 6.2% | Treatment monitoring | 8.0% |
| Cardiology | 5.6% | Risk stratification | 6.2% |
Diagnosis dominates as the clinical process of interest, accounting for 44.4% of all studies. This concentration is not surprising — AI's pattern-recognition capabilities align naturally with diagnostic tasks, particularly in imaging-heavy fields like radiology and pathology. But the imbalance also means that other critical clinical processes — such as treatment selection, prognosis, and monitoring — are comparatively underexplored in the AI literature. Researchers and funders should consider whether the current distribution reflects genuine clinical need or simply the path of least resistance in terms of data availability and study design.
CLASMOD-AI Analysis: What Key AI Metrics Are Missing?
To assess the completeness of AI-specific reporting, the overview of reviews applied the CLASMOD-AI classification framework, which evaluates four essential items: input data type, AI model type, model training type, and performance metrics. The results reveal a significant gap between what is reported and what is needed for reproducibility and clinical evaluation.
| CLASMOD-AI Item | Reporting Rate |
|---|---|
| AI model type | 84.5% |
| Input data type | 72.8% |
| Performance metrics | 68.9% |
| Model training type | 25.6% |
| All four items | 15.5% |
The most striking finding is that only 15.5% of SRs reported all four CLASMOD-AI items. While AI model type was reported in 84.5% of reviews, model training type — a critical detail for understanding how an algorithm was developed and whether it is likely to generalize — was reported in only 25.6%. This means that in nearly three-quarters of systematic reviews, readers cannot determine whether the AI model was trained using supervised, unsupervised, semi-supervised, or reinforcement learning approaches.

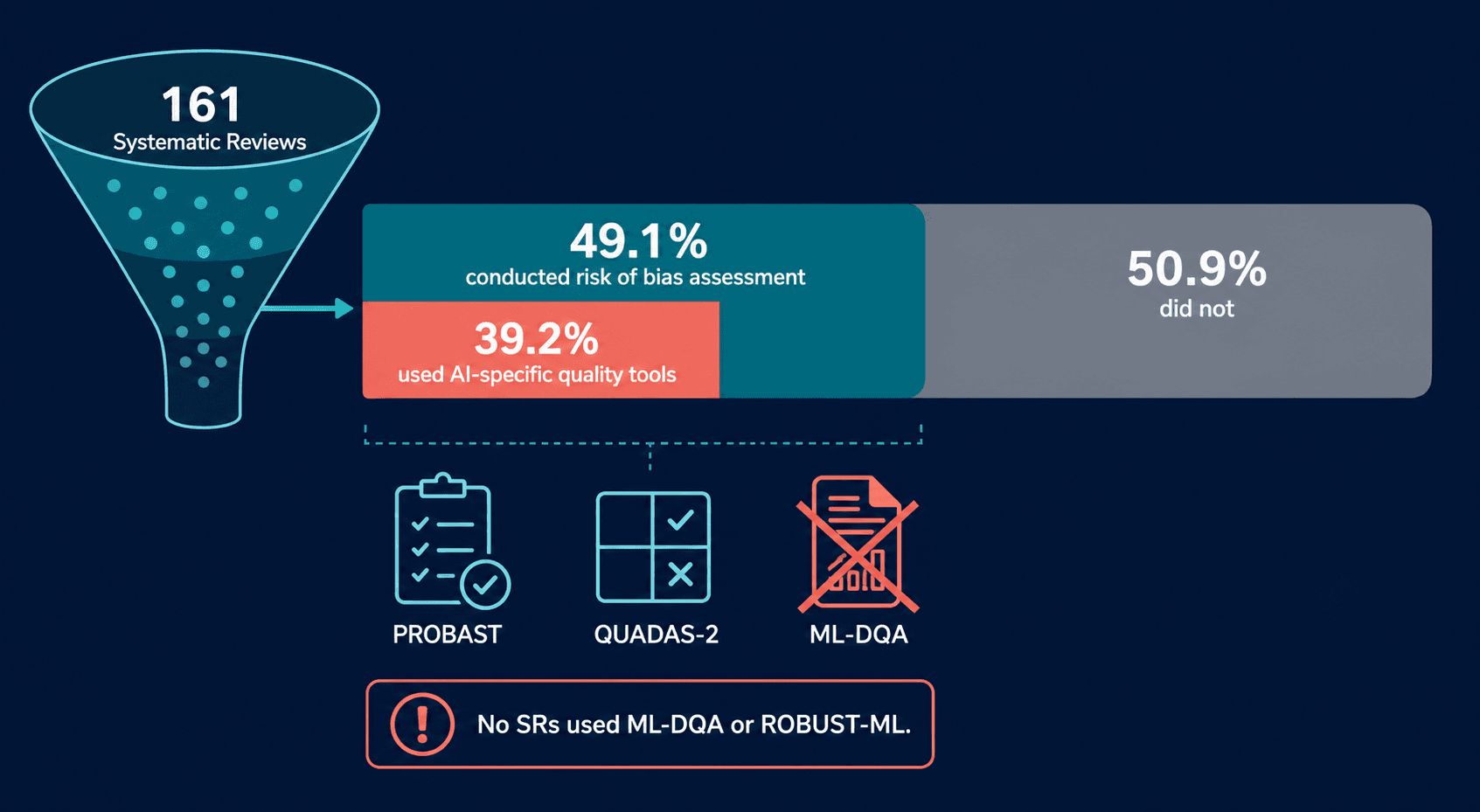
Risk of Bias Assessment: A Critical Gap
Risk of bias (ROB) assessment is a cornerstone of evidence-based medicine. Without it, systematic reviews risk aggregating flawed primary studies and producing misleading conclusions. The overview of reviews found that only 49.1% of the 161 SRs conducted any form of risk of bias assessment. Among those that did, only 39.2% used AI-specific quality assessment tools.
| Quality Assessment Dimension | Finding |
|---|---|
| SRs that assessed risk of bias | 49.1% |
| Of those, used AI-specific ROB tools | 39.2% |
| SRs using PROBAST or QUADAS-2 | Partial adoption |
| SRs using ML-DQA or ROBUST-ML | 0% |
The implications are serious. More than half of all systematic reviews on AI in clinical medicine have not assessed whether the primary studies they include are at risk of bias. And among those that did, nearly two-thirds used generic quality assessment tools that were not designed for AI studies. Generic tools like the Cochrane ROB tool or the Newcastle-Ottawa Scale do not capture AI-specific sources of bias, such as data leakage, class imbalance, or inappropriate validation strategies.
Dataset Quality: The Missing Foundation
Perhaps the most concerning finding is that no systematic review in the analysis used dedicated dataset quality assessment tools such as ML-DQA (Machine Learning Data Quality Assessment) or ROBUST-ML (Risk Of Bias USing a Tool for Machine Learning). These tools are specifically designed to evaluate the quality, representativeness, and potential biases in the datasets used to train and validate AI models.
Dataset quality is foundational to AI model performance. A model trained on a narrow, homogeneous dataset may achieve high accuracy in a controlled research setting but fail catastrophically when deployed on a diverse patient population. Without systematic assessment of dataset quality, systematic reviews cannot adequately evaluate the generalizability or equity implications of the AI models they summarize.
Geographic Distribution and Its Implications
The production of AI clinical research is geographically concentrated. The overview of reviews found that the United Kingdom (12.4%), China (11.8%), and Italy (10.6%) were the leading contributors of systematic reviews. Notably, no first authors from any African country were identified among the 161 SRs.
| Country / Region | Proportion of SRs (Clinical Medicine) |
|---|---|
| United Kingdom | 12.4% |
| China | 11.8% |
| Italy | 10.6% |
| United States | 9.3% |
| Canada | 6.8% |
| African countries (first authors) | 0% |
This geographic concentration has direct implications for the generalizability of AI clinical evidence. Populations in high-income countries differ from those in low- and middle-income countries in ways that matter for AI performance: disease prevalence, imaging equipment, clinical workflows, and demographic composition. A model validated only on data from the UK or China may not perform reliably in sub-Saharan Africa or South Asia.
A similar pattern appears in AI drug discovery research. A systematic review of 173 studies on AI in drug discovery, published in Pharmaceuticals in June 2025, found that 72.1% of studies originated from the United States, with no studies from Africa or South America. This parallel suggests that geographic concentration is not limited to clinical AI but is a broader feature of AI research in biomedicine.
Recommendations for Improved Reporting and Evaluation
The gaps identified in this analysis are not insurmountable, but they require coordinated action from researchers, systematic review authors, journal editors, and regulatory professionals. The following recommendations are drawn from the methodological analysis and are intended to raise the baseline quality of AI clinical research.
- Mandate AI-specific risk of bias tools. Journal editors and peer reviewers should require that systematic reviews on AI clinical applications use tools designed for AI studies, such as PROBAST or QUADAS-2. Generic ROB tools are insufficient.
- Adopt dataset quality assessment frameworks. The complete absence of tools like ML-DQA and ROBUST-ML in the literature must be addressed. Funding agencies and review bodies should encourage or require their use in SRs of AI studies.
- Standardize reporting of CLASMOD-AI metrics. All four key items — input data type, AI model type, model training type, and performance metrics — should be reported in every systematic review. The current 15.5% compliance rate is unacceptable.
- Require geographic and demographic diversity reporting. Systematic reviews should explicitly document the geographic distribution and demographic composition of primary study populations. This information is essential for assessing generalizability and equity.
- Encourage prospective registration of AI systematic reviews. Registration in PROSPERO or a similar registry, with a pre-specified analysis plan, can reduce reporting bias and improve methodological transparency.
- Develop and validate improved AI-specific quality assessment tools. The CLASMOD-AI framework is proposed ad interim and has not yet been formally validated. The research community should prioritize the development and validation of robust, widely accepted tools for evaluating AI clinical evidence.
The exponential growth of AI in clinical medicine is a sign of the field's promise, but it also creates an urgent need for methodological rigor. Without systematic improvements in how AI research is conducted, reported, and evaluated, the gap between published performance and real-world reliability will continue to widen. The tools to close this gap exist — what is needed is the collective will to use them.
Comments
Join the discussion with an anonymous comment.