Fewer Than 1%: The Central Fact
Ten thousand four hundred sixty-two. That is the number of machine learning algorithms cataloged across 220 systematic reviews in healthcare, published through early 2023 (Kolasa et al.). The number might suggest a maturing evidence base. It does not. I look first at validation status, not the AUC. And what I find: fewer than 1% of these algorithms ever underwent external validation on independent data. Only 53% reported any form of internal validation. Fewer than 1% — that is the story. Not a minor caveat. It means 99% of the published machine learning literature cannot support a pooled estimate of clinical performance.
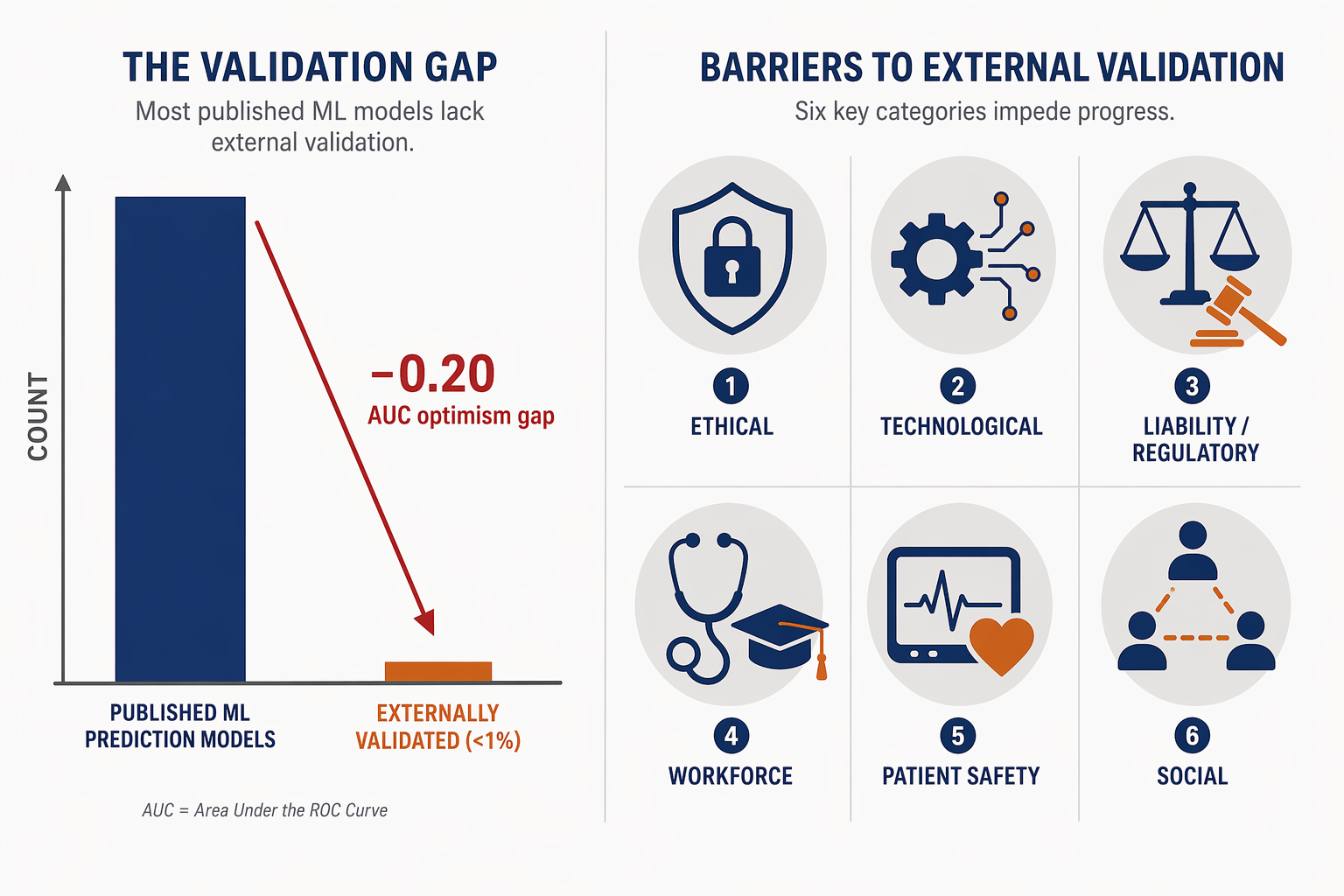
A 0.20 AUC Drop – From Clinical Use to Below Threshold
You might believe internal validation is sufficient — that cross-validation on a single dataset gives you a reliable performance estimate. I have watched models report 0.90 AUC on development data and drop to 0.70 when tested on a different population. That is not a statistical footnote. It is the difference between a tool that helps and one that misleads. The optimism gap between internal and external validation can reach 0.20 in AUC (Wynants et al., 2020, as cited in Yankam, 2026). Driven by overfitting, narrow training populations, and data leakage — a separate problem we will get to. The point: the <1% external validation rate is not a marginal oversight. It undermines nearly every headline performance claim in the field.
Missing Metrics: What You Cannot Pool
Even if every model had external validation, you still could not pool most of them. Look at the numbers from the same systematic review: 44% of studies lacked any reported accuracy metric, 72% omitted sensitivity, 75% omitted specificity (Kolasa et al., 2023). I cannot meta-analyze what was never written. These are not minor omissions — they systematically block quantitative synthesis. The evidence gap is multi-layered.
| Metric | Studies Omitting It |
|---|---|
| Accuracy | 44% |
| Sensitivity | 72% |
| Specificity | 75% |
Data Leakage: Internal Validity Undermined
You might now think at least the internally validated studies are sound. They are not necessarily. Data leakage — where information from the test set contaminates the training process — affects up to 40% of imaging-based machine learning studies (Cacciamani et al., 2023, as cited in Yankam, 2026). The most common form: patients appearing in both training and test sets, inflating performance. This is distinct from the optimism gap. It undermines even the internal performance estimate itself. For a large fraction of imaging studies, the published AUC is inflated by design.
Why ML Studies Don’t Pool – Three Dimensions
Even if all the above problems were fixed — full external validation, complete reporting, no leakage — meta-analysis of ML studies would still face a fundamental challenge: heterogeneity. Drug trials compare a fixed molecule against placebo across similar populations. Machine learning studies vary along at least three dimensions that make simple pooling indefensible.
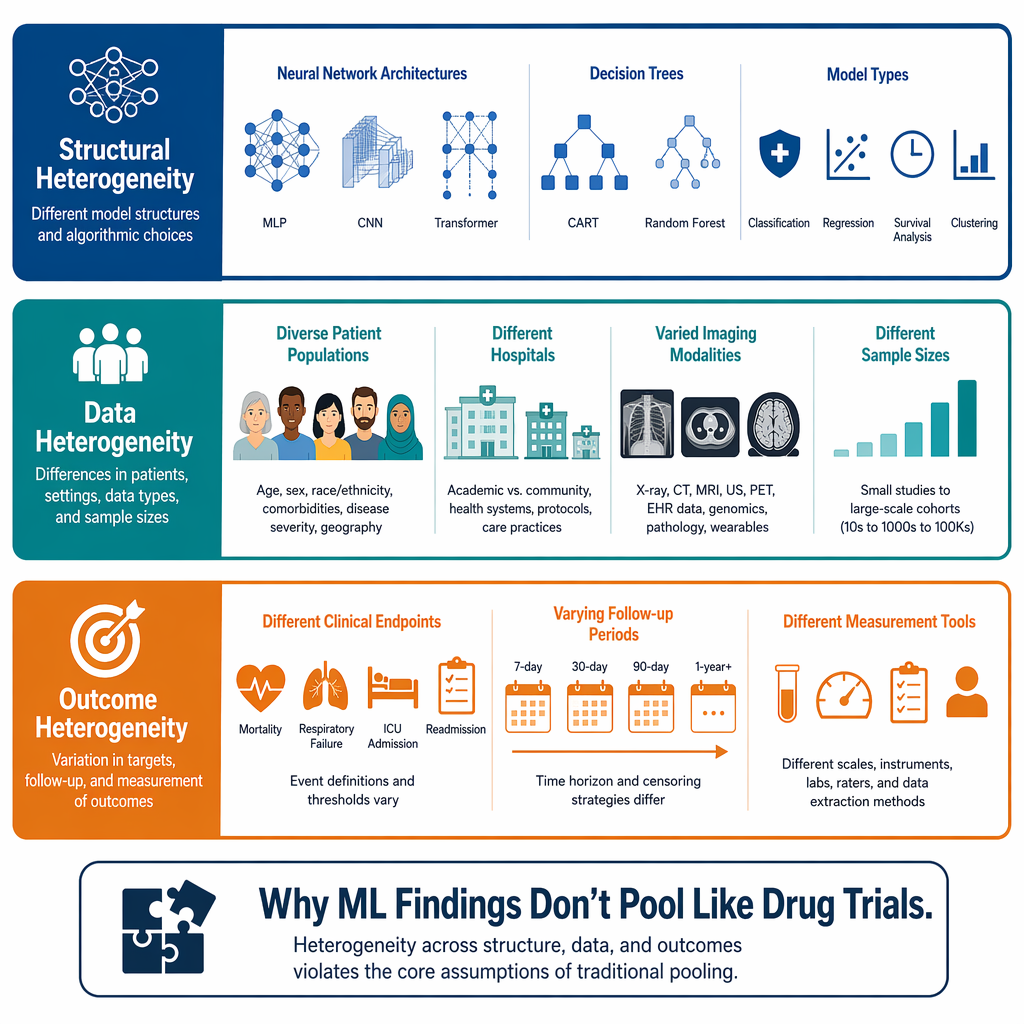
Structural heterogeneity: a neural network, a support vector machine, and a random forest are different tools. The review by Kolasa found neural networks used in 2,454 algorithms, SVMs in 1,578, and random forests in 1,522. You cannot treat a convolutional neural network for chest X-rays and a gradient-boosted model for lab values as comparable studies.
Data heterogeneity: populations, sample sizes, and imaging protocols differ wildly. A model trained on 50,000 patients from a single academic center is not the same as one trained on 500 patients from a community hospital.
Outcome heterogeneity: the definition of the endpoint — what constitutes a positive case, what follow-up window is used — varies across studies. In oncology, one study might use progression-free survival; another uses overall survival. These are not interchangeable.
The standard meta-analytic approach, which assumes studies estimate the same underlying effect, is simply inappropriate for the current ML literature.
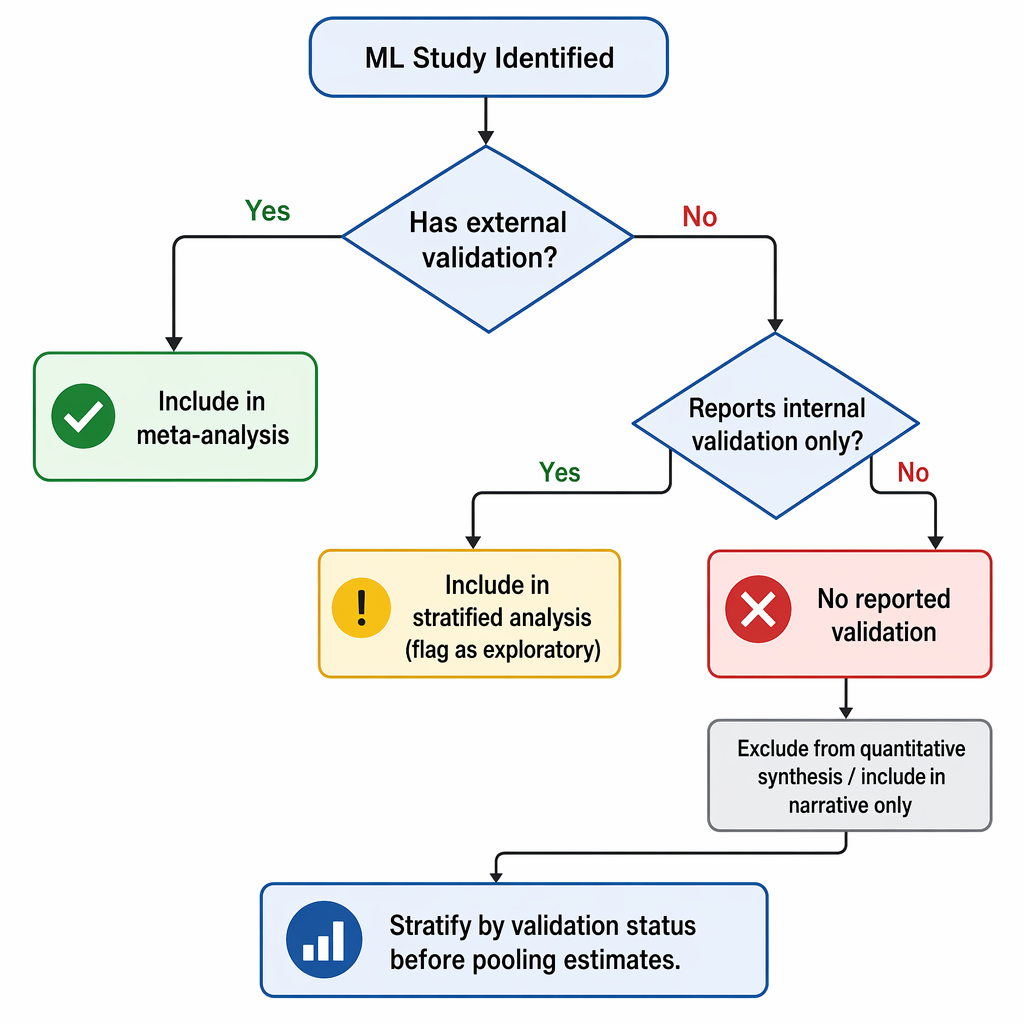
The 25% Rule for Systematic Reviewers
So what is a systematic reviewer to do? The Yankam review proposes a clear threshold: when fewer than 25% of included studies have external validation, only narrative synthesis is methodologically defensible (Yankam, 2026). I agree. It is a rule, not a suggestion. If this rule had been applied to the 220 systematic reviews in the Kolasa dataset, over half of them — the 53% that did not even conduct a quality assessment — would have been forced to reconsider their conclusions.
PROBAST+AI: Hope Depends on Enforcement
Three recent frameworks aim to impose the discipline that has been missing. PROBAST+AI (Moons et al., 2025) provides a structured bias assessment tool for ML prediction models. TRIPOD+AI (Collins et al., 2024) updates reporting guidelines for regression and machine learning models. PRISMA-AI (Cacciamani et al., 2023) extends PRISMA to systematic reviews of AI in healthcare (Yankam, 2026). I am hopeful these can enforce discipline. But hope is not evidence. The field has had reporting guidelines before — TRIPOD was published in 2015 — and adherence remains suboptimal. Their impact depends entirely on journal and funder mandates.
- PROBAST+AI: systematic bias assessment for ML prediction model studies.
- TRIPOD+AI: reporting guidelines for clinical prediction models using regression or machine learning.
- PRISMA-AI: reporting guidelines for systematic reviews and meta-analyses of AI in healthcare.
This Inference Does Not Hold
Here is where I stand. The machine learning in healthcare literature contains over ten thousand algorithms, fewer than one percent externally validated. The typical optimism gap is 0.20 AUC. Reporting gaps mean most studies cannot be used for meta-analysis even if they were validated. Data leakage inflates internal performance. Heterogeneity prevents simple pooling. And most systematic reviews compound these problems by treating all models as comparable.
The tools to change this exist: stratify by validation status, apply the 25% threshold, mandate PROBAST+AI and TRIPOD+AI, require code and data sharing. But change will not happen automatically. It requires systematic reviewers to enforce methodological standards, journal editors to reject papers that omit basic metrics, and funders to demand independent validation before claiming clinical utility.
Until then, the most honest thing any reviewer can write is: 'This inference does not hold.'
Comments
Join the discussion with an anonymous comment.