The Efficiency Promise vs. The Evidence
The pitch is familiar to anyone who has sat through a vendor demonstration or read a radiology AI press release: deploy this tool, and your radiologists will read faster, clear their worklists sooner, and go home less exhausted. Burnout reduction, productivity gains, and workflow acceleration are marketed as near-automatic byproducts of AI adoption. But when you strip away the marketing language and look at the peer-reviewed evidence from actual clinical deployments, the picture becomes considerably more complicated.
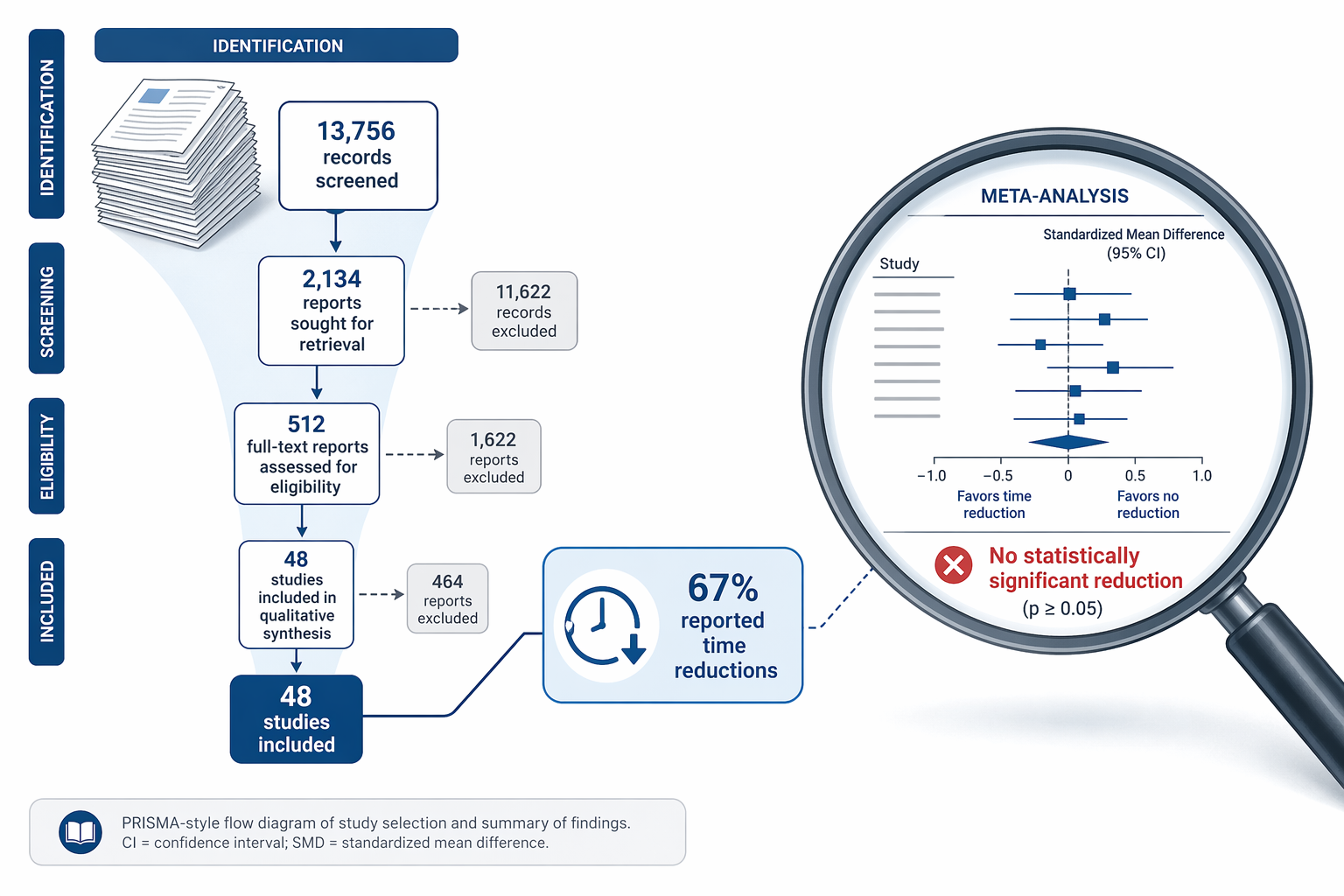
A comprehensive 2024 systematic review and meta-analysis published in npj Digital Medicine by Wenderott et al. provides the most rigorous examination to date of whether AI actually saves time in medical imaging. The review screened over 13,700 records and identified 48 real-world clinical studies that measured efficiency outcomes. The headline finding is as provocative as it is counterintuitive: while 67% of the studies that measured task time reported reductions with AI, three separate meta-analyses — covering CT reading time, colonoscopy procedure time, and triage turnaround time — all failed to find a statistically significant effect.
For readers who want a broader overview of how AI is being deployed across clinical workflow categories — image triage, ambient documentation, clinical decision support — the site's existing overview article provides that context. This article drills into one specific, high-stakes question: does the real-world evidence support the claim that AI saves time in medical imaging workflows?
How the Systematic Review Was Conducted
To understand why the efficiency evidence is weaker than many assume, it helps to start with the methodology that produced the finding. Wenderott et al. conducted a systematic literature review following PRISMA guidelines, searching multiple databases for studies published through early 2024. The initial search returned 13,756 records. After deduplication and screening, 48 studies met the inclusion criteria for full analysis.

The inclusion criteria were deliberately restrictive. The review only included studies that evaluated AI tools deployed in real-world clinical settings — not laboratory simulations, retrospective analyses of curated datasets, or phantom studies. This is a critical distinction: a model that achieves a 0.99 AUC on a cleaned research dataset may perform very differently when integrated into a busy PACS environment with variable image quality, diverse patient populations, and real-world workflow interruptions.
The efficiency outcomes measured fell into several categories: reading time (the time a radiologist spends interpreting a study), procedure time (for interventional or endoscopic procedures), turnaround time (the interval from study acquisition to report availability), and workload (a broader construct encompassing cognitive load, task counts, and multi-tasking demands). Of the 48 included studies, 33 measured some form of task time, making this the most commonly assessed efficiency metric.
The Headline Finding: 67% Report Reductions, But Meta-Analyses Show No Significant Effect
At first glance, the individual study results appear encouraging. Of the 33 studies that measured time for specific tasks, 22 — or 67% — reported reductions when AI was used. This is the figure most commonly cited by vendors and in conference presentations. It suggests a clear, consistent benefit.
However, individual study results can be misleading when study designs, settings, and measurement methods vary widely. To address this, the review team conducted three meta-analyses on subsets of studies that were sufficiently comparable to pool statistically. The results are striking:
| Meta-Analysis | Studies Pooled | Standardized Mean Difference (SMD) | 95% CI | p-value | I² (Heterogeneity) |
|---|---|---|---|---|---|
| CT reading time | 4 | -0.60 | -2.02 to 0.82 | 0.30 | 96.35% |
| Colonoscopy procedure time | 4 | -0.04 | -0.76 to 0.67 | 0.87 | 99.45% |
| Triage turnaround time (ICH flagged positive) | 4 | 0.03 | -0.50 to 0.56 | 0.84 | 83.75% |
For readers less familiar with meta-analytic statistics: a standardized mean difference (SMD) of -0.60 for CT reading time suggests a moderate-to-large effect in favor of AI, but the confidence interval crosses zero (-2.02 to 0.82), and the p-value of 0.30 means we cannot rule out that the observed difference is due to chance. The extremely high I² values — 96% for CT reading time, 99% for colonoscopy time — indicate that the variability between studies is far greater than what would be expected from random sampling alone. In plain language: the studies are measuring different things in different ways, making a pooled estimate unreliable.
The triage turnaround time result is particularly instructive. For intracranial hemorrhage detection — one of the most well-studied AI triage applications — the SMD was 0.03, essentially zero, with a confidence interval spanning from a moderate benefit to a moderate harm. This does not mean AI triage never reduces turnaround time; it means the current body of real-world evidence does not consistently demonstrate a statistically significant reduction.
Why the Disconnect? Workflow Integration, Study Heterogeneity, and Risk of Bias
The gap between the 67% figure and the non-significant meta-analyses is not a contradiction — it is a signal that the efficiency question is more nuanced than a simple yes-or-no answer. Three factors explain most of the disconnect.
Workflow Integration Mode: How AI Is Embedded Matters
AI can be integrated into clinical workflows in at least four distinct modes, and the mode of integration has a direct impact on potential time savings:
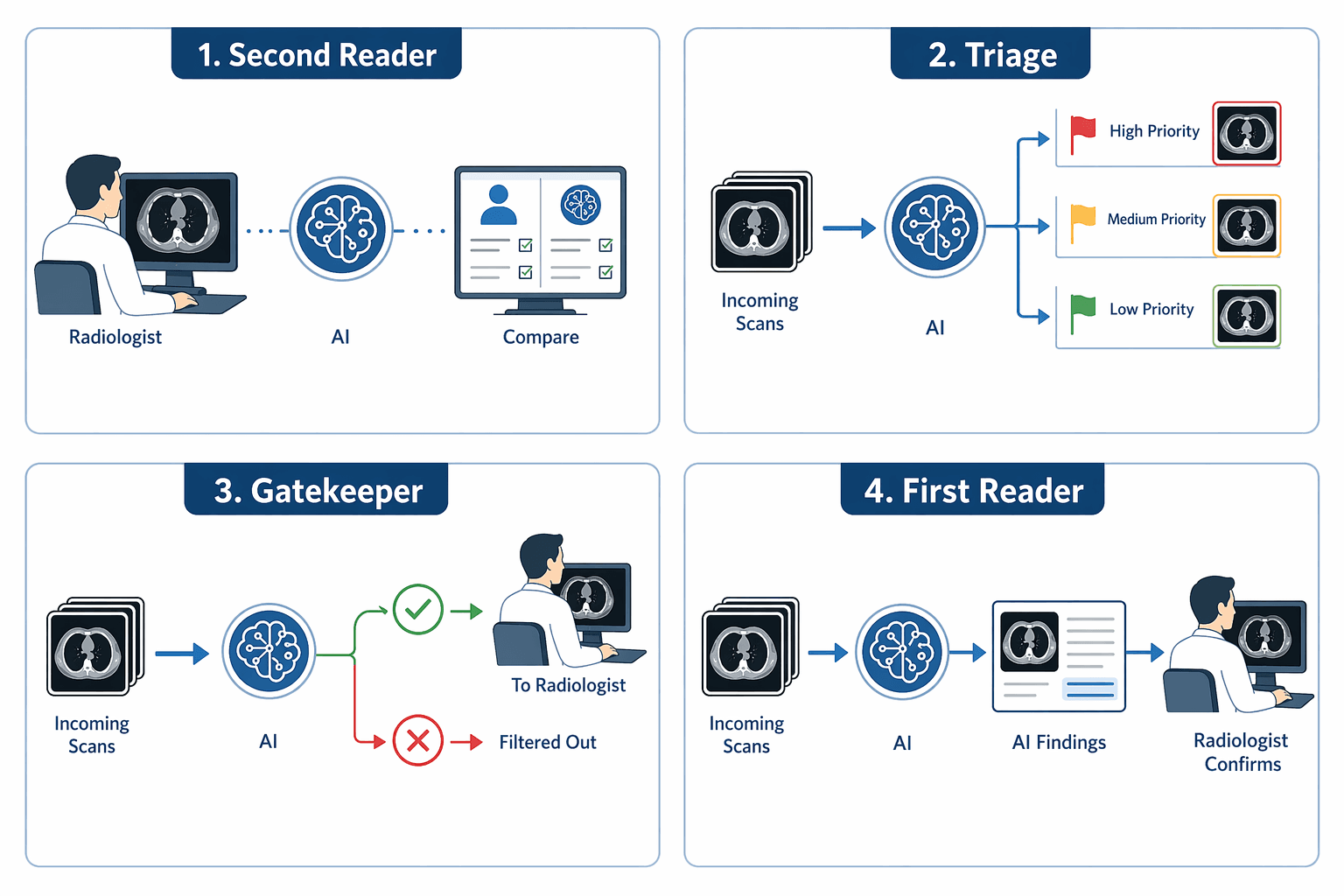
- Second Reader: The AI analyzes the image concurrently or sequentially with the radiologist, who reviews both the original image and the AI output before making a final interpretation. This is the most common deployment mode, accounting for 35% of studies in the review. Because the radiologist still reviews every case, time savings depend on whether the AI reduces the need for additional views, measurements, or consultations — not on eliminating the primary read.
- Triage: The AI prioritizes incoming studies, flagging those with suspected critical findings (e.g., intracranial hemorrhage, pulmonary embolism) for immediate review. Non-urgent studies are read in normal order. This mode has the potential to reduce turnaround time for critical findings, but it does not necessarily reduce total reading time across all studies.
- Gatekeeper: The AI filters out clearly normal studies, allowing them to bypass the radiologist entirely. This mode has the greatest potential for time savings, but it also carries the highest risk of missed findings and is the least commonly deployed in practice due to regulatory and liability concerns.
- First Reader: The AI generates a preliminary interpretation that the radiologist reviews and edits. This mode is emerging in specific applications but remains rare in real-world deployment.
The dominance of the second-reader mode — where the radiologist's workflow is augmented but not fundamentally shortened — may explain why time savings are modest and inconsistent. For a deeper examination of how triage and second-reader roles differ in practice, see the site's analysis of AI chest X-ray triage in the emergency department.
Study Heterogeneity: Apples, Oranges, and PACS Workstations
The 48 studies in the review covered different imaging modalities (CT, MRI, X-ray, ultrasound, mammography, colonoscopy), different clinical tasks (detection, classification, segmentation, triage), different healthcare settings (academic medical centers, community hospitals, outpatient imaging centers), and different baseline workflows (some sites had dedicated CT technologists, others did not). A study showing a 30% reduction in CT reading time at a high-volume academic center with a dedicated AI-integrated PACS may not generalize to a community hospital where the AI output appears in a separate viewer.
The I² values in the meta-analyses — 96%, 99%, and 84% — quantitatively confirm what any practicing radiologist would suspect: the studies are too heterogeneous to produce a single, reliable estimate of effect. This does not mean the individual studies are wrong; it means their results cannot be meaningfully averaged.
Risk of Bias: A Methodological Red Flag
Perhaps the most concerning finding from the review is the risk of bias assessment. Using the ROBINS-I tool for non-randomized studies, the reviewers found that only 1 of 45 studies was rated 'low' risk of bias. The remaining 44 studies were distributed as follows: 62% rated 'serious' risk and 27% rated 'critical' risk.
The risk of bias distribution also helps explain the disconnect between individual study results and meta-analytic conclusions. Studies with higher bias are more likely to report positive results — a well-documented phenomenon across biomedical research. When the meta-analysis pools only the most comparable, least biased studies, the effect size shrinks and the confidence interval widens.
The Workload Blind Spot: Only 3 of 48 Studies Measured It
If the primary motivation for adopting AI in medical imaging is to reduce radiologist burnout and improve quality of work life, then the most relevant outcome to measure is not just reading time — it is workload. Workload encompasses cognitive load, task switching frequency, the number of studies read per shift, the complexity of those studies, and the subjective experience of fatigue and stress.
Yet only 3 of the 48 studies in the review assessed workload beyond simple time measurements. This is a critical gap. A tool that reduces reading time by 10% but increases cognitive load — because the radiologist must now cross-check AI outputs, dismiss false positives, or navigate an additional software interface — may not improve the clinician's experience at all. It may even make it worse.
The absence of workload data is particularly striking given that 19 of the 48 studies declared a relevant conflict of interest — typically vendor funding or author employment by an AI company. While industry-funded research is not inherently unreliable, the lack of independent, non-vendor-affiliated studies on workload outcomes means the evidence base is skewed toward the metrics that vendors are most motivated to measure and report.
Lessons for Clinical Adoption: Workflow Design Matters More Than Algorithm Accuracy
The evidence from Wenderott et al. does not suggest that AI has no role in improving medical imaging efficiency. It suggests that efficiency is not an automatic property of AI deployment — it is an outcome of thoughtful workflow integration, and it must be measured, not assumed.
For radiologists, administrators, and health IT professionals evaluating AI tools, several practical lessons emerge from this evidence:
- Prioritize workflow integration mode over algorithm accuracy. A model with a slightly lower AUC that is deployed as a gatekeeper or triage tool may produce greater time savings than a more accurate model deployed as a second reader. The mode of integration — not the standalone performance metric — is the primary determinant of workflow impact.
- Run site-specific pilots with workload measurement. The heterogeneity across studies means that results from one institution may not transfer to another. Pilots should measure not just reading time and turnaround time, but also cognitive load, error rates, and clinician satisfaction. Without these data, it is impossible to know whether the AI is actually improving the work experience.
- Be skeptical of single-study claims. A single study showing a 30% reduction in reading time may be real, but it may also reflect the specific conditions of that site, the particular patient population, or methodological limitations. Look for meta-analyses or systematic reviews that pool multiple studies and assess risk of bias.
- Consider the total workflow cost. AI tools require integration effort, staff training, ongoing model monitoring, and management of false positives. These costs can offset time savings. A tool that saves 30 seconds per study but requires 10 minutes of daily troubleshooting may be a net negative for workflow efficiency.
- Align AI deployment with specific efficiency goals. If the goal is to reduce turnaround time for critical findings, triage-mode AI is the appropriate choice. If the goal is to reduce overall reading time for high-volume screening exams, gatekeeper or first-reader modes may be more appropriate — but these come with higher regulatory and liability considerations.
The broader context of AI adoption in healthcare — including investment trends, real-world ROI data, and the gap between vendor promises and documented outcomes — is explored in the site's 2026 health AI market analysis. That article provides the market-level context for the clinical evidence discussed here, including data on adoption rates, funding patterns, and the persistent challenges of demonstrating ROI in real-world settings.
The central lesson of the Wenderott et al. review is not that AI fails to save time — it is that the evidence for time savings is far weaker than the marketing suggests, and that the field urgently needs higher-quality studies that measure the right outcomes in the right ways. Until those studies exist, institutions should approach efficiency claims with the same rigor they apply to diagnostic accuracy claims: demand the evidence, examine the methodology, and pilot before purchasing.
Comments
Join the discussion with an anonymous comment.