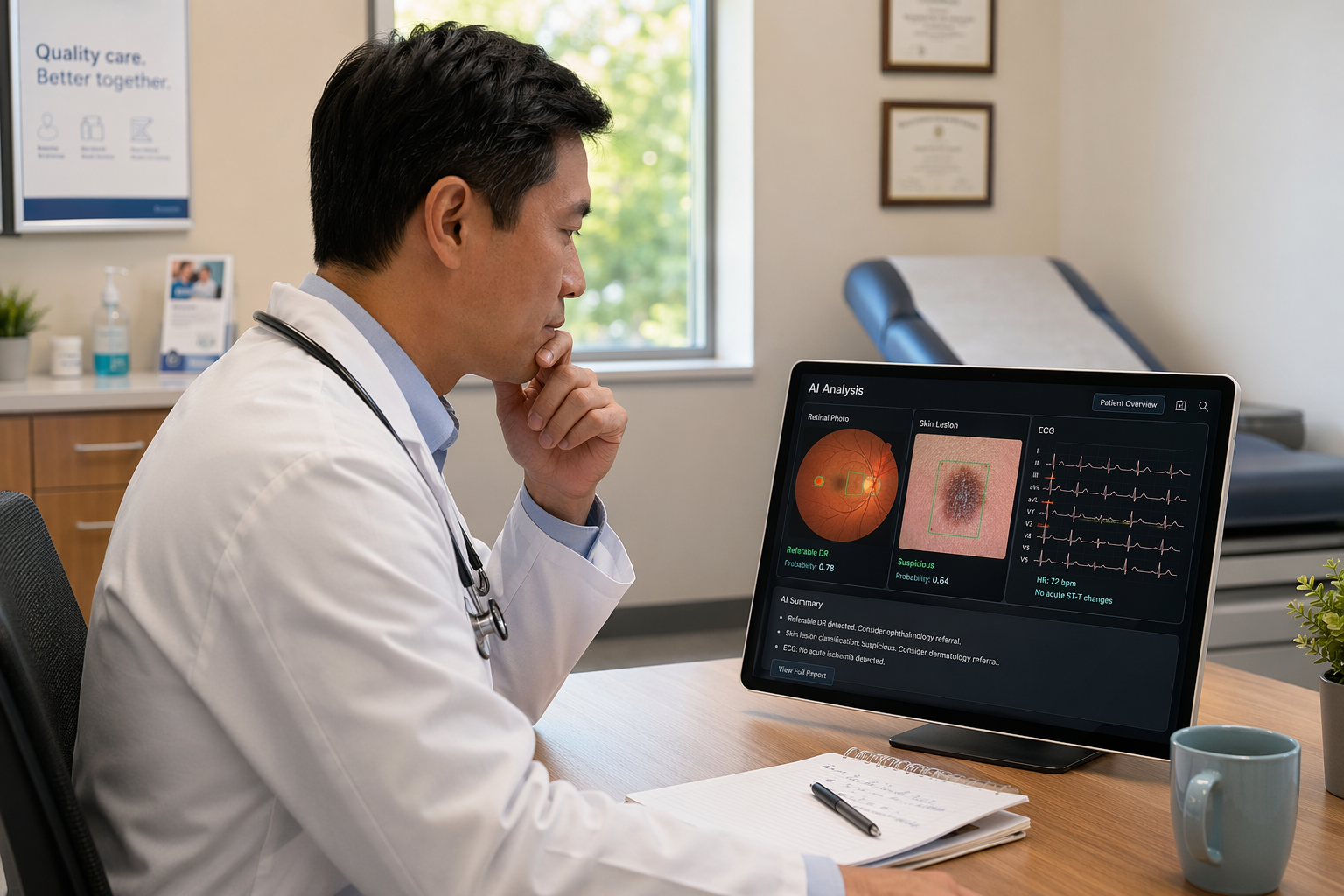
Executive Summary: The State of AI Screening in Primary Care
Artificial intelligence is being positioned as a solution to some of primary care's most persistent challenges: diagnostic delays, specialist access bottlenecks, and the cognitive load of managing broad, undifferentiated patient populations. But the evidence base for AI screening tools is not uniform. This article examines four distinct modalities — diabetic retinopathy screening, skin cancer detection, ECG interpretation for ventricular dysfunction, and multimodal conversational AI — each at a different stage of evidence maturity.
The central tension running through all four is the gap between simulated performance and real-world deployment. Google's AMIE system, for example, outperformed board-certified primary care physicians on 29 of 32 evaluation axes in controlled telehealth simulations, yet the State of Clinical AI 2026 report from the ARISE network found that only 5% of more than 500 reviewed AI studies used real patient data. The spectrum effect — where algorithms trained on high-prevalence specialist populations fail in low-prevalence primary care settings — further undermines generalizability. For clinicians and health system planners evaluating these tools, understanding where the evidence is robust and where it remains aspirational is essential.
Diabetic Retinopathy Screening: The Most Mature AI Application in Primary Care
Diabetic retinopathy (DR) screening using AI-powered fundus image analysis is the most extensively validated AI application in primary care. The Lancet Review (Laranjo et al., 2025) describes it as "one of the first successful applications of AI in clinical care, enhancing the availability of specialist-level testing in the community and primary care settings, particularly in low-income and middle-income countries." Multiple trials have demonstrated that deep learning algorithms can match or exceed the sensitivity of human graders when analyzing retinal photographs.
Key studies include Bellemo et al. (Lancet Digital Health, 2019) and Xie et al. (2020), both of which validated AI-based DR screening in real-world primary care and community settings, including in low- and middle-income countries where ophthalmologist access is limited. These studies demonstrated that AI could reliably detect referable DR, reducing the need for specialist review of normal images.
- Multiple FDA-cleared devices now exist for automated DR detection from fundus photographs, including IDx-DR (now LumineticsCore) and EyeArt.
- Real-world deployment has expanded to community health centers and retail clinic settings, though implementation challenges — including workflow integration, image quality failure rates, and follow-up compliance — remain significant.
- The evidence base includes prospective studies and RCTs, making DR screening the only modality in this review with large-scale, primary-care-specific validation data.
For a comprehensive review of RCT evidence, FDA-cleared devices, and real-world deployment gaps, see the site's dedicated analysis: AI for Diabetic Retinopathy Screening: RCT Evidence, FDA-Cleared Devices, and Real-World Deployment Gaps. For implementation realities and equity evidence in community health centers, see AI Diabetic Retinopathy Screening at Community Health Centers: Implementation Realities, Equity Evidence, and Deployment Guidance.
Skin Cancer Detection: The Spectrum Effect and the Primary Care Data Gap
AI-based skin lesion classification has achieved impressive accuracy in controlled studies using dermoscopic images from dermatology clinics. However, a systematic review by Jones et al. (Lancet Digital Health, 2022) found that only 2 of 272 included studies used training data from clinical settings with a low prevalence of skin cancers — that is, settings resembling primary care. This is a textbook example of the spectrum effect: algorithms perform differently when the disease prevalence and case mix shift from the training population.
In primary care, the vast majority of skin lesions are benign. An algorithm trained on dermatology clinic images — where the proportion of malignant lesions is much higher — will encounter a very different distribution of visual features when deployed in a general practice. The result is typically a higher false-positive rate, which can lead to unnecessary referrals, biopsies, and patient anxiety.
| Factor | Dermatology Clinic Setting | Primary Care Setting |
|---|---|---|
| Skin cancer prevalence | 10–30% of lesions biopsied | <1% of lesions seen |
| Training data source | Dermoscopic images, high-resolution | Clinical photographs, variable quality |
| Patient demographics | Referred, higher-risk populations | Unselected, all ages and skin types |
| Algorithm performance risk | High sensitivity, moderate specificity | High false-positive rate likely |
Equity concerns compound the problem. The same review noted that a small proportion of studies included darker skin tones in their training datasets, raising the risk that algorithms will perform worse for patients with skin of color — a population already facing disparities in melanoma outcomes.
For a deeper examination of clinical evidence, regulatory status, and deployment limitations for AI-enabled skin lesion detection, see the site's dedicated article: AI-Enabled Skin Lesion Detection for Melanoma: Clinical Evidence, Regulatory Status, and Deployment Limitations.
ECG-Based Screening: AI-ECG for Asymptomatic Ventricular Dysfunction
AI-enhanced ECG interpretation represents one of the few screening applications with large-scale prospective data in primary care. The landmark trial by Yao et al. (Nature Medicine, 2021) evaluated an AI algorithm applied to routine 12-lead ECGs to detect asymptomatic left ventricular dysfunction — a condition that is often undiagnosed until symptoms appear. The study screened more than 20,000 primary care patients and found that AI-ECG interpretation significantly increased first-time detection of low ejection fraction compared to usual care.
The clinical rationale is strong: asymptomatic ventricular dysfunction affects an estimated 3–6% of the general population, and early detection enables guideline-directed medical therapy that can delay progression to heart failure. Standard ECG interpretation by clinicians has low sensitivity for this condition, making it a fitting target for AI augmentation.
- The Yao et al. trial is cited in the Lancet Review as one of the few AI screening studies with demonstrated impact on diagnosis rates in primary care.
- Two other trials evaluating AI for atrial fibrillation detection in primary care showed mixed or null results, underscoring that not all ECG-based screening applications have reached the same evidence threshold.
- The AI-ECG approach benefits from a well-defined clinical pathway: a positive screen leads to confirmatory echocardiography, and effective treatments exist for confirmed cases.
The AI-ECG screening model is closer to real-world deployment readiness than skin cancer AI, but questions remain about generalizability across different ECG machines, patient populations, and clinical settings. The Lancet Review notes that "AI deployment in primary care is moving ahead of evaluation and regulation" — a caution that applies even to this relatively well-studied application.
Multimodal Conversational AI: AMIE and the Gap Between Simulation and Reality
The most attention-grabbing development in AI screening for primary care in 2026 is Google's Articulate Medical Intelligence Explorer (AMIE), a multimodal conversational AI system built on Gemini 2.0 Flash. In a study published in Nature Medicine (Saab et al., May 2026), AMIE outperformed 19 board-certified primary care physicians on 29 of 32 evaluation axes across 210 simulated telehealth consultations. The AI's top-1 diagnostic accuracy reached 0.98 in a separate automated ablation analysis on clinical document scenarios.
The results are striking: specialist evaluations using the MUH rubric favored the AI in 7 of 9 metrics, and patient-actors rated the AI significantly higher across 10 of 11 GMCPQ criteria, including empathy and listening. These findings suggest that large language models can now simulate the conversational and diagnostic components of a primary care consultation with remarkable fidelity.
The gap between simulation and reality is not merely academic. The State of Clinical AI 2026 report found that nearly half of more than 500 medical AI studies tested models using medical exam-style questions, and only 5% used real patient data. Very few studies measured whether models recognized uncertainty, and even fewer examined bias or fairness. AMIE's performance in ambiguous cases — where a real patient's history is incomplete, symptoms are atypical, or multiple comorbidities interact — remains unmeasured.
For broader context on Google's AI portfolio and AMIE's positioning within it, see the site's company profile: Google Health AI in 2026: A Comprehensive Portfolio Profile.
Cross-Modality Evidence Synthesis: What the Meta-Analyses Show
A systematic review and meta-analysis published in npj Digital Medicine (Takita et al., March 2025) provides a cross-modality benchmark. Analyzing 83 studies across multiple specialties — including general medicine, radiology, ophthalmology, dermatology, and emergency medicine — the meta-analysis found an overall diagnostic accuracy of 52.1% (95% CI: 47.0–57.1%) for generative AI models. There was no significant performance difference between AI and physicians overall (p=0.10) or non-expert physicians (p=0.93), but AI performed significantly worse than expert physicians, with a difference in accuracy of 15.8% (p=0.007).
| Modality | Evidence Maturity | Primary Care Validation | Key Limitation |
|---|---|---|---|
| Diabetic Retinopathy | High — multiple RCTs, FDA-cleared devices | Yes — validated in LMIC and community settings | Image quality failure rates, follow-up compliance |
| Skin Cancer Detection | Moderate — high specialist accuracy, low primary care data | Minimal — only 2 of 272 studies used primary care data | Spectrum effect, lack of darker skin tones in training data |
| ECG Screening (LV dysfunction) | Moderate-High — large prospective trial (20,000+ patients) | Yes — Yao et al. trial in primary care | Generalizability across ECG devices and populations |
| Multimodal Conversational AI (AMIE) | Low — exploratory simulation, no RCT | No — simulated consultations only | Unmeasured real-world performance, uncertainty handling |
The meta-analysis underscores a pattern that holds across all four modalities: AI performs well in controlled settings but has not been rigorously tested in the conditions where it would actually be deployed. The Lancet Review provides a structured framework for evaluating AI across eight quality domains — effectiveness, safety, timeliness, efficiency, patient-centred care, health-care provider experience, equity, and planetary health — plus primary care-specific attributes of accessibility, comprehensiveness, coordination, and continuity. This framework offers a more nuanced evaluation than accuracy alone.
Where AI Clearly Helps: Prediction at Scale and the ARISE Framework
The State of Clinical AI 2026 report from the Stanford-Harvard ARISE network identifies a clear area of strength: "AI systems excel at identifying early warning signals across large and complex datasets." This capability — prediction at scale — is distinct from the diagnostic accuracy measured in controlled studies. It involves sifting through population-level data to flag patients who may benefit from earlier intervention, rather than making a definitive diagnosis for an individual patient.
Examples of prediction at scale in primary care include:
- Identifying patients with undiagnosed hypertension or diabetes from EHR data patterns
- Flagging individuals at risk of hospitalization or emergency department visits based on historical utilization and clinical markers
- Prioritizing patients for cancer screening based on risk stratification models
- Detecting early signals of sepsis or clinical deterioration in outpatient populations
The report also reaffirms that "AI works best as teammate, not as replacement," citing a German study where radiologists who could optionally consult an AI detected more breast cancers without increasing false alarms (Eisemann et al., Nature Medicine, 2025) and a Kenya collaboration between Penda Health and OpenAI where a background AI system reduced diagnostic and treatment errors across tens of thousands of patients (Korom et al., 2025). These examples suggest that AI's greatest impact in primary care may come from augmenting — not replacing — clinical judgment.
Gaps, Equity Concerns, and the Path to Real-World Deployment
Across all four screening modalities, several cross-cutting limitations emerge that must be addressed before AI can be reliably deployed in primary care.
- Training data not representative of primary care populations. The skin cancer literature is the most egregious example, but the problem extends to DR screening (where algorithms may underperform in patients with media opacity or small pupils) and ECG interpretation (where training data may not reflect the full range of ECG acquisition devices used in primary care).
- Lack of external validation in primary care settings. The Lancet Review notes that "AI deployment in primary care is moving ahead of evaluation and regulation." Most AI screening tools have been validated in specialist settings or curated datasets, not in the messy, low-prevalence reality of a general practice.
- Unresolved workflow integration questions. Even when AI tools perform well, integrating them into existing clinical workflows without adding to clinician burden or disrupting patient-clinician relationships remains a significant challenge. The Lancet Review emphasizes that AI must be evaluated across multiple quality domains, not just diagnostic accuracy.
- Equity concerns. Skin cancer studies have disproportionately excluded darker skin tones. DR screening access is uneven across socioeconomic groups. The State of Clinical AI 2026 report found that very few studies examined bias or fairness. Without systematic equity auditing, AI screening tools risk widening existing health disparities.
The path to real-world deployment requires primary-care-specific validation standards, systematic equity auditing, and regulatory frameworks that account for the unique characteristics of general practice — including lower disease prevalence, broader patient diversity, and the need for seamless workflow integration. For a broader evidence review across diagnostic applications, see the site's comprehensive analysis: Artificial Intelligence in Medical Diagnosis: What the Clinical Evidence Actually Shows.
Comments
Join the discussion with an anonymous comment.