 Watson for Oncology
Watson for Oncology
The Promise: Democratizing Memorial Sloan Kettering Expertise
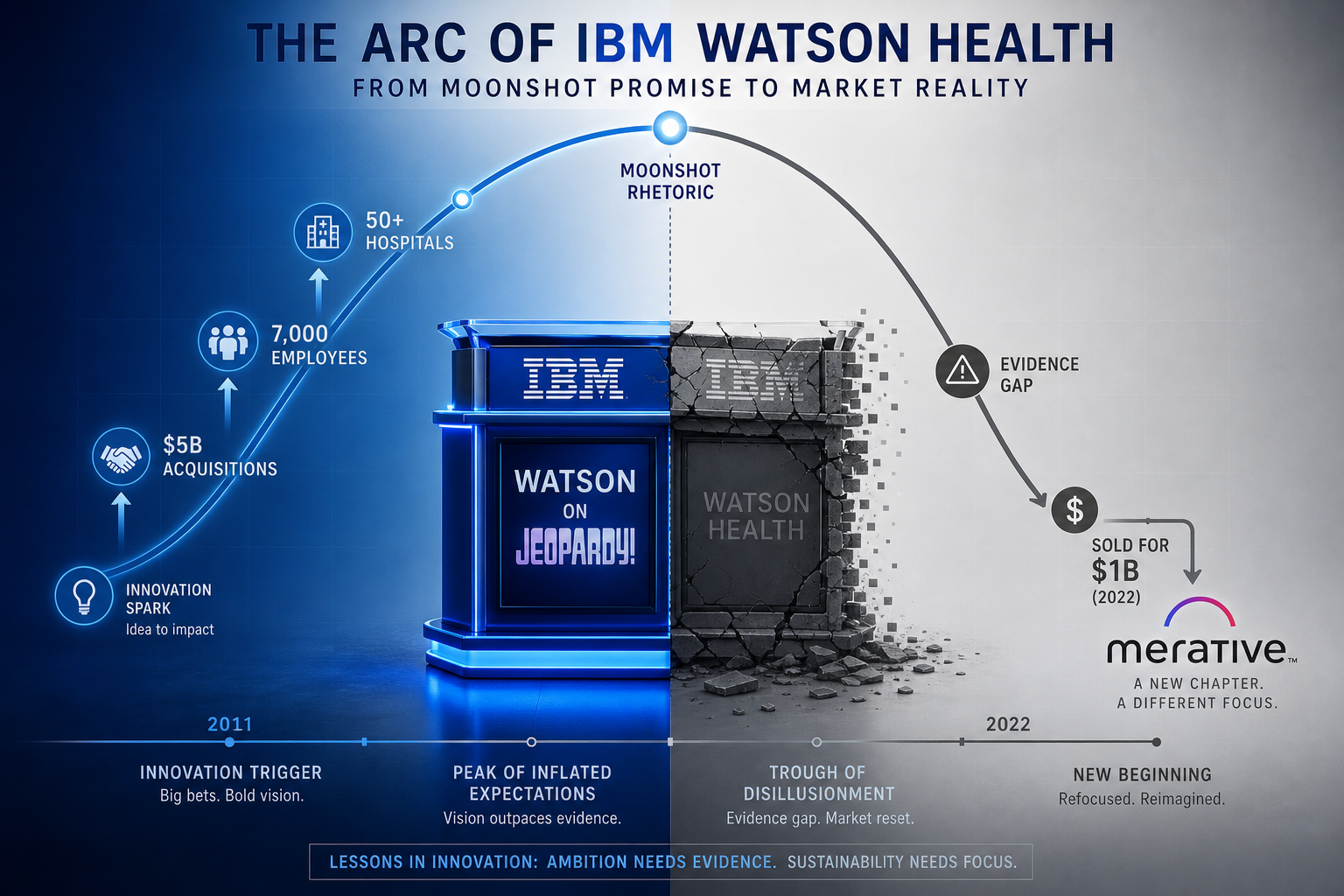
In 2011, IBM's Watson defeated two human champions on Jeopardy! and captured the public imagination. The company quickly pivoted to healthcare, announcing a partnership with Memorial Sloan Kettering (MSK) to build a "digital oncologist" that would bring MSK-level cancer expertise to clinics in underserved regions worldwide. The vision was compelling: a clinician in rural India or a community hospital in the U.S. could query Watson for Oncology (WFO) and receive treatment recommendations informed by the collective experience of one of the world's top cancer centers.
IBM backed this vision with extraordinary resources. The company spent at least $5 billion on acquisitions alone — including Truven Health Analytics for $2.6 billion and Merge Healthcare for $1 billion — to build Watson Health. At its peak, the division employed approximately 7,000 people. The narrative was intoxicating: an AI that could read 200 million pages of medical literature in seconds and recommend personalized cancer treatments better than most human physicians.
The reality, as it turned out, was far less revolutionary. By 2022, Watson Health was sold to Francisco Partners for more than $1 billion — a fraction of what IBM had invested. The MD Anderson project alone consumed approximately $62 million without producing a clinically usable system. Manipal Hospitals in India discontinued its WFO contract in December 2018. A hospital in Denmark found only ~33% concordance and dropped the project. What went wrong?
How Watson for Oncology Actually Worked
IBM's public portrayal of Watson as a self-learning AI that "reads" medical literature and generates insights from patient data was central to its marketing. The internal architecture told a different story.

According to STAT News's 2017 investigation, WFO's recommendations were based exclusively on training by approximately 20 human overseers at Memorial Sloan Kettering, not on its own data insights. These physicians input their clinical judgment into the system using synthetic cancer cases — hypothetical patient scenarios — rather than real patient data. The system took nearly six years to train in just seven cancer types.
When a clinician submitted a patient case, WFO returned one of three color-coded recommendations: green ("Recommended"), yellow ("For Consideration"), or red ("Not Recommended"). These outputs were the product of a structured knowledge base that mapped patient characteristics to treatment options based on the MSK physicians' input, not on statistical patterns learned from patient outcomes.
MSK's lead trainer, Dr. Andrew Seidman, acknowledged this openly in STAT's reporting:
We are not at all hesitant about inserting our bias, because I think our bias is based on the next best thing to prospective randomized trials, which is having a vast amount of experience.
This statement captures the fundamental tension at the heart of WFO: it was designed to scale expert opinion, not to generate evidence-based insights. The system functioned less as a self-learning AI and more as a structured knowledge base requiring continuous human intervention — a distinction that proved catastrophic when deployed across diverse global populations.
Concordance Evidence: Why Rates Varied from 12% to 96%
The most systematic evidence on WFO's clinical performance comes from concordance studies — research that measured how often WFO's recommendations aligned with decisions made by multidisciplinary tumor boards (MDTs) or treating physicians. A 2021 meta-analysis published in Scientific Reports (Nature) pooled data from 9 studies involving 2,463 patients and found that overall concordance was 52.74% at the "Recommended" (green) level and 81.52% when including both "Recommended" and "For Consideration" (yellow) levels. In other words, WFO's strongest recommendations agreed with physicians only about half the time.
But the aggregate figure masks dramatic variation by cancer type, country, and patient population. A 2018 study in The Oncologist examined 362 patients in China and found concordance ranging from 96% for ovarian cancer to just 12% for gastric cancer.

| Country / Region | Cancer Type | Concordance Rate | Key Driver of Variation |
|---|---|---|---|
| India | Breast cancer | 93% (reported) | Treatment protocols more closely aligned with U.S. guidelines |
| China | Ovarian cancer | 96% | Standard treatments matched NCCN guidelines |
| China | Lung cancer | 81.3% | EGFR mutation rate >50% vs ~15% in U.S. |
| China | Breast cancer | 64.2% | Locally available drugs not in WFO's knowledge base |
| China | Gastric cancer | 12% | 88% were physician's choice; S-1 drug not in WFO training |
| Denmark | Multiple types | ~33% (reported) | Different national treatment guidelines |
| South Korea | Multiple types | 49–73% | Insurance coverage differences (e.g., regorafenib not covered) |
The 12% concordance for gastric cancer in China is particularly instructive. The study authors found that 88% of cases were classified as "physician's choice" — meaning WFO could not make a recommendation at all. The primary reason: WFO's knowledge base did not include S-1 (TIJI'AO), a locally available and commonly used chemotherapy drug in China. The system was trained on U.S. treatment protocols and could not account for the pharmaceutical formularies, treatment sequencing conventions, or economic realities of non-U.S. healthcare systems.
The EGFR mutation rate disparity further illustrates the problem. In the U.S., the EGFR mutation rate in lung cancer is approximately 15%; in China, it exceeds 50%. WFO's training data, drawn from MSK's predominantly affluent, New York-based patient population, did not reflect this epidemiological reality. The system could not adjust its recommendations for a fundamentally different patient population.
The STAT Revelations: Unsafe Recommendations and Internal Warnings
The most damning evidence against WFO came not from academic studies but from IBM's own internal documents. In 2018, STAT News obtained internal IBM slide decks from June and July 2017 that had been presented by Watson Health's deputy chief health officer. The documents documented "multiple examples of unsafe and incorrect treatment recommendations" and blamed the problems on training by IBM engineers and MSK doctors using a small number of synthetic cancer cases rather than real patient data.
The internal presentation concluded that recommendations were based on the expertise of a few specialists per cancer type instead of "guidelines or evidence," and that the "often inaccurate" recommendations raised
"serious questions about the process for building content and the underlying technology."
These internal warnings were not isolated. A Florida doctor, according to the same STAT reporting, called the product a "piece of shit" in an internal IBM presentation. The MD Anderson project, which had invested approximately $62 million over three years, was shelved without producing a usable system.
Perhaps most critically, no independent third-party study or clinical trial examining WFO's effectiveness on patient outcomes was ever published. The system was deployed in hospitals across the globe — in India, China, South Korea, Denmark, and the United States — without a single prospective randomized trial demonstrating that it improved, or even maintained, the quality of cancer care.
Structural Problems: A Knowledge Base in a Box
Beyond the concordance data and internal warnings, WFO suffered from a set of structural problems that made it fundamentally unsuited for real-world clinical deployment. These were not bugs that could be patched — they were architectural choices baked into the system's design.
- Dependence on NCCN/U.S. guidelines: WFO's knowledge base was built around National Comprehensive Cancer Network (NCCN) guidelines and MSK's treatment protocols. These reflect U.S. practice patterns, drug availability, and regulatory approvals — not the realities of healthcare systems in China, India, or Denmark.
- Inability to handle locally available drugs: The gastric cancer example in China (S-1) is emblematic. WFO could not recognize or recommend drugs that were standard of care in other countries but not approved or commonly used in the U.S. This made the system effectively blind to large portions of global oncology practice.
- No insurance or financial context: In South Korea, WFO recommended regorafenib for certain colorectal cancer patients, but the drug was not covered by insurance. In China, it recommended osimertinib for EGFR-resistant lung cancer patients who could not afford it. The system had no mechanism to incorporate cost, insurance coverage, or patient financial circumstances into its recommendations.
- No EHR integration: At Jupiter Medical Center in Florida, a nurse spent approximately 90 minutes per week manually entering patient data into WFO. The system could not integrate with different EHR platforms, creating a significant workflow burden that undermined adoption.
- Prohibitive cost: WFO cost $200 to $1,000 per patient, plus consulting fees. For a community hospital or a clinic in a low-resource setting — exactly the audience WFO was supposed to serve — this pricing was unsustainable.
- Static knowledge base: When metastatic lung cancer treatment guidelines changed in a single week in 2017, WFO could not update its recommendations quickly. The system required human curators to manually input new knowledge — a process that took months, not days.
These structural problems were compounded by a fundamental governance failure: WFO was deployed globally before its core assumptions were validated. The system was rolled out to hospitals in multiple countries without prospective testing, without population-specific training, and without a mechanism to learn from its mistakes.
The Verdict: What Watson for Oncology Teaches Us About AI in Healthcare
Watson for Oncology failed not because AI cannot support cancer care, but because its architecture was fundamentally mismatched to the complexity of real-world oncology decision-making. The system was a "knowledge base in a box" — a static repository of expert opinion from a single institution, trained on synthetic cases, deployed globally without validation, and unable to adapt to local contexts, drug formularies, or patient populations.
The lessons for current AI clinical decision support (CDS) development are clear:
- Prospective validation is non-negotiable: No AI CDS system should be deployed in clinical settings without prospective randomized trials demonstrating its impact on patient outcomes. WFO had none.
- Population-specific training is essential: A system trained on patients from the Upper East Side of Manhattan cannot be expected to perform in rural China or India. Demographic, epidemiological, and genetic differences matter.
- Outcome-based learning loops are critical: A static knowledge base that cannot learn from its recommendations is not AI — it is a decision tree. Modern AI CDS systems must incorporate feedback mechanisms that allow continuous improvement.
- Local context must be built in, not bolted on: Drug formularies, insurance coverage, treatment guidelines, and patient financial circumstances vary dramatically across regions. A global AI CDS system must be designed to accommodate this variability from the ground up.
- Governance frameworks must precede deployment: WFO scaled before validating its core assumptions. Modern AI deployments need governance structures that enforce validation, monitoring, and accountability at every stage.
The WFO story is not an argument against AI in oncology. It is an argument for doing AI in oncology correctly — with rigorous evidence, population-specific design, and a clear-eyed understanding of what AI can and cannot do. For readers interested in how current AI CDS systems are learning from these lessons, see our analysis of AI Clinical Decision Support in Primary Care and our state-of-the-industry evidence assessment for 2026.
Comments
Join the discussion with an anonymous comment.