
Market Snapshot: The $32–54 Billion Question
The global market for AI in healthcare is expanding rapidly, but the exact size depends heavily on what one counts. Analyst estimates for 2026 range from approximately $32 billion to $54 billion, with compound annual growth rates (CAGR) between 30% and 38%. The wide spread reflects fundamental disagreements about definitional boundaries: some firms include AI-powered drug discovery platforms and genomics analytics, while others restrict their scope to clinical software and diagnostic tools. A separate forecast cited by Uvik projects the market could reach roughly $120 billion by 2028, though that figure aggregates across all healthcare AI segments including administrative automation, patient engagement, and revenue cycle management.
What is not in dispute is the direction of travel. Investment in healthcare AI has accelerated through 2025 and into 2026, driven by three converging forces: the maturation of large language models and multimodal architectures, a growing body of real-world deployment evidence in clinical workflows, and regulatory frameworks that are beginning to provide clearer pathways for approval and reimbursement. The competitive landscape now includes big technology firms, specialized startups, and EHR vendors all vying for position, each bringing different strengths in data access, regulatory experience, and clinical relationships.
Adoption Breadth vs. Depth: The 80/20 Reality
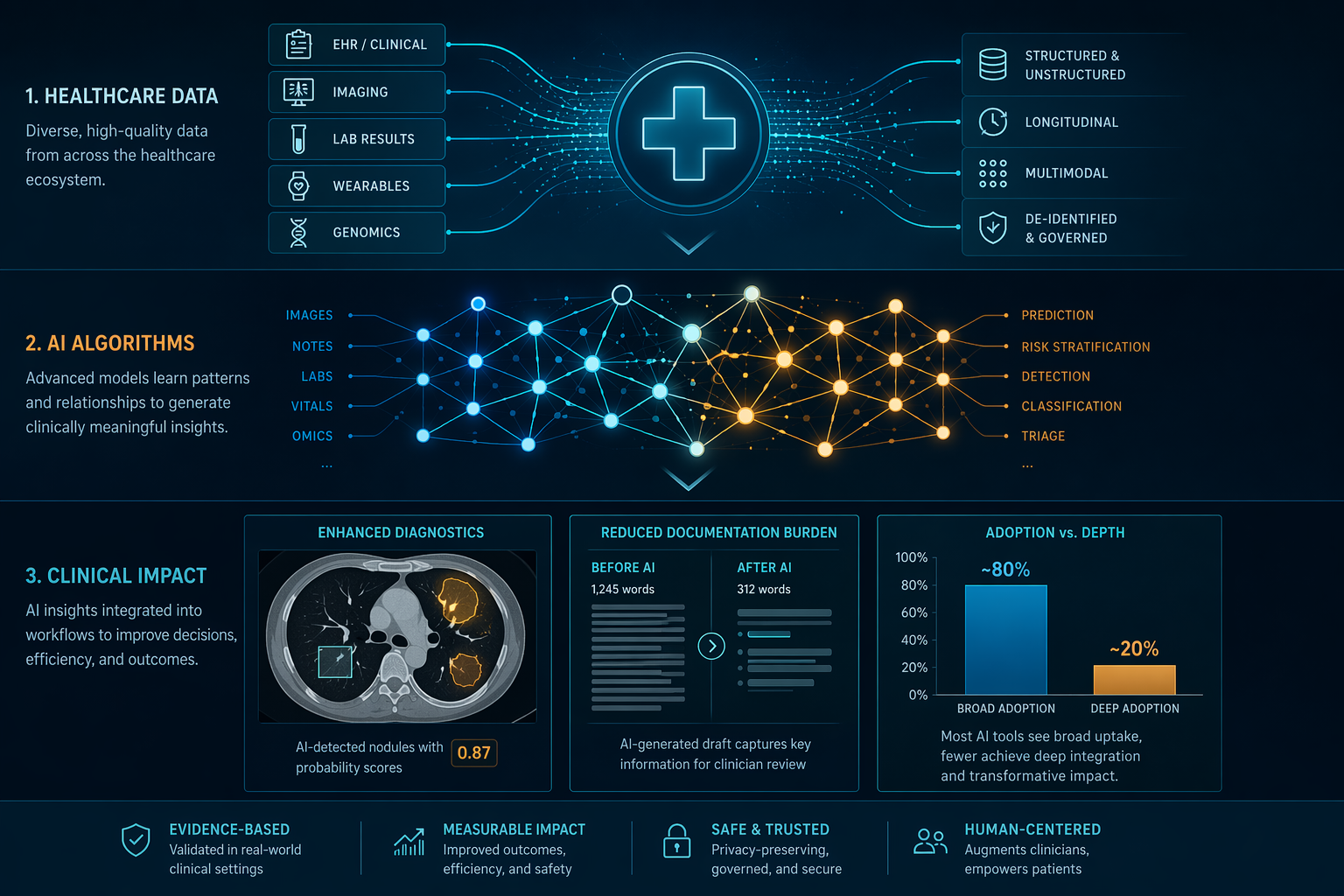
The headline adoption numbers are striking. According to data compiled by Uvik, approximately 80% of U.S. hospitals now use AI in at least one clinical or operational function, and roughly 89% of healthcare executives report that their organizations are using AI in some capacity. About two in three U.S. physicians had used a health AI tool by 2024, a figure that has almost certainly risen since. On the surface, these numbers suggest that AI has become a standard component of healthcare delivery.
But breadth is not depth. The same data show that fewer than 20% of institutions report sustained, high-success use of AI in core clinical diagnosis. The gap between "using AI somewhere" and "relying on AI for diagnostic decisions" is the single most important metric for understanding the current state of the industry. Most AI deployments remain in operational and administrative functions — scheduling, billing, prior authorization, and basic documentation — where the stakes are lower and the workflows are more standardized.
| Adoption Metric | Value | Source Context |
|---|---|---|
| U.S. hospitals using AI in at least one function | ~80% | Uvik, May 2026 |
| Healthcare executives reporting AI usage | ~89% | Uvik, May 2026 |
| U.S. physicians who used health AI in 2024 | ~2 in 3 | Uvik, May 2026 |
| Institutions with sustained high-success AI in core diagnosis | <20% | Uvik, May 2026 |
This pattern is not necessarily a failure. Operational AI delivers measurable returns — reduced documentation burden, faster billing cycles, fewer administrative errors — and builds the infrastructure and trust needed for deeper clinical integration. But it does mean that the most transformative promises of AI in healthcare — earlier diagnosis, personalized treatment recommendations, reduced diagnostic error — remain concentrated in a relatively small number of leading institutions, most of which have dedicated AI teams, robust data infrastructure, and strong executive sponsorship.
The FDA Regulatory Landscape: 1,451 Devices and Counting
The U.S. Food and Drug Administration has now authorized 1,451 AI- and machine learning-enabled medical devices cumulatively through the end of 2025, according to analysis by IntuitionLabs cross-referenced against the official FDA list. Of those, 295 were cleared in 2025 alone, representing the highest single-year total to date. The pace of clearances continues to accelerate, but the distribution across clinical specialties remains strikingly uneven.

Radiology accounts for 76% of all authorized devices — 1,104 out of 1,451. Cardiovascular applications follow at roughly 9% (approximately 130 devices), and neurology at about 5% (approximately 68 devices). Every other specialty, including pathology, ophthalmology, gastroenterology, and dermatology, accounts for a fraction of the total. This concentration reflects both the maturity of medical imaging as a data type and the relative clarity of the regulatory pathway for imaging algorithms.
| Specialty | Cumulative Devices (End-2025) | Share of Total |
|---|---|---|
| Radiology | 1,104 | 76% |
| Cardiovascular | ~130 | ~9% |
| Neurology | ~68 | ~5% |
| Other (pathology, ophthalmology, etc.) | ~149 | ~10% |
Two regulatory milestones in 2025–2026 signal a shift toward more complex AI architectures. In February 2025, the FDA cleared Aidoc's CARE1, the first device powered by a foundation model, marking a departure from the single-task narrow AI models that have dominated clearances to date. Separately, RecovryAI received a Breakthrough Device Designation for a generative AI tool, indicating FDA interest in establishing pathways for large language models and multimodal systems. The agency has stated it will explore methods to identify and tag devices incorporating foundation models in future updates to its AI-Enabled Medical Device List.
For a detailed breakdown of current FDA guidance documents and their implications, see the FDA AI/ML SaMD Guidance Status as of June 2026.
Clinical Diagnostic Accuracy: Narrow Models vs. Generative AI
One of the most consequential distinctions in the current AI landscape is the performance gap between narrow, task-specific models and general-purpose generative AI systems. The two categories are often discussed under the same umbrella, but their clinical accuracy profiles are dramatically different.
Narrow AI models trained on bounded, well-defined tasks have achieved impressive results in controlled settings. AI systems for diabetic retinopathy detection report approximately 96% accuracy. Breast cancer screening algorithms achieve 90–92% sensitivity for early-stage disease. These models operate within tightly constrained input domains — retinal fundus photographs, mammograms, pathology slides — where the data format is standardized, the classification task is clear, and the training datasets are large and relatively well-annotated.

Generative AI models — large language models and multimodal systems designed for open-ended clinical reasoning — tell a different story. Meta-analyses cited by Uvik place the average diagnostic accuracy of generative AI models at approximately 50%, a figure comparable to non-expert clinicians but well below the performance of specialists or narrow AI systems. These models excel at tasks like summarizing patient histories, generating draft documentation, and answering factual questions. They struggle with differential diagnosis, rare disease identification, and situations requiring precise probabilistic reasoning.
| AI Category | Example Task | Reported Accuracy | Key Limitation |
|---|---|---|---|
| Narrow (diabetic retinopathy) | Classify retinal images | ~96% | Only works for one disease, one image type |
| Narrow (breast cancer screening) | Detect malignancy in mammograms | 90–92% sensitivity | Requires high-quality images, specific equipment |
| Generative AI (open-ended diagnosis) | Differential diagnosis from clinical text | ~50% | Inconsistent, prone to hallucination, no calibration |
For procurement teams and clinical leaders, this gap has practical implications. Deploying a narrow AI model for a specific imaging task is a well-understood process with predictable performance characteristics. Deploying a generative AI system for clinical decision support requires ongoing monitoring, guardrails against hallucination, and a clear understanding that the system's accuracy may vary unpredictably across different patient populations and clinical scenarios. The clinical applications overview provides a deeper examination of how these models perform in specific use cases.
Workflow and Documentation ROI: Where the Returns Are Real
If diagnostic AI remains a story of promise constrained by evidence, workflow AI — particularly ambient documentation and clinical summarization — is a story of measurable, repeatable returns. The data compiled by Uvik paint a clear picture: AI-powered ambient scribes and clinical documentation tools reduce physician documentation time by 40–45%, cut error rates by 25–30%, and reduce the time clinicians spend retrieving patient histories by more than 50%.
These are not small improvements. For a physician spending two hours per day on documentation, a 40% reduction recovers nearly an hour of clinical time daily — time that can be redirected to patient care, supervision of trainees, or simply reducing burnout. The financial returns are equally compelling. Organizations deploying workflow AI report an average return on investment of 3.2:1, with typical payback periods of 12 to 18 months.
| Workflow AI Metric | Improvement | Source |
|---|---|---|
| Physician documentation time reduction | 40–45% | Uvik, May 2026 |
| Error rate reduction | 25–30% | Uvik, May 2026 |
| Time spent retrieving patient histories | >50% reduction | Uvik, May 2026 |
| Average ROI | 3.2:1 | Uvik, May 2026 |
| Typical payback period | 12–18 months | Uvik, May 2026 |
The reasons for this success are not mysterious. Documentation and summarization are tasks that map naturally to the current capabilities of large language models: they involve processing structured and unstructured text, extracting key information, and generating coherent output. The stakes are lower than in diagnostic AI — an imperfect summary can be corrected by a clinician, while an incorrect diagnosis can cause direct harm. And the workflows are relatively standardized across institutions, making it easier to deploy and scale solutions.
The clinical deployment reports category on this site provides detailed accounts of how specific health systems have implemented these tools, including documented failure modes and staff adoption patterns.
The Evidence Quality Gap: Adoption Outpacing Validation
The most significant concern facing the healthcare AI industry is not a technology problem — it is an evidence problem. AI is being adopted faster than its real clinical value can be understood, and the evidence base supporting many authorized devices is alarmingly thin.
Consider the numbers. According to a 2025 JAMA study of 691 FDA-cleared AI/ML devices cited by IntuitionLabs, fewer than 2% were supported by randomized clinical trial evidence. Nearly half (46.7%) of FDA submission summaries omitted the study design entirely, and 53.3% omitted the sample size. Most critically, fewer than 1% of device summaries reported any data on patient health outcomes. The vast majority of clearances are based on analytic performance metrics — area under the curve (AUC), sensitivity, specificity — that measure how well a model performs on a test dataset, not whether its use improves patient health.
"Medical AI risks being adopted faster than its real value can be understood." — Nature Medicine editorial, April 21, 2026
The Nature Medicine editorial, published in April 2026, explicitly calls for proportional evidence standards: claims of analytic performance require robust validation in the intended setting; claims of clinical actionability require evidence that outputs are interpretable by clinicians; claims of workflow benefit require implementation studies; and claims of improved outcomes require stronger prospective evidence, ideally from randomized trials. This framework is sensible, but it is not yet reflected in the regulatory or procurement processes of most organizations.
For a more detailed analysis of what the clinical evidence actually shows — and where it falls short — see Artificial Intelligence and Health: What the Clinical Evidence Actually Shows.
Known Limitations and Governance Gaps
Multiple systematic reviews and expert analyses have mapped the key risks of AI in healthcare with reasonable consensus. The top five, consistently identified across sources including Uvik, the Journal of Young Investigators, and the broader peer-reviewed literature, are:
- Algorithmic bias: Skewed training datasets, algorithmic flaws, and systemic healthcare inequities can produce models that perform poorly for underrepresented populations. The STANDING Together consensus recommendations call for transparency regarding health dataset limitations, but adoption of these standards remains voluntary.
- Weak generalizability: Models trained on data from one institution, region, or patient demographic often degrade significantly when deployed in a different setting. External validation remains the exception rather than the rule.
- Model drift: Clinical AI models can degrade over time as patient populations, clinical practices, and data distributions shift. Continuous monitoring and retraining are required, but few organizations have the infrastructure to support this at scale.
- Unclear liability: When an AI system makes an error that leads to patient harm, responsibility may fall on the clinician, the health system, the vendor, or some combination. Legal frameworks have not kept pace with the complexity of AI-assisted clinical decision-making.
- EHR integration friction: Many AI tools require custom integration with electronic health record systems, and the ONC information blocking rule has created new complexities around data access and interoperability that affect how AI systems can retrieve and use patient data.
These risks are well-mapped but not yet well-managed. Few health systems have dedicated AI governance committees with the authority to monitor deployed models, audit for bias, and intervene when performance degrades. The algorithmic bias glossary entry on this site provides a deeper look at audit frameworks and mitigation methods.
Emerging Trends: Agentic AI, Foundation Models, and the EU AI Act
Several developments make 2026 a genuinely transitional year for AI in healthcare. These are not speculative future trends — they are happening now, and they will shape the landscape for the next several years.
Agentic AI — systems that can take proactive, goal-directed actions rather than simply responding to queries — has entered clinical environments. According to Philips, Mount Sinai Health System, Mayo Clinic, and the UK's National Health Service have all launched projects implementing agentic AI. These systems are designed to monitor patient data, identify deteriorating conditions, suggest interventions, and coordinate care tasks across multiple clinical systems. The shift from passive tools to active agents represents a fundamental change in how AI interacts with clinical workflows.
Foundation models — large, pre-trained AI models that can be adapted to multiple tasks — are beginning to enter the regulated medical device space. The Aidoc CARE1 clearance in February 2025 was the first FDA authorization of a foundation-model-powered device, and it will not be the last. These models promise greater flexibility and the ability to handle multiple clinical tasks from a single architecture, but they also introduce new challenges around interpretability, validation, and monitoring. The foundation models glossary entry provides a detailed examination of their clinical applications and limitations.
The Mayo Clinic Platform, described in a February 2026 paper in npj Health Systems, exemplifies the data infrastructure required to support these advanced AI systems. The platform provides access to de-identified data from over 15.1 million patients, including 12 billion radiology images, 3.2 billion lab results, and 1.65 billion clinical notes. It supports both no-code tools for rapid cohort exploration and advanced environments (JupyterLab, RStudio) for custom model development, with computational resources including up to 208 CPU cores and 8 NVIDIA H100 GPUs. Platforms like this are essential for developing and validating the next generation of clinical AI models.
On the regulatory front, the EU AI Act will impose high-risk obligations on AI systems used in healthcare beginning in August 2026, with full medical device compliance required by August 2027. This creates a significant compliance burden for any company selling AI products into the European market, and it may accelerate the development of more rigorous evidence standards globally. The FDA AI/ML SaMD guidance status article provides the latest information on how U.S. and European regulatory frameworks are evolving.
Taken together, these trends point to a healthcare AI industry that is maturing rapidly but unevenly. The infrastructure for deployment — regulatory pathways, data platforms, clinical workflows — is being built. The evidence base, while still thin in many areas, is growing. And the gap between what AI can do in controlled settings and what it actually does in real clinical environments is beginning to close, albeit slowly and with significant variation across specialties and use cases.
For organizations making procurement and deployment decisions in this environment, the key is to match ambition with evidence. Workflow AI is ready for broad deployment today. Narrow diagnostic AI is ready for specific, well-defined use cases with strong local validation. Generative AI and agentic systems require careful piloting, ongoing monitoring, and a clear-eyed understanding of their current limitations. The organizations that succeed will be those that treat AI adoption not as a technology project but as a continuous process of evidence generation, governance, and clinical integration.
Comments
Join the discussion with an anonymous comment.