There are 1,016 FDA authorizations for AI/ML-enabled medical devices, representing 736 unique tools. Not one is a large language model. That gap between regulatory reality and public narrative is why I read healthcare AI studies for a living.
Where the Numbers Hold Up
Three areas have produced numbers that change my assessment from ‘interesting’ to ‘deploy with monitoring’.
In medical imaging, GANs used for brain MRI segmentation achieved an average Dice coefficient of 0.89, beating traditional methods (Despotović et al., 2015). That is a single study on the IBSR dataset. It is not a general claim about all segmentation, but it is a replicable result in a narrow context. For a deeper critical appraisal of imaging evidence, see our separate analysis.
In clinical documentation, GPT-4 draft replies to patient inbox messages improved mental task load and reduced burnout scores for physicians. That is the headline. The full finding is more interesting: overall response time did not improve (Garcia et al., 2024). Many will read ‘saves time’. It does not. It saves mental effort. That distinction matters when you are budgeting IT spend. For nursing documentation, AI-powered voice-to-text tools cut documentation time by 21–30%, which works out to 95–134 hours per year per nurse. That is a concrete, measurable reduction in a task that consumes about a quarter of a nurse’s shift.
In drug discovery, the first drug entirely designed by generative AI (Insilico Medicine’s GENTRL model) entered Phase I clinical trials in 2023. That is a genuine milestone. AI-designed molecules have been in preclinical stages for years; this one crossed the threshold into human testing. It does not mean the drug will work, but the pathway from model to trial is now demonstrated.
A Deloitte report estimates that generative AI in revenue cycle management can save 41–50% of professional time across all stages. The same report says 75% of large healthcare organizations are using or planning to scale generative AI in operations. I am obliged to add that these are consulting-industry figures based on client self-reports, not controlled studies. The 41–50% range is plausible as a directional estimate, but I would not treat it as a precision target. And the 75% is a survey of intentions, not actual deployment.

Where the Evidence Falls Apart
LLMs perform well on examinations. Google’s MedPaLM-2 scored at expert level on the USMLE. That is real, but it is not clinical competence. When tested on actual clinical decision-support questions, ChatGPT achieved 71.8% accuracy (Rao et al., 2023), and Med-PaLM underperformed clinicians by 10.8% (Yu et al., 2023). A 71.8% accuracy rate on a multiple-choice evaluation is not a safe operating threshold for healthcare decisions. The 10.8% gap behind clinicians is not a small margin — in a field where single-digit error rates can mean missed diagnoses, double-digit deficits are disqualifying for autonomous use.
Patient and clinician attitudes reflect this skepticism. One survey found 35% of patients would decline generative AI use in their care due to transparency concerns (Moy et al., 2024). Among clinicians, 19% were unwilling to integrate AI because of unresolved liability for AI-generated errors (Choudhury & Asan, 2022). These are not fringe positions; they represent a significant portion of the people who would have to trust and use these systems. Chatbot responses were preferred 78.6% of the time by licensed professionals over physician responses in one study. Preference is not accuracy. A more empathic tone does not make the clinical content correct.
Even where deployment is justified by evidence, equity must be monitored. In a survey of AI specialists, 68% cited the absence of representative, FAIR-compliant training data as a primary source of algorithmic bias (Vorisek et al., 2023). 49% pointed to the absence of guidelines. These are not theoretical concerns — they are structural gaps in how models are built and how their outputs are evaluated. Synthetic data generation might help address data scarcity, but synthetic data carries its own biases — if the training distribution is skewed, the synthesis amplifies rather than corrects the gap.
The Regulatory Reality: 1,016 Devices, Zero LLMs
The Nature taxonomy of 1,016 FDA authorizations (as of December 2024) tells a clear story: 84.4% of devices use images as core input, 85.6% are classified as ‘analysis’ (quantification, feature localization), and only 11.3% as ‘generation’. That 11.3% — representing over 100 devices — is almost entirely image enhancement: reconstruction, denoising, super-resolution. They are not LLMs generating patient summaries or clinical text. The taxonomy explicitly states: no large language models were found in the device list. That is not an oversight. It is a regulatory reality. Foundation-model-based devices like Aidoc’s CARE1 (cleared in February 2025) are beginning to appear, but as of the most recent comprehensive audit, zero LLM-powered medical devices have received marketing authorization from the FDA.
| Category | Count / Share |
|---|---|
| Total FDA authorizations (AI/ML) | 1,016 |
| Unique devices | 736 |
| Devices using images as input | 84.4% |
| Devices classified as Generation | 11.3% |
| Devices using LLMs | 0 |
| Foundation-model devices (post-audit) | Aidoc CARE1 (Feb 2025) |
This regulatory gap has consequences: clinicians evaluating an LLM-based diagnostic tool cannot rely on FDA clearance as a signal. The absence means any claim of clinical use must be backed by peer-reviewed evidence of safety and efficacy, and even then, liability and reimbursement questions remain unresolved.
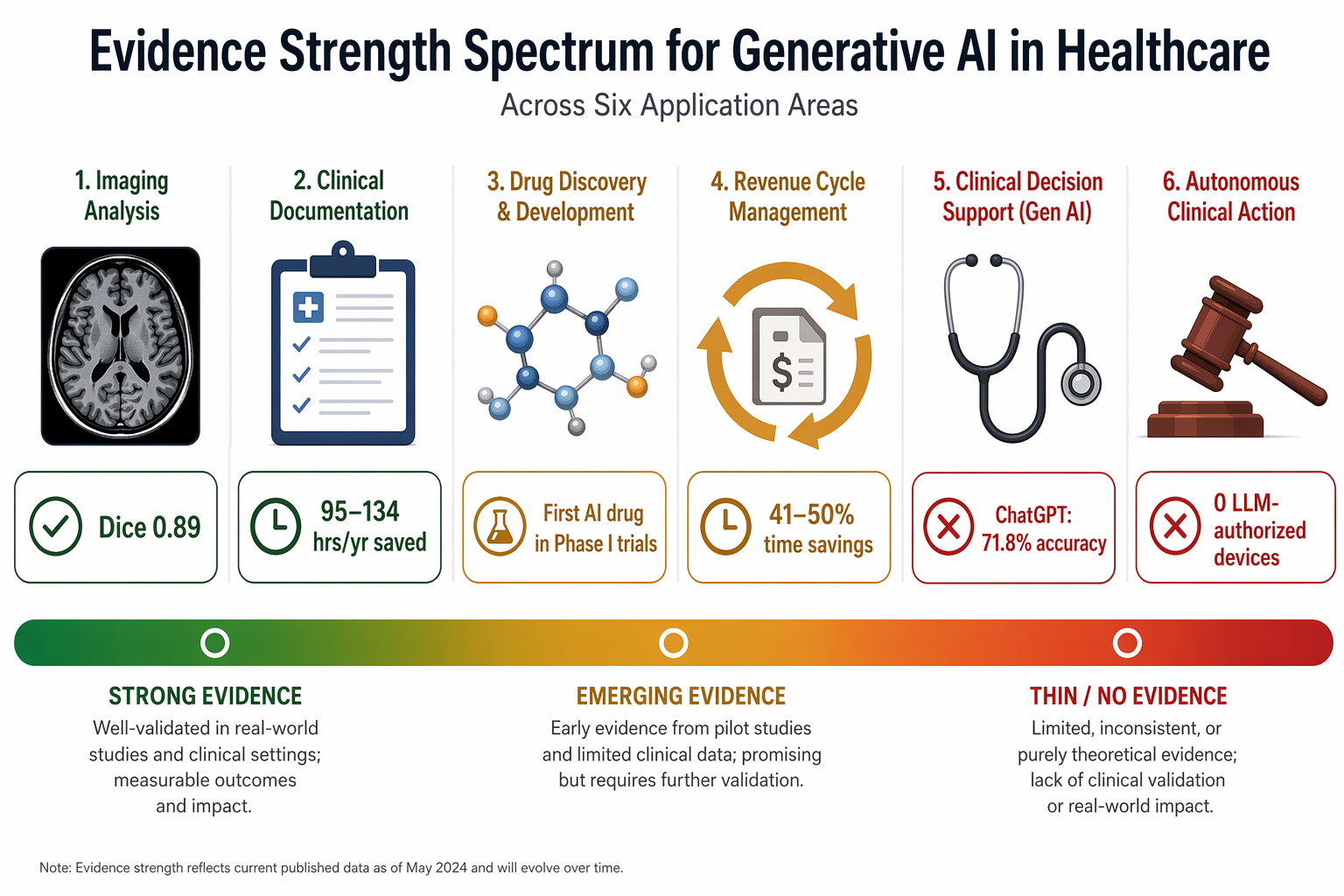
The evidence supports targeted deployment in imaging, documentation, and drug discovery. Revenue cycle management is plausible but needs a pilot before scaling. Autonomous diagnosis and LLM-based treatment planning are not supported by current evidence. Equity-sensitive applications remain unaddressed in deployment studies. The regulatory reality is a useful boundary: no LLM-powered medical device has yet passed FDA review. That should give pause to any claim that generative AI is ‘transforming healthcare’ at the point of care. Transformation is happening in documentation, in imaging analysis, and in the lab. In autonomous decision-making, the evidence is not there.
Deploy where the numbers are solid. Mandate monitoring for bias and drift. And do not overclaim. That is the evidence-grounded position.
Comments
Join the discussion with an anonymous comment.