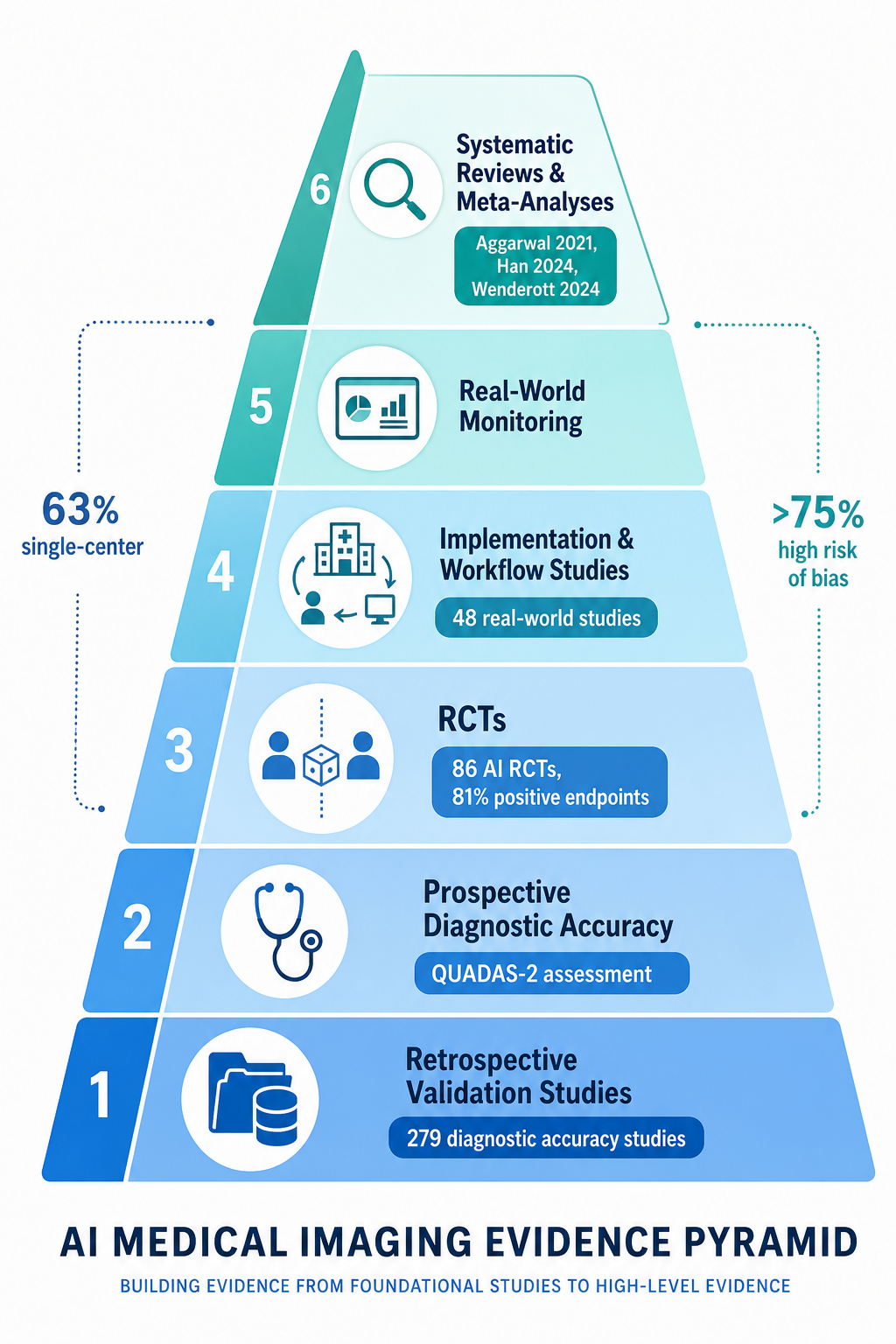
Introduction: The Evidence Pyramid for AI Medical Imaging
The field of AI medical image analysis has matured rapidly over the past decade, transitioning from proof-of-concept demonstrations on curated datasets to prospective clinical trials and, in many cases, regulatory clearance for commercial deployment. As of Q4 2025, the FDA had authorized 1,451 AI-enabled medical devices since 1995, with 1,104 (76%) dedicated to radiology applications. Yet the sheer volume of clearances and the proliferation of published studies can create a misleading impression of clinical readiness. The central question for clinicians, researchers, and regulators is no longer whether AI can interpret medical images — it is whether the existing evidence base is methodologically robust enough to support confident clinical adoption.
This article adopts a meta-research critical appraisal lens to systematically examine the quality of evidence underpinning AI medical image analysis. Rather than cataloging AI capabilities or summarizing performance metrics in isolation, we evaluate the study designs, risk-of-bias profiles, reporting standards adherence, and real-world validation gaps that determine how much trust the evidence actually warrants. The analysis draws on three major systematic reviews: a scoping review of 86 randomized controlled trials (RCTs) evaluating AI in clinical practice, a meta-analysis of 279 diagnostic accuracy studies of deep learning in medical imaging, and a systematic review of 48 real-world AI implementation studies in medical imaging workflows.
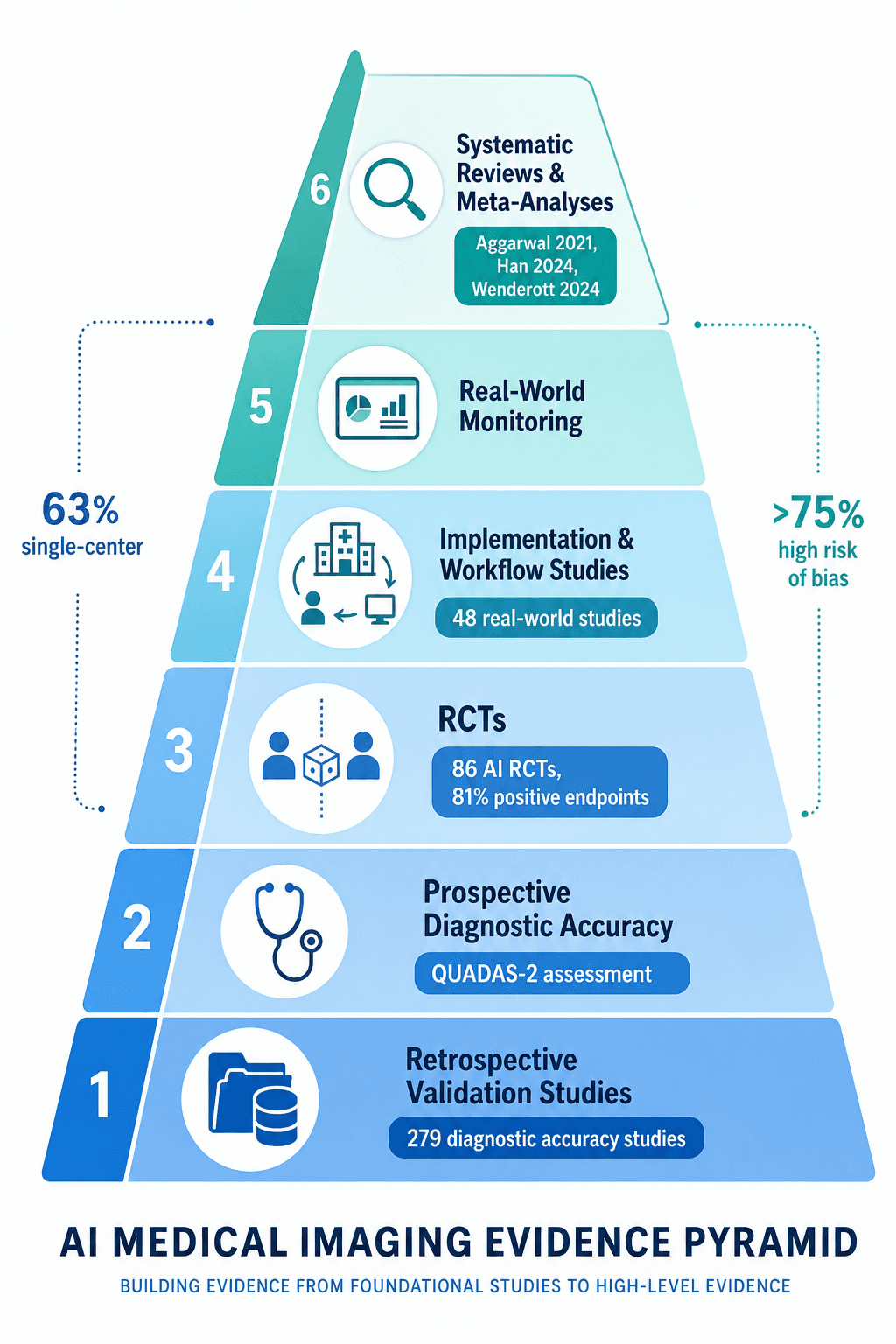
The RCT Landscape: 86 Trials, 81% Positive — But Methodological Concerns Remain
A 2024 scoping review by Han et al. published in The Lancet Digital Health identified 86 RCTs evaluating AI in clinical practice, published between 2018 and November 2023. At first glance, the results appear overwhelmingly positive: 70 of 86 trials (81%) reported positive primary endpoints. Of these, 59 (69%) evaluated deep learning systems specifically for medical imaging, with 42 of those 59 (71%) being video-based systems — predominantly in endoscopy — and the remaining 17 (29%) using static images.
However, a closer examination of study design reveals significant constraints that limit the generalizability of these findings. The table below summarizes the key methodological characteristics of the 86 RCTs.
| Characteristic | Finding | Implication |
|---|---|---|
| Single-center design | 63% (54/86) of trials | Limits generalizability; results may not replicate across different patient populations, equipment, or clinical workflows |
| Single-country conduct | 92% (79/86) of trials | Geographic concentration in US (31%) and China (30%) raises questions about applicability to other healthcare systems |
| CONSORT-AI citation | Only 19% (12/63) of trials published since 2021 | Majority did not follow AI-specific reporting standards, reducing transparency and reproducibility |
| Industry-developed models | 55% (47/86) of AI models | Potential for publication bias and selective outcome reporting; academic models (41%) may have different validation pathways |
| Race/ethnicity reporting | Only 22 trials (26%) | Inability to assess algorithmic fairness and differential performance across demographic groups |
| Gastroenterology dominance | 43% (37/86) of trials | 65% of these conducted by only four research groups, raising concerns about independent replication |
| Operational time measurement | 60% (52/86) of trials | Of these, 35% reported significant decreases, 25% significant increases, and 40% no significant change — highly variable results |
The finding that only 19% of trials published after the 2020 release of the CONSORT-AI extension cited the guideline is particularly concerning. CONSORT-AI was specifically developed to address the unique reporting challenges of AI interventions — including the need to describe the AI's intended use, the training data, the human-AI interaction model, and the handling of errors. Without adherence to these standards, readers cannot fully assess the validity or reproducibility of trial results.
Diagnostic Accuracy Under the Microscope: 279 Studies and the QUADAS-2 Reality
Beyond RCTs, the largest body of evidence for AI medical image analysis comes from diagnostic accuracy studies. A 2021 meta-analysis by Aggarwal et al. published in npj Digital Medicine pooled 279 such studies across three clinical specialties: ophthalmology, respiratory imaging, and breast imaging. The reported area under the receiver operating characteristic curve (AUC) values were impressive across all three domains, as shown in the table below.
| Specialty | Modality | AUC Range | Key Conditions |
|---|---|---|---|
| Ophthalmology | Retinal fundus photographs | 0.933 – 1.00 | Glaucoma, diabetic retinopathy, diabetic macular edema (OCT) |
| Respiratory | Chest X-ray | 0.864 – 0.979 | Lung cancer, tuberculosis |
| Breast imaging | MRI | 0.868 – 0.909 | Breast cancer detection and classification |
| Breast imaging | Ultrasound | 0.909 | Breast cancer detection |
These figures are frequently cited as evidence that AI can match or exceed human expert performance. However, the meta-analysis applied the QUADAS-2 (Quality Assessment of Diagnostic Accuracy Studies) tool to evaluate risk of bias, and the results paint a far more sobering picture.
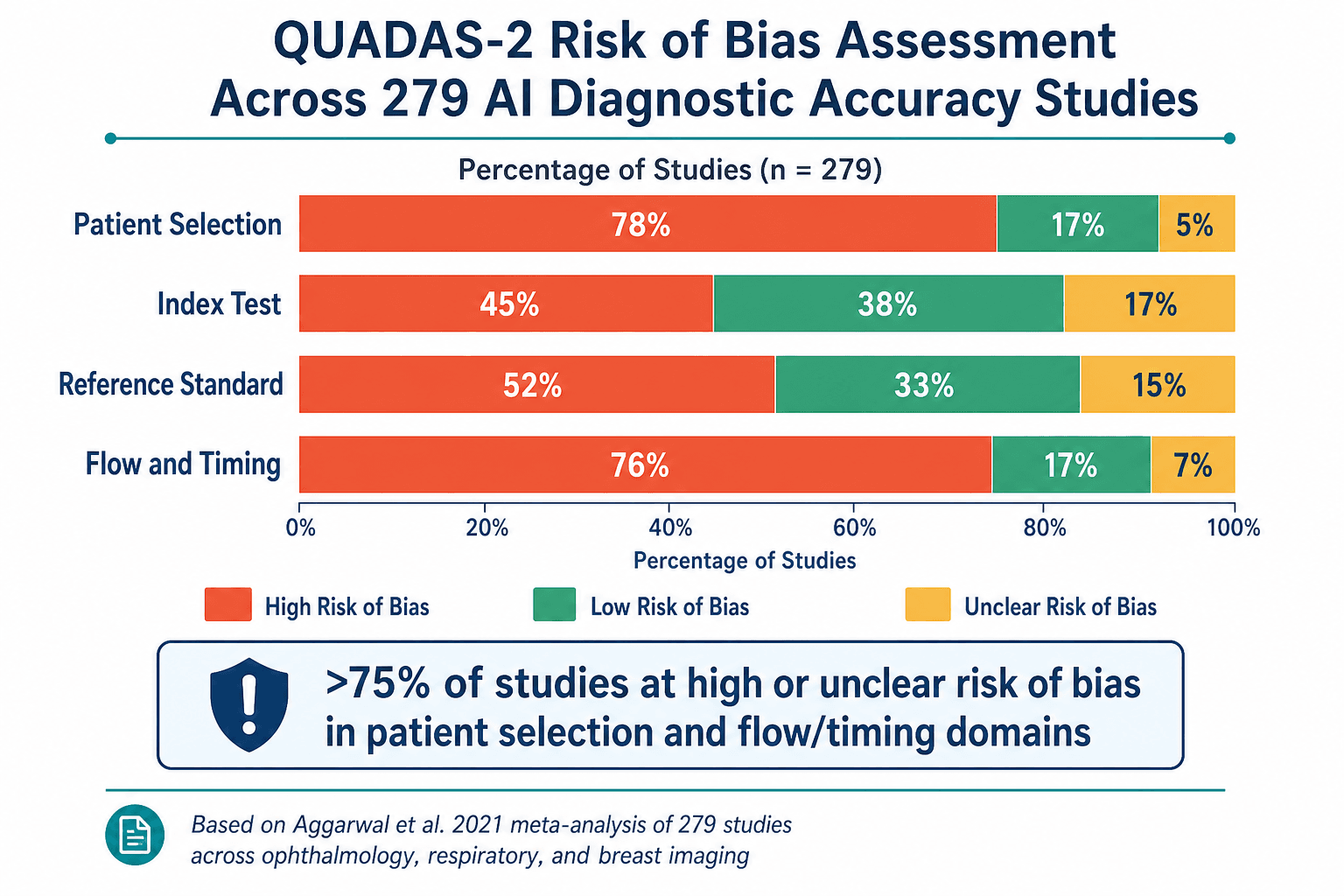
Across all three specialties, more than 75% of studies were rated as having high or unclear risk of bias in the patient selection and flow/timing domains. Specifically, 72% of ophthalmology studies, 77% of respiratory studies, and 76% of breast imaging studies had high or unclear risk in patient selection. None of the 279 studies provided a prespecified sample size calculation. Only 8 ophthalmology studies, 10 respiratory studies, and 6 breast imaging studies mentioned the STARD-2015 reporting guidelines or included a STARD flow diagram.
The heterogeneity across studies was also extremely high, with I² values often exceeding 75%. This means that the variability in reported performance across studies cannot be explained by chance alone — it reflects genuine differences in study populations, reference standards, AI algorithms, and outcome definitions. Pooling such heterogeneous studies into a single summary estimate may obscure important differences in performance across clinical contexts.
Real-World Efficiency: What 48 Implementation Studies Reveal About Workflow Impact
Diagnostic accuracy and RCT outcomes are necessary but not sufficient for clinical adoption. A third critical dimension is real-world workflow efficiency — does AI actually save time, reduce workload, or improve throughput in clinical practice? A 2024 systematic review by Wenderott et al. in npj Digital Medicine examined 48 original studies of AI implementation in real-world medical imaging workflows, with searches conducted up to May 2023.
The headline finding is a striking disconnect between subjective reports and objective meta-analytic evidence. Among the 33 studies that measured time for specific tasks, 67% (22/33) reported reductions. However, when the authors conducted meta-analyses for three specific workflow metrics — CT reading time (4 studies), colonoscopy time (5 studies), and triage turnaround time (3 studies) — none showed a statistically significant effect. The standardized mean differences and 95% confidence intervals were: CT reading time SMD -0.60 (95% CI -2.02 to 0.82), colonoscopy time SMD -0.04 (95% CI -0.76 to 0.67), and triage turnaround time SMD 0.03 (95% CI -0.50 to 0.56).
| Metric | Studies Reporting Reductions | Meta-Analysis Result | Key Limitation |
|---|---|---|---|
| CT reading time | 67% of 33 studies | SMD -0.60, 95% CI -2.02 to 0.82 (not significant) | Only 4 studies included in meta-analysis; high heterogeneity |
| Colonoscopy time | 67% of 33 studies | SMD -0.04, 95% CI -0.76 to 0.67 (not significant) | Only 5 studies included; wide confidence intervals |
| Triage turnaround time | 67% of 33 studies | SMD 0.03, 95% CI -0.50 to 0.56 (not significant) | Only 3 studies included; effect size near zero |
The methodological quality of the included studies was also concerning. Only 4 of 48 studies followed established reporting guidelines. None provided open-source algorithms, limiting reproducibility. More than 50% declared relevant or potential conflicts of interest. Only 3 studies (6%) calculated workload impacts beyond simple time measurements — for example, measuring the number of scans saved or the cognitive load on radiologists. Additionally, 62.5% (30/48) were single-institution studies, and 70.8% (34/48) used commercially available AI solutions. Among the 45 non-randomized studies, only 1 (2.2%) had an overall low risk of bias as assessed by the ROBINS-I tool.
These findings align with survey data from the Philips 2025 Future Health Index, which found that while 85% of radiologists believe AI will ensure greater consistency in patient examinations and improve patient outcomes, 41% feel that currently available tools do not adequately address their real-world needs. Furthermore, 63% of radiologists expressed concern about bias in AI algorithms, and 63% worried about legal liability when using AI. The gap between optimism and practical utility remains substantial.
Regulatory Evidence Standards: FDA Clearance Pathways and the PCCP Framework
Understanding the regulatory landscape is essential for contextualizing the evidence quality discussion. The FDA has authorized 1,451 AI/ML-enabled medical devices cumulatively through Q4 2025, with 1,104 (76%) in radiology. In 2025 alone, the agency cleared 295 AI/ML devices from 221 unique manufacturers. Of these, 62% (183) were classified as Software as a Medical Device (SaMD), 63% (187) were diagnostic, and 10.2% (30) were authorized with Predetermined Change Control Plans (PCCPs). The median clearance time was 142 days, with 24% cleared in under 90 days.
The vast majority of these clearances — 71.5% (211/295) in 2025 — were for radiology applications. The top product code was QIH (Radiological Computer-Aided Detection and Diagnosis) with 75 clearances. Leading companies by cumulative radiology AI clearances include GE HealthCare (120), Siemens Healthineers (89), Philips (50), Canon (45), United Imaging (38), Aidoc (31), and DeepHealth (28).
A critical distinction that readers must understand is the difference between regulatory clearance and demonstrated clinical efficacy. The FDA's 510(k) pathway, through which the majority of AI devices are cleared, requires demonstration of substantial equivalence to a predicate device — not independent clinical validation of safety and effectiveness in the intended use population. The PCCP framework, introduced to allow manufacturers to make pre-specified modifications to AI algorithms without requiring new submissions, represents an important step toward accommodating the iterative nature of machine learning, but it does not itself mandate higher-quality clinical evidence.
The regulatory framework is evolving, but there remains a significant gap between the evidence required for market access and the evidence needed to inform clinical adoption decisions. Clinicians and health systems evaluating AI tools must look beyond FDA clearance status to assess the quality and relevance of the underlying clinical evidence.
Critical Gaps: Publication Bias, Geographic Concentration, and Missing Demographics
Synthesizing the findings across the three major reviews reveals several cross-cutting limitations that undermine confidence in the AI medical imaging evidence base.
- Publication bias favoring positive results. The 81% positive endpoint rate in RCTs and the uniformly high AUC values in diagnostic accuracy studies are consistent with a literature that systematically underreports negative or null findings. This bias is amplified by the high proportion of industry-developed models (55% of RCTs), where there is a commercial incentive to publish favorable results.
- Geographic concentration. Of 86 RCTs, 92% were conducted in a single country, with the US (31%) and China (30%) accounting for 61% of all trials. This geographic concentration raises questions about the generalizability of findings to healthcare systems with different patient demographics, imaging equipment, clinical workflows, and disease prevalence patterns.
- Missing demographic data. Only 22 of 86 RCTs (26%) reported race or ethnicity data, and most of these were from the US. Without routine demographic reporting, it is impossible to assess whether AI algorithms perform equally across different population subgroups — a critical requirement for health equity.
- High heterogeneity. The I² values exceeding 75% in the diagnostic accuracy meta-analysis indicate that the variability in reported performance across studies is not due to chance. This heterogeneity reflects genuine differences in study design, patient populations, reference standards, and AI algorithms, making it difficult to derive stable summary estimates.
- Absence of patient-relevant outcomes. The vast majority of diagnostic accuracy studies report only technical performance metrics (AUC, sensitivity, specificity). Few studies measure patient-relevant outcomes such as changes in management, time to diagnosis, or clinical outcomes. The Wenderott review found that only 3 of 48 implementation studies measured workload impacts beyond simple time metrics.
- Lack of independent external validation. The predominance of single-center studies (63% of RCTs, 62.5% of implementation studies) means that most AI algorithms have not been tested in independent populations, on different equipment, or in different clinical settings — the very conditions under which model performance is most likely to degrade.
For readers interested in a broader analysis of methodological quality gaps across AI clinical research, our related meta-research analysis provides additional context on reporting standards and study design limitations beyond the imaging domain.
Recommendations: Toward More Rigorous AI Imaging Trials
The limitations identified across these three major reviews are not insurmountable, but they require a concerted effort from researchers, funders, journal editors, and regulators to raise the bar for evidence quality. The following recommendations are derived directly from the gaps documented in the literature.
- Mandatory adherence to AI-specific reporting standards. Journals should require that all AI imaging trials cite and follow CONSORT-AI (for RCTs), STARD-AI (for diagnostic accuracy studies), or TRIPOD-AI (for prediction model studies) as a condition of publication. The finding that only 19% of post-2021 RCTs cited CONSORT-AI is unacceptable four years after the extension was published.
- Multicenter prospective designs with prespecified sample sizes. Single-center studies should be treated as pilot or feasibility work, not as definitive evidence. Funders and journals should prioritize multicenter prospective studies with sample size calculations that are justified by the expected effect size and the clinically meaningful difference.
- Inclusion of patient-relevant outcomes. Diagnostic accuracy metrics (AUC, sensitivity, specificity) are necessary but not sufficient. Trials should also measure outcomes that matter to patients and clinicians: changes in clinical management, time to diagnosis, diagnostic confidence, and — where feasible — downstream clinical outcomes.
- Routine demographic reporting. All studies should report the race, ethnicity, age, sex, and socioeconomic status of the study population. This is essential for assessing algorithmic fairness and generalizability. Journals should enforce this as a reporting requirement.
- Independent external validation. AI algorithms should be validated on datasets that are geographically, demographically, and clinically distinct from the training data. This is particularly important for algorithms developed in single-center or single-country settings.
- Preregistration of analysis plans. All AI imaging trials should be preregistered on ClinicalTrials.gov or a comparable registry, with the analysis plan specified in advance. This reduces the risk of selective outcome reporting and data dredging.
- Post-market surveillance frameworks. Regulatory agencies should require post-market surveillance studies for AI devices, particularly those cleared through the 510(k) pathway. The PCCP framework provides a mechanism for managing algorithm updates, but it does not replace the need for ongoing real-world evidence collection.
Similar evidence quality concerns exist in other AI application areas within healthcare. For example, our analysis of AI in pathology: whole slide imaging and the evidence gap identifies many of the same methodological challenges — single-center designs, limited external validation, and lack of standardized reporting. The field as a whole would benefit from a coordinated effort to raise evidence standards.
Conclusion: What the Evidence Actually Supports — and What It Doesn't
The evidence base for AI medical image analysis is at a critical juncture. On one hand, the volume of published research is impressive: 86 RCTs, 279 diagnostic accuracy studies, and 48 real-world implementation studies, with 1,451 FDA-authorized devices. On the other hand, the methodological quality of this evidence is substantially weaker than the headline performance metrics suggest.
The core findings of this meta-research critical appraisal can be summarized as follows:
- AI shows genuine promise across multiple imaging specialties, with high reported AUCs in ophthalmology, respiratory imaging, and breast imaging, and 81% of RCTs reporting positive primary endpoints.
- However, the evidence base is constrained by single-center designs (63% of RCTs, 62.5% of implementation studies), limited external validation, rare prospective data collection, and a lack of patient-relevant outcomes.
- Risk of bias is high across the diagnostic accuracy literature, with >75% of studies rated as high or unclear risk in patient selection and flow/timing domains on QUADAS-2.
- Real-world workflow benefits remain unproven at the meta-analytic level, despite widespread subjective reports of time savings.
- Adherence to AI-specific reporting standards (CONSORT-AI, STARD-AI) is unacceptably low, undermining transparency and reproducibility.
The path forward requires the field to prioritize evidence quality over publication volume. Researchers must design multicenter, prospective studies with prespecified sample sizes, patient-relevant outcomes, and routine demographic reporting. Journal editors must enforce adherence to AI-specific reporting standards. Regulators must require post-market surveillance and independent external validation. And clinicians and health systems must evaluate AI tools based on the quality of the evidence, not just the reported performance metrics.
Comments
Join the discussion with an anonymous comment.