Introduction: The Transition Point in Medical Image Analysis
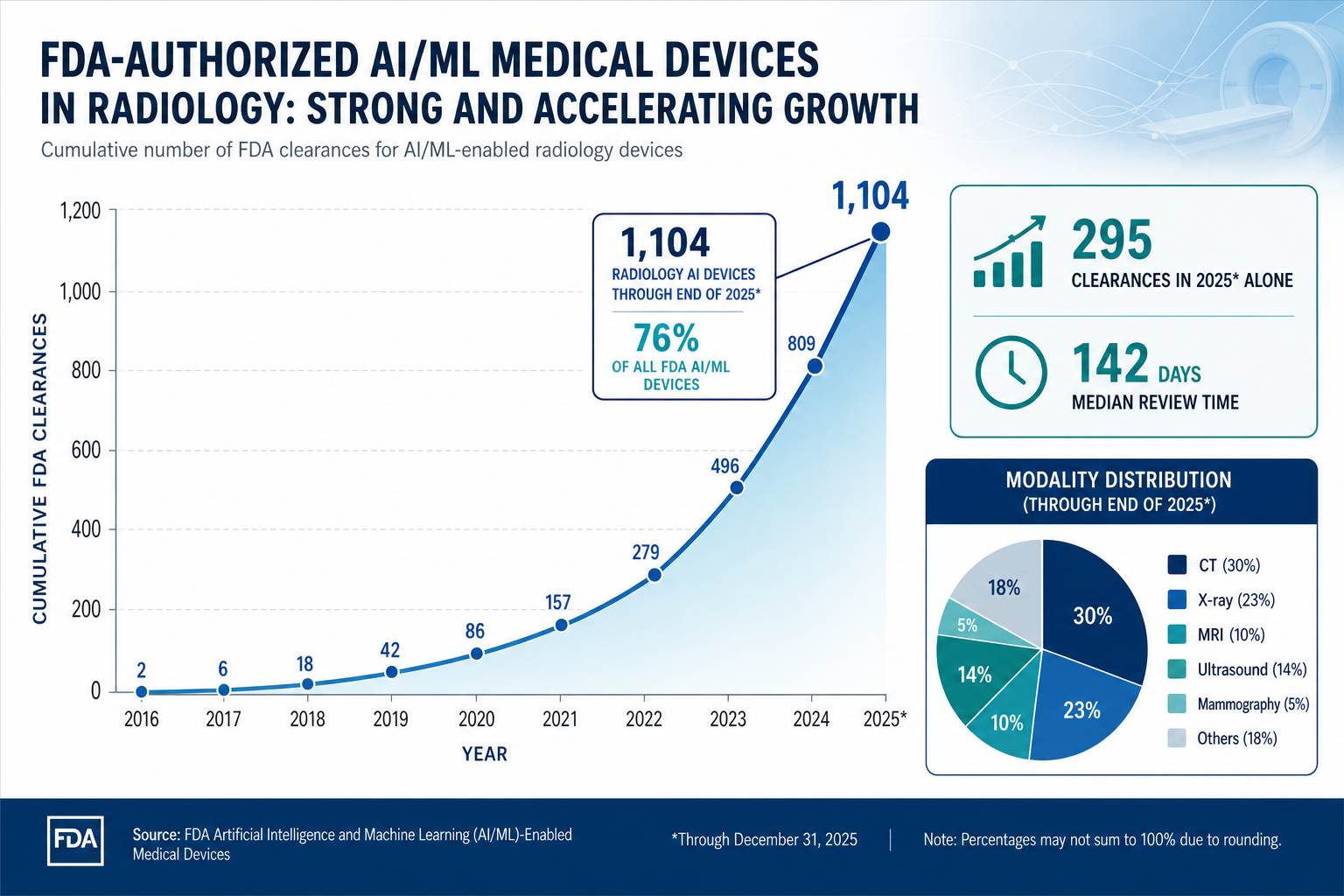
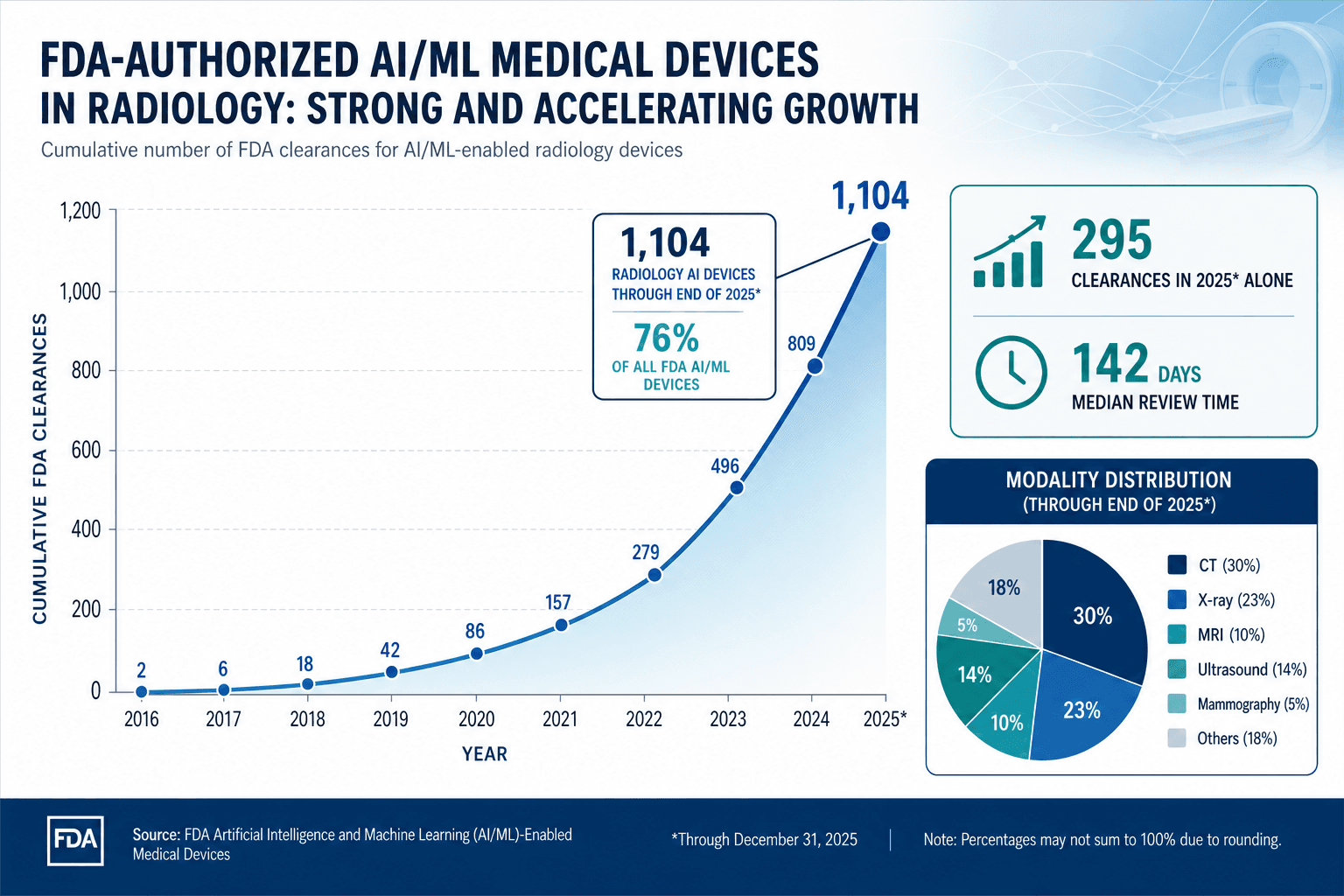
The field of AI in medical image analysis has crossed a threshold. As of the end of 2025, the FDA had authorized 1,104 radiology AI devices, representing 76% of all AI/ML-enabled medical devices. In 2025 alone, 295 new clearances were granted, with a median review time of 142 days. These numbers signal a shift from proof-of-concept to regulatory volume. Yet the same data that documents this rapid adoption also reveals the gap between regulatory clearance and clinical maturity: most devices lack prospective validation, few have published real-world evidence, and the challenges of bias, generalizability, and workflow integration remain unresolved.
This article provides a structured assessment of where AI in medical imaging stands clinically as of mid-2026. It is organized around the imaging-specific technical pipeline — enhancement, segmentation, detection, diagnosis, and prognosis — and examines the evidence by clinical domain, the regulatory landscape, and the persistent limitations that prevent full operational maturity. The focus is deliberately narrow: medical image analysis, not diagnostic AI broadly, not radiology triage specifically, and not the general AI-in-healthcare landscape. Readers seeking broader context can refer to the site's overview of AI in medical diagnosis or the specialty-by-specialty deployment survey.
Scale of Adoption: Market Size and FDA Clearance Breakdown
The global AI in medical imaging market was valued at approximately $1.36 billion in 2024 and is projected to reach $19.78 billion by 2033, representing a compound annual growth rate (CAGR) of 34.67% from 2025 to 2033, according to Grand View Research data cited by Avenga. A 2024 survey of European radiologists found that 48% were already using AI tools in their practice, with an additional 25% planning implementation.
The FDA's cumulative count of AI-enabled medical devices reached 1,451 through the end of 2025. Radiology dominates this list with 1,104 devices, or 76% of all authorized AI/ML medical devices. In Q4 2025 alone, 55 of 72 new clearances (76%) were for radiology applications. The 2025 clearance volume of 295 devices came from 221 unique manufacturers, with 183 manufacturers (83%) receiving only a single clearance.
| Metric | Value | Source |
|---|---|---|
| Cumulative FDA AI/ML devices (end of 2025) | 1,451 | The Imaging Wire |
| Radiology devices (cumulative) | 1,104 (76%) | The Imaging Wire |
| New clearances in 2025 | 295 | Innolitics |
| Median clearance time (2025) | 142 days | Innolitics |
| Devices with PCCPs (2025) | 30 (10%) | Innolitics |
| Market size (2024) | $1.36 billion | Avenga / Grand View Research |
| Projected market size (2033) | $19.78 billion | Avenga / Grand View Research |
The leading companies by cumulative radiology AI authorizations are GE HealthCare (120), Siemens Healthineers (89), Philips (50), Canon (45), United Imaging (38), Aidoc (31), and DeepHealth (28). Shanghai United Imaging Healthcare led all manufacturers in 2025 with 10 clearances. The top product code was QIH (Radiological Computer Assisted Detection/Diagnosis) with 75 clearances, reflecting the dominance of computer-aided detection and diagnosis tools.
Technical Foundations: How Deep Learning Powers the Imaging Pipeline
The AI systems deployed across medical imaging rely on a set of well-established deep learning architectures, each suited to specific tasks within the five-stage imaging pipeline: image enhancement, segmentation, detection, diagnosis, and prognosis. Understanding these technical foundations is essential for evaluating claims about performance and generalizability.
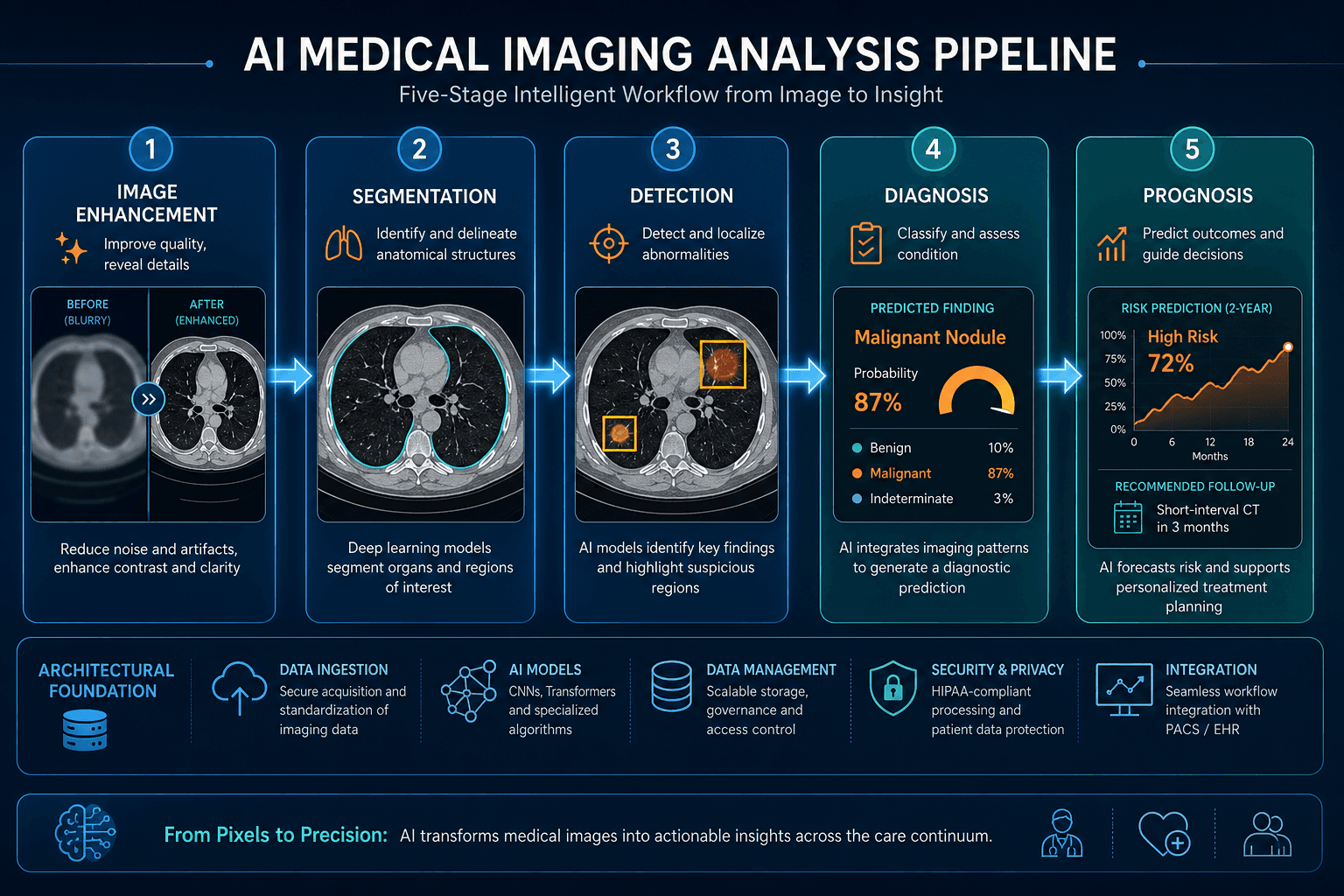
| Pipeline Stage | Common Architectures | Representative Application | Reported Performance |
|---|---|---|---|
| Image Enhancement | RED-CNN, CRNN | Low-dose CT denoising (RED-CNN); cardiac MRI reconstruction (CRNN) | RED-CNN: PSNR 39.196, SSIM 0.934; CRNN: 3s vs 451s for k-t SLR |
| Segmentation | U-Net, FCNN | Multi-organ thoracic segmentation (U-Net); brain tumor segmentation (FCNN) | U-Net: dice 97.0% (lungs), 90.0% (spinal cord); FCNN: dice 87.0% (brain tumor) |
| Detection | YOLOv10, R-CNN | Pediatric wrist fracture detection (YOLOv10); micro-calcification detection in mammograms (R-CNN) | YOLOv10: mAP 51.9% (8.6% improvement over YOLOv9); R-CNN: >90% sensitivity, 0.4-1.0 FP/scan |
| Diagnosis | CNN-based classifiers, GPT-4 | Lung cancer benign/malignant classification; cervical cell classification; thyroid nodule diagnosis | Lung cancer: avg accuracy 90.7% (95% CI 89.5-92.0%); cervical cell: accuracy 0.999; GPT-4 thyroid: 78-86% |
| Prognosis | PET/CT models, survival CNNs | Lung cancer progression prediction; overall survival prediction | PET/CT: accuracy 0.790; avg C-index 0.730 for lung cancer prognosis |
The performance figures in the table above come from a 2025 systematic review by Wang et al. that analyzed 52,705 English-language articles published between 2004 and 2023 using LDA topic modeling. These metrics represent pooled averages or best-reported results from individual studies, not necessarily the current state-of-the-art for each task. The review also noted that over 60% of clinicians harbor reservations about large language model ethics, including concerns about hallucinations and misinformation, highlighting that technical performance alone does not determine clinical acceptance.
Clinical Evidence by Domain: Mammography, Lung Cancer, Stroke, and Pathology
Mammography: Prospective Evidence from Large-Scale Implementation Studies
Mammography screening has produced some of the strongest prospective evidence for AI in medical imaging. Two large-scale studies published in early 2025 — AI-STREAM and PRAIM — provide complementary data on the real-world impact of AI-assisted reading.
The AI-STREAM study, a prospective multicenter cohort from South Korea published in Nature Communications, enrolled 24,543 women aged 40 years or older. Breast radiologists using AI-CAD detected 140 cancers (5.70 per 1,000) versus 123 (5.01 per 1,000) without AI, a statistically significant 13.8% increase in cancer detection rate (p<0.001), with no significant change in recall rate (4.53% vs 4.48%, p=0.564). AI assistance detected 6 additional DCIS and 11 additional invasive cancers, and significantly increased detection of small cancers (<20mm), node-negative metastasis, and luminal A subtype. Notably, general radiologists using AI-CAD showed an even greater 26.4% increase in CDR (4.89 vs 3.87 per 1,000, p<0.001), but with a significant increase in recall rate (6.89% vs 6.31%, p<0.001).
The PRAIM study, an observational implementation study in Germany's organized screening program published in Nature Medicine, involved 463,094 women (260,739 AI-supported) across 12 sites and 119 radiologists. AI-supported double reading achieved a breast cancer detection rate of 6.7 per 1,000, 17.6% higher (95% CI +5.7%, +30.8%) than standard double reading (5.7 per 1,000). The recall rate was noninferior at 37.4 vs 38.3 per 1,000 (-2.5%, 95% CI -6.5% to +1.7%). The positive predictive value of recall was 17.9% (AI) vs 14.9% (control), and the PPV of biopsy was 64.5% (AI) vs 59.2% (control). The AI system used a decision referral approach: 56.7% of exams were triaged as normal with a median reading time of 16 seconds, and a safety net triggered in 1.5% of exams led to 204 additional breast cancer diagnoses.
| Study | Design | Sample Size | CDR Increase | Recall Rate Change |
|---|---|---|---|---|
| AI-STREAM (South Korea) | Prospective multicenter cohort | 24,543 women | +13.8% (breast radiologists); +26.4% (general radiologists) | No significant change (breast radiologists); +0.58% (general radiologists) |
| PRAIM (Germany) | Observational implementation | 463,094 women (260,739 AI-supported) | +17.6% (6.7 vs 5.7 per 1,000) | Noninferior: -2.5% (37.4 vs 38.3 per 1,000) |
Lung Cancer Screening and Diagnosis
Lung cancer remains the leading cause of cancer death worldwide, and AI has been applied across the care pathway from screening to prognosis. The Sybil model, a deep learning algorithm, predicted future lung cancer risk from a single low-dose CT scan with an AUC of 0.92 at 1 year and 0.75 at 6 years on NLST data, as reported in a 2025 npj Precision Oncology review by Zhu et al. AI-based LDCT screening tools achieve 94.6% sensitivity but 93.6% specificity, corresponding to a 6.4% false positive rate.
For diagnostic classification, a meta-analysis within the Wang et al. review found that AI-based models achieved an average accuracy of 90.7% (95% CI 89.5-92.0%) for distinguishing benign from malignant lung nodules across pooled studies. Accuracy for lung cancer subtyping was 84.9%. A deep learning algorithm developed by Google achieved 94.4% AUC on NLST cases, outperforming six radiologists with an 11% reduction in false positives and a 5% reduction in false negatives. For prognosis, combined PET/CT models achieved an accuracy of 0.790 for lung cancer progression prediction, with an average C-index of 0.730.
Stroke and Intracranial Hemorrhage Triage
AI-powered stroke triage tools have been among the most commercially successful radiology AI applications, with multiple FDA-cleared products from companies including Aidoc, Viz.ai, and RapidAI. These tools automatically detect intracranial hemorrhage, large vessel occlusion, and other acute findings on non-contrast CT and CT angiography, flagging cases for immediate radiologist review. The clinical value proposition is clear: reducing time to treatment in acute stroke directly improves outcomes. For a detailed analysis of triage-specific tools and their evidence base, see the site's dedicated article on AI Triage in Radiology.
Pathology AI: High Accuracy in Controlled Studies
Digital pathology has emerged as a parallel domain to radiology for AI applications, though the regulatory landscape is less developed. The Wang et al. review reported that deep learning models achieved a classification accuracy of 0.989 for bone marrow cell classification and 0.999 for binary cervical cell classification. These figures come from controlled research settings and may not reflect real-world performance across diverse laboratory conditions and staining protocols.
Regulatory Landscape: FDA Clearances, PCCPs, and the EU AI Act
The regulatory environment for AI in medical imaging is evolving rapidly, driven by the volume of new clearances and the unique challenges posed by continuously learning algorithms. The FDA's 2025 clearance data, analyzed by Innolitics, reveals several important trends.
| Regulatory Feature | 2025 Data | Implication |
|---|---|---|
| Total AI/ML clearances | 295 devices from 221 manufacturers | Sustained high volume; 83% of manufacturers had only one clearance |
| Median clearance time | 142 days (average 150 days) | Relatively efficient pathway for 510(k) devices |
| Software as a Medical Device (SaMD) | 62% of clearances | Majority are standalone software, not hardware-integrated |
| Diagnostic vs. other intended use | 63% diagnostic | Screening and diagnostic tools dominate |
| Predetermined Change Control Plans (PCCPs) | 30 devices (10%) | FDA beginning to authorize iterative learning algorithms |
| Radiology share | 71.5% (211 clearances) | Radiology remains the dominant specialty |
The emergence of Predetermined Change Control Plans (PCCPs) in 10% of 2025 clearances represents a significant regulatory development. PCCPs allow manufacturers to specify in advance how their AI algorithm will be updated over time, enabling iterative improvements without requiring a new 510(k) submission for each change. This mechanism is critical for the long-term viability of AI in medical imaging, where models must adapt to new imaging protocols, scanner models, and patient populations. For a detailed analysis of PCCPs and the FDA's evolving approach to lifecycle regulation, see the dedicated article on FDA regulation through PCCPs and TPLC.
Internationally, the EU AI Act is set to impose additional requirements on high-risk AI systems, including many medical imaging tools. Article 10 of the Act mandates that training datasets be "relevant, representative, error-minimal, and complete" and requires bias examination for high-risk systems. The Act is scheduled to fully take effect in 2026, which will create new compliance obligations for companies marketing AI imaging tools in Europe.
Limitations and Challenges: Bias, Generalizability, and Workflow Friction
Despite the volume of FDA clearances and the accumulation of prospective evidence, significant challenges prevent AI in medical imaging from achieving full operational maturity. These challenges fall into three broad categories: bias in datasets and algorithms, limited generalizability across clinical settings, and persistent workflow integration friction.
Bias Taxonomy in Medical Imaging AI
A comprehensive 2025 international collaborative review by Koçak et al. provides a detailed taxonomy of bias types specific to medical imaging AI. The review identifies six major categories:
- Demographic bias: Gender, racial, and socioeconomic imbalances in training datasets produce classifiers that perform poorly on underrepresented groups. Fewer than 6% of published radiology AI articles share their experimental data, making independent bias audits difficult.
- Annotation bias: Variability in how radiologists label training data can introduce systematic errors, particularly for ambiguous findings.
- Automation bias: A 2023 Radiology study documented that radiologists using AI-CAD in mammography may over-rely on the AI's output, potentially missing findings the AI did not flag.
- Feedback loop bias: AI recommendations that influence radiologist behavior can create self-reinforcing cycles, where the AI's errors become embedded in future training data.
- Deployment bias: Models trained on data from one institution or scanner manufacturer may fail when deployed in a different setting.
- Concept drift: Changes in imaging technology, population health, or clinical practice over time can degrade model performance.
The review discusses detection tools including PROBAST-AI (under development) and QUADAS-2, and mitigation strategies such as preprocessing re-sampling, in-processing adversarial debiasing, and post-processing equalized odds. The EU AI Act's Article 10 requirements for training data represent a regulatory push toward addressing these biases, but the tools for systematic bias detection and mitigation are still maturing.
Generalizability Gaps
A 2021 systematic review and meta-analysis by Aggarwal et al. in npj Digital Medicine, covering 503 studies across medical specialties, found high heterogeneity in diagnostic accuracy estimates. Only 8 ophthalmology, 10 respiratory, and 6 breast imaging studies adhered to STARD-2015 reporting guidelines. QUADAS-2 assessment showed that the majority of studies were at high risk of bias, particularly in patient selection, flow/timing, and reference standard applicability. The review highlighted the need for AI-specific reporting standards (STARD-AI, TRIPOD-AI) and standardized methodology to prevent overestimation of diagnostic accuracy.
The generalizability challenge is compounded by the fact that most AI models are trained on data from a limited number of institutions, often using specific scanner models. The npj Precision Oncology review on lung cancer AI noted variability across imaging protocols, scanner manufacturers, and radiation dose levels as a key reproducibility issue. Without external validation on diverse, multi-institutional datasets, reported performance metrics may not translate to real-world clinical practice.
Workflow Integration and Computational Constraints
The Avenga industry article notes that AI models "do not add value in isolation" but must be integrated into clinical workflows to enhance decision-making. This integration remains a significant operational challenge. Many AI tools require dedicated workstations, separate from the PACS or EHR, creating additional steps for radiologists. The computational resource consumption of deep learning models, particularly for real-time applications like CT reconstruction or MRI acceleration, can strain existing IT infrastructure.
The Wang et al. review also noted that over 60% of clinicians harbor reservations about LLM ethics, including concerns about hallucinations and misinformation. While this figure specifically addresses large language models rather than traditional computer vision AI, it reflects a broader skepticism about AI reliability that affects adoption across all applications.
Outlook: The Path to Operational Maturity
AI in medical image analysis has clearly moved beyond the proof-of-concept stage. The volume of FDA clearances — 1,104 radiology devices, 295 new clearances in 2025 alone — demonstrates that the technology is being commercialized at scale. The prospective evidence from mammography (AI-STREAM, PRAIM) and lung cancer screening (Sybil) shows that AI can improve clinical outcomes in controlled and real-world settings. The emergence of PCCPs signals that regulators are adapting their frameworks to accommodate iterative learning algorithms.
Yet the path to full operational maturity requires addressing several fundamental gaps. First, the evidence base remains uneven: mammography and lung cancer screening have strong prospective data, but many other applications rely on retrospective studies with limited external validation. Second, bias and generalizability challenges are not theoretical — they are documented in the literature and embedded in the structure of training datasets. Third, workflow integration remains a practical barrier that no amount of regulatory clearance alone can solve.
The field is at a transition point. The next phase will require moving from regulatory volume to clinical value: prospective validation across diverse populations, systematic bias audits using tools like PROBAST-AI, lifecycle regulatory oversight through PCCPs, and genuine workflow integration that reduces rather than adds to radiologist cognitive load. For a broader perspective on what the clinical evidence across all healthcare AI actually shows, see the Artificial Intelligence and Health overview.
Comments
Join the discussion with an anonymous comment.