
97.7% – But What Did They Actually Measure?
Start with the most impressive number you will see in this article: a randomized crossover trial in a cardiovascular clinic found that an AI-enabled voice assistant captured SARS-CoV-2 screening histories with 97.7% overall agreement compared to human staff, with an unweighted kappa of 0.93. Eighty-seven percent of participants rated the experience good or outstanding. That sounds like a solved problem.
It is not a solved problem. The VOICE-COVID-19-II trial enrolled 52 participants from a single heart failure clinic. The task was narrow: a structured screening questionnaire with yes/no answers. The setting was controlled. The population was limited. This is the best evidence we have for conversational AI on a bounded clinical task, and it is genuinely good evidence. But it tells you nothing about how the same system would handle an open-ended diagnostic question, a patient with atypical symptoms, or a language it was not trained on.
Here is what I am going to show: conversational AI achieves near-human accuracy on well-bounded, repetitive clinical tasks like screening and triage, but falls well below specialist-level performance on open-ended diagnostic reasoning. And the equity and safety gaps that accompany both ends of the spectrum are documented but poorly addressed by current regulatory frameworks.
The Real Performance Gap: 45–55% vs. 87–92%
The strongest evidence for the open-ended side comes from Hager et al. (2024), who evaluated three LLMs on diagnostic accuracy for four common abdominal pathologies using 2,400 real patient cases from the MIMIC-IV database. This is not a toy benchmark. The study tested two modes: a full-information setting where models received all relevant clinical data, and an autonomous mode where they had to gather information themselves, simulating a clinician's workflow.
| Condition | Physician accuracy | Best LLM accuracy (full info) | Best LLM accuracy (autonomous) |
|---|---|---|---|
| Appendicitis | 87.5–92.5% | 82.0% | ~55% |
| Cholecystitis | 87.5–92.5% | 67.8% | ~50% |
| Diverticulitis | 87.5–92.5% | 58.8% | ~45% |
| Pancreatitis | 87.5–92.5% | 60.2% | ~50% |
The gap is stark. Physicians averaged 87.5–92.5% accuracy across all conditions; the best LLM (OASST) reached 67.8% in the full-information scenario. In autonomous mode, accuracy dropped to 45–55%. That is not a marginal difference. It is the difference between a system that can assist and a system that cannot be trusted to act alone.
What concerns me more is how the models failed. They did not merely miss diagnoses. They failed to order necessary tests: OASST ordered pancreatic enzymes only 56.5% of the time for pancreatitis cases. They recommended inappropriate treatments, such as failing to recommend colectomy for perforated diverticulitis. They hallucinated nonexistent medical instruments every two to five patients. Their performance was sensitive to the order in which information was presented, varying by up to 18 percentage points. These are not glitches. They are fundamental limitations of current architectures.
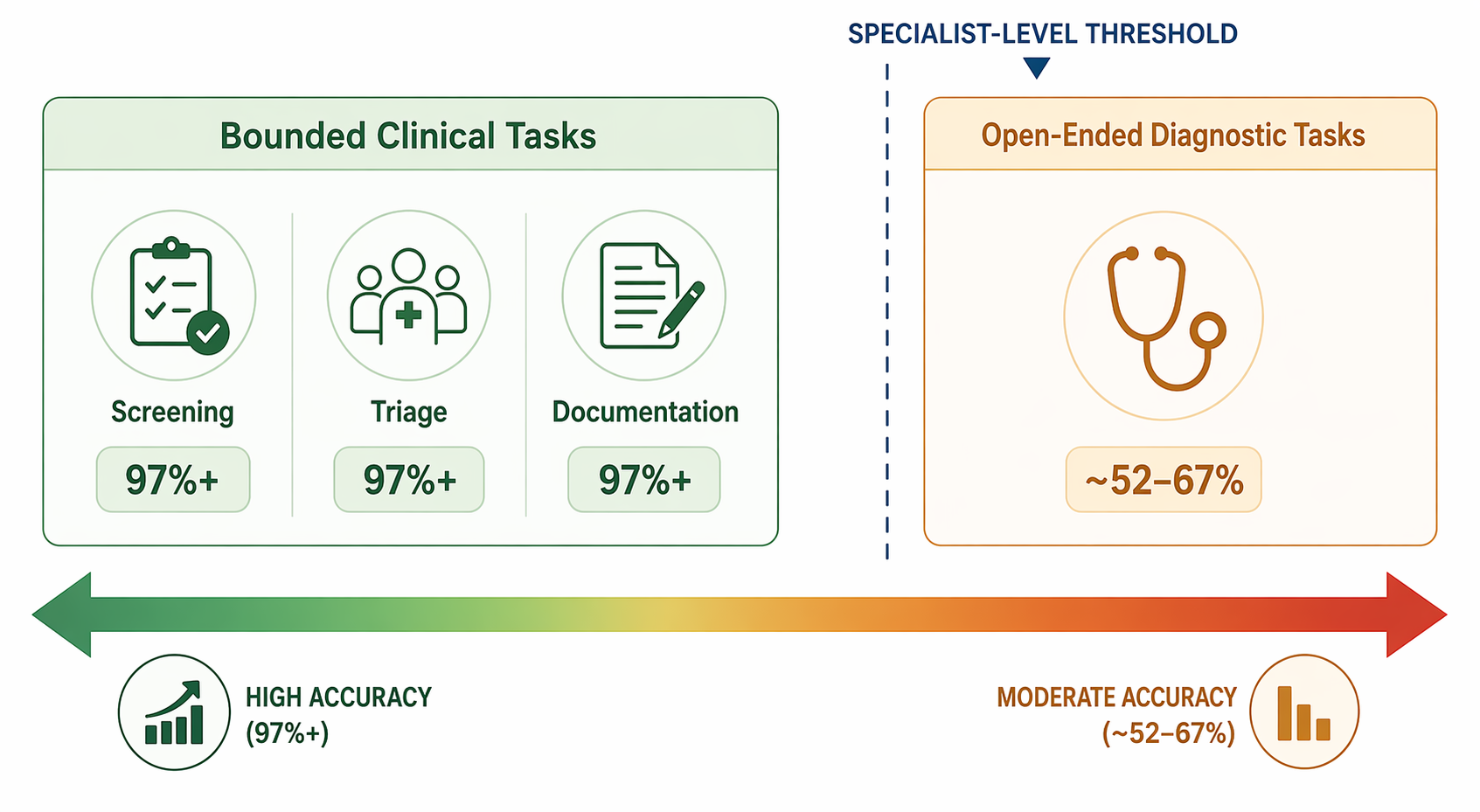
This evidence aligns with a broader 2026 evidence review on AI diagnostic accuracy that found generative AI models averaged roughly 52% diagnostic accuracy across a meta-analysis of 83 studies — on par with non-expert clinicians but well below specialists. The pattern across studies is consistent: narrow, well-defined tasks are within reach; open-ended clinical reasoning is not.
Language Adaptation – A Step, Not a Fix
One of the most promising findings for conversational AI in healthcare is its ability to adapt to different languages. A multilingual generative AI voice agent deployed for colorectal cancer screening among underserved populations achieved a FIT test opt-in rate of 18.2% among Spanish-speaking patients versus 7.1% among English speakers, with longer call durations suggesting deeper engagement. Similarly, a study of a multilingual mental health AI agent found that Spanish-speaking users recorded significantly more and longer sessions in the Spanish version than English-speaking users in the English version.
These results suggest language-adapted AI can improve access. But they do not automatically mean equity is being served. The question is whether closing the language gap merely shifts the disparity to other dimensions — literacy, digital access, prompt familiarity — or actually closes it. A commentary in the Journal of Communication in Healthcare (Uddin, 2025) documents that LLM-based chatbots often produce inaccurate or biased responses due to reliance on user-generated prompts and publicly available training data, and that these limitations disproportionately impact populations with limited digital or health literacy. This is a documented risk, but the evidence base is still thin — it points to a real danger, not a proven failure.
Preprint Promise, Published Failures, and a Regulatory Vacuum
You will see vendors citing a large-scale safety evaluation involving over 307,000 simulated patient interactions, reviewed by licensed clinicians, suggesting generative voice agents can achieve medical advice accuracy exceeding 99% with no instances of potentially severe harm. That figure is striking. It is also from a preprint that has not yet been peer-reviewed. I do not dismiss it — large-scale simulations are valuable — but I do not treat it as equivalent to published randomized trial data.
What the published literature actually shows is different. In Hager et al., LLMs made errors in following instructions every two to four patients. They hallucinated nonexistent tools every two to five patients. They recommended inappropriate treatments for severe conditions. The mental health chatbot meta-analysis (Li et al., 2023, 15 RCTs, 1,744 participants) found a significant reduction in depression symptoms (Hedges' g 0.64), but the heterogeneity across studies was extreme (I² > 90%), and the GRADE quality of evidence was moderate. That effect size is not settled. It is a signal worth investigating, not a proven benefit.
The safety evidence is uneven. A single preprint does not outweigh dozens of published studies documenting failures. The responsible position is to demand replicated, peer-reviewed safety evaluations before deploying these systems in clinical settings where harm is possible.
Now add the regulatory problem: the FDA has authorized over 1,000 AI/ML-enabled medical devices through traditional premarket pathways. But regulators acknowledge that adaptive and generalized AI systems challenge frameworks designed for static, single-indication devices. The problem is acute for conversational AI: a voice agent can function as an unregulated communication tool when providing general health information, and as a Software as a Medical Device (SaMD) requiring FDA clearance when it gives specific clinical recommendations — within the same platform, even within the same interaction.
This regulatory straddle creates a dangerous ambiguity. Who is responsible when a system gives incorrect advice in a context where its regulatory classification is unclear? The existing evidence gap for FDA-cleared AI devices applies here as well: only about 2% of FDA-authorized AI devices have published clinical trial evidence. For conversational AI, the proportion is likely lower. The broader generative AI policy landscape in 2026 underscores that regulatory frameworks have not kept pace with the flexibility of these systems.
When a conversational AI system can be both an unregulated communication tool and a SaMD depending on the function it performs, who is responsible for harm? The framework does not answer that question.
What Regulators Should Do – and What They Shouldn't
The evidence supports a clear performance spectrum: bounded screening and triage tasks can match human accuracy under the right conditions. Open-ended diagnostic tasks remain 30 percentage points below specialist level, with concrete failures that are not theoretical. Equity risks are documented but mostly unaddressed. Safety evidence is uneven — a promising preprint cannot offset dozens of published failure reports.
Regulatory frameworks must begin differentiating by task type. A system that performs a narrow, well-validated screening function should face a different evidence bar than a system that attempts open-ended clinical reasoning. Equity audits should be mandatory, not optional. And the safety evaluation standard must be peer-reviewed, not vendor-reported simulation data.
This article is not an argument against conversational AI in healthcare. It is an argument for matching claims to evidence, for designing regulatory structures that fit the technology they govern, and for protecting the patients who stand to benefit — or be harmed — by systems whose capabilities are still unevenly understood.
Comments
Join the discussion with an anonymous comment.