80% Adoption? It Measures Breadth, Not Depth
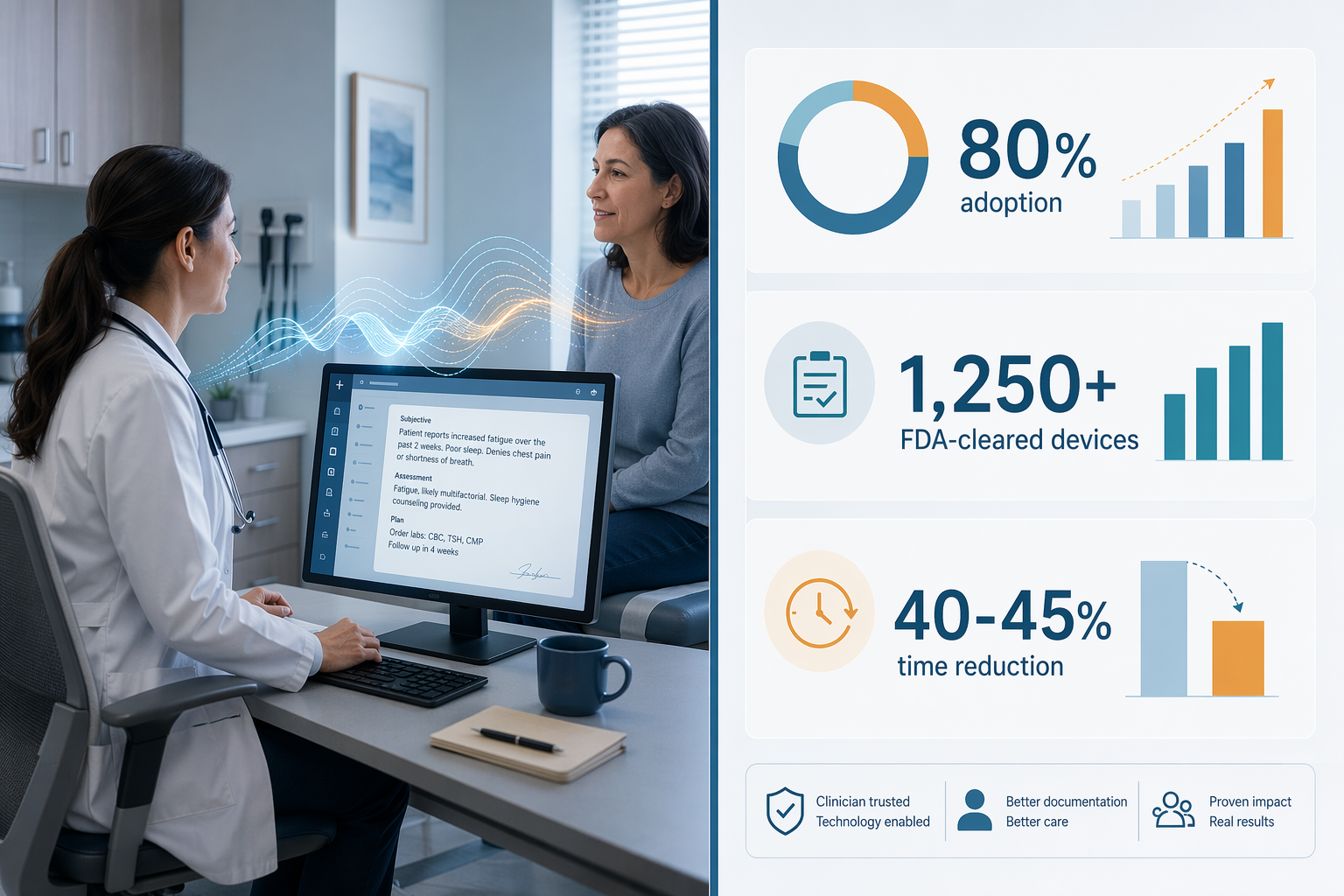
Roughly 80% of hospitals report using AI to enhance patient care or workflow efficiency, according to American Hospital Association surveys. That number sounds like a victory lap—evidence that the technology has crossed the chasm from pilot to standard practice.
I do not trust adoption numbers that do not distinguish between a single radiology triage tool and a system that actually changes clinical decisions. The figure that matters more is the one underneath: under 20% of institutions report sustained, high-success use of AI in core clinical diagnosis. A NEJM Catalyst survey from late 2025 makes the picture concrete: many organizations use AI for drafting notes or administrative tasks, but few employ it to augment clinical workflows or truly transform care. The breadth of adoption is real; the depth is not.
This article is an evidence-grounded assessment, not another market-size projection. The central finding: narrow models succeed on bounded prediction and documentation tasks; general-purpose systems underperform on open-ended clinical reasoning; and a surprising number of high-profile applications lack real-world outcome data. For a broader look at the research evidence landscape, see our existing review.
Prediction Works When the Question Is Narrow
The strongest case for AI's value in 2026 comes from narrow prediction tasks—models trained to answer a single, binary question: will this patient deteriorate within the next 24 hours? These models benefit from a constrained action space and a clear, measurable outcome.
The Johns Hopkins TREWS system is the most cited example, and for good reason: across 590,000 patients, it caught sepsis an average of six hours earlier and reduced mortality by approximately 20%. That is not a simulated gain—it came from a prospective deployment with a real control group. Similarly, a model trained on continuous wearable vital signs (Scheid et al., Nature Communications 2025) predicted patient deterioration up to 8 to 24 hours before standard hospital alerts. At Cedars-Sinai, Aidoc's intracranial hemorrhage triage tool was associated with a mortality drop from 27.7% to 17.5%—a 10-percentage-point reduction. And the Mayo EAGLE trial showed that AI-ECG screening increased diagnosis of low ejection fraction by 32%.
These are not controlled benchmarks; they are real-world outcome improvements. What unites them: each model answers a clearly bounded question (sepsis yes/no, ICH present/absent, ejection fraction below threshold) and each was integrated into a workflow where the predicted event triggered a specific, protocolized action. For a deeper dive into the emergency medicine evidence, see our specialty analysis.
Documentation: Promising, but One Study Does Not Prove Much
I want to see multi-site replication before declaring victory.
That burnout figure comes from a single-site, single-arm study with a 30-day follow-up. The sample is modest—263 physicians from one institution—and the Hawthorne effect is real: clinicians using a new tool often report improvements simply because they know they are being observed. The Northwestern ROI is also a single-institution figure. The NEJM Catalyst survey placed ambient documentation in the low-complexity adoption tier, meaning it is widespread but rarely integrated deeply. The evidence is promising—maybe the strongest we have for any AI application in 2026—but it is thin. For additional context on adoption and ROI trends, see our industry analysis.
Diagnostics: High Accuracy, but Only in Radiology and a Few Others
Diabetic retinopathy detection at ~96% accuracy, breast cancer screening sensitivity at 90–92%, Paige Prostate sensitivity improved from 89.5% to 96.8%—these are the numbers that make headlines. They are also concentrated in a small number of specialties. By late 2025, the FDA had cleared roughly 1,250 AI/ML-enabled medical devices, and approximately 76% of them are in radiology. Pathology and ophthalmology account for most of the rest.
That concentration is not necessarily a bad thing—it reflects where the data and the clear regulatory pathway exist—but it means the claim "AI outperforms doctors in diagnosis" applies only to a narrow slice of medicine. The more troubling finding comes from Bedi et al. in JAMA 2025: a review of more than 500 medical AI studies found that only 5% used real patient data. The rest tested on exam-style questions, curated datasets, or synthetic cases. Five percent. That statistic makes me question how much of what we call evidence actually reflects clinical reality.
Generative AI: 50% Accuracy Is Medical Student Level, Not Safe for Autonomous Use
Generative AI—large language models, multimodal systems—is the most hyped category in healthcare AI. The evidence does not support the hype. A meta-analysis (PMC 2024) found that generative AI averaged approximately 50%+ diagnostic accuracy, which puts it in the range of medical students or non-specialist clinicians, well below specialist performance.
The deeper problem is not the average accuracy, but the brittleness. Bedi et al. (JAMA Network Open 2025) showed that when they modified standard medical multiple-choice questions so the correct answer became "none of the other answers," accuracy dropped sharply—in some cases by more than a third. McCoy et al. (NEJM AI 2025) found that on tests designed to measure reasoning under uncertainty, AI systems performed closer to medical students than to experienced physicians and tended to commit strongly to an answer even when ambiguity was high.
This is not to say generative AI has no role. In triage, second-opinion generation, or draft-and-review workflows, a system that performs at the level of a medical student could be useful. But for autonomous clinical reasoning—answering an open-ended differential diagnosis or generating a treatment plan without human oversight—the current evidence says it is not safe. For a closer look at the evidence gap in a specific setting, see our analysis of primary care AI.
Patient-Facing AI: Used by Millions, Studied on Almost Nobody
AI systems that interact directly with patients are spreading faster than almost any other form of clinical AI, but few studies track whether these tools reduce missed diagnoses or improve health over time.
The Stanford Medicine statement gets at the core problem: we have adoption data, but no safety or efficacy data. For a technology that gives medical advice to millions of people—many of whom may use it as a substitute for a doctor visit—the absence of outcome studies is not a neutral gap. It is a risk. Given the evidence we have, I would be reluctant to rely on any patient-facing AI chatbot for diagnostic advice until independent outcome studies demonstrate safety and effectiveness.
What the Evidence Map Looks Like in Early 2026
The evidence I have walked through can be summarized in a maturity map that categorizes AI applications by the strength of real-world outcome evidence, not by press release volume. Here is how the categories look in early 2026:
| Use Case Category | Evidence Strength | Real-World Outcomes | Recommended Action |
|---|---|---|---|
| Prediction (deterioration, sepsis) | Strong (multi-center, prospective) | Proven mortality reductions | Prioritize deployment with workflow integration |
| Documentation (ambient scribes) | Moderate (single studies, short follow-up) | Promising burnout reductions | Invest but demand multi-site replication |
| Diagnostics (radiology, pathology, ophthalmology) | Moderate (skewed distribution, limited real-patient data) | High accuracy in narrow tasks only | Adopt with population-specific validation |
| Generative AI (clinical reasoning) | Weak (benchmark-only, brittle) | No independent clinical decisions | Explore as triage tool only; do not rely for autonomous decisions |
| Patient-facing AI (chatbots) | None (adoption without outcome studies) | Unknown safety | Monitor for outcomes; do not treat as clinically validated |
The core thesis of this assessment holds: narrow AI models deliver on bounded prediction and documentation tasks, general-purpose systems lag, and the evidence base across the field is thinner than most market reports suggest. For clinicians and health system leaders evaluating AI tools, I recommend starting with the frame: what was the alternative, and what got measured? If the answer is "we compared it to nothing" or "we measured benchmark accuracy, not patient outcomes," proceed with caution. A practical evaluation framework is available in our clinician's guide.
The field is moving fast, but evidence moves slower. The gap between announcement and practice is not closing as quickly as the adoption numbers suggest. Being the health system that asks "what measured difference did it make?"—and does not accept an answer that only quotes benchmarks—is the most valuable position you can take.
Comments
Join the discussion with an anonymous comment.