

The Promise vs. The Reality: Quantifying the AI Research-to-Deployment Gap
The volume of published research on artificial intelligence in healthcare is staggering. A 2025 overview of 161 systematic reviews, published in Frontiers in Digital Health, identified 7,672 primary studies spanning 41 clinical fields. Diagnosis alone accounts for 44.4% of this literature, followed by prognosis (13.9%) and screening (9.3%). By any measure, the research enterprise is producing at a prodigious rate.
Yet the number of AI tools that have made the leap from academic paper to routine clinical workflow remains strikingly small. The FDA had authorized 1,451 AI-enabled medical devices by the end of 2025, but 76% of those are concentrated in a single specialty — radiology — and over 96% were cleared through the 510(k) pathway, which predicates new devices on substantially equivalent predecessors rather than requiring independent clinical evidence of efficacy. The disconnect between research output and clinical uptake is not a perception problem; it is a structural one.
For healthcare administrators, policy professionals, and translational researchers, understanding this gap is not an academic exercise. Decisions about procurement, workflow integration, and capital allocation depend on knowing which barriers are real, which are surmountable, and what conditions separate the handful of successful deployments from the thousands of studies that remain on the page.
This article examines the translational gap through three lenses rarely analyzed together: the quantified distribution of implementation barriers from a 2025 systematic review, the slow adoption of reporting standards like CONSORT-AI, and the specific conditions that enabled a small number of high-profile deployments to succeed. It concludes with a four-phase leadership roadmap for organizations seeking to bridge the gap.
The Three Most Common Barriers to Clinical AI Adoption
A 2025 systematic review of 47 articles published between 2019 and July 2024, indexed in PMC, identified 17 distinct categories of AI challenges in healthcare. The distribution is not uniform: three categories account for nearly 80% of all documented obstacles.
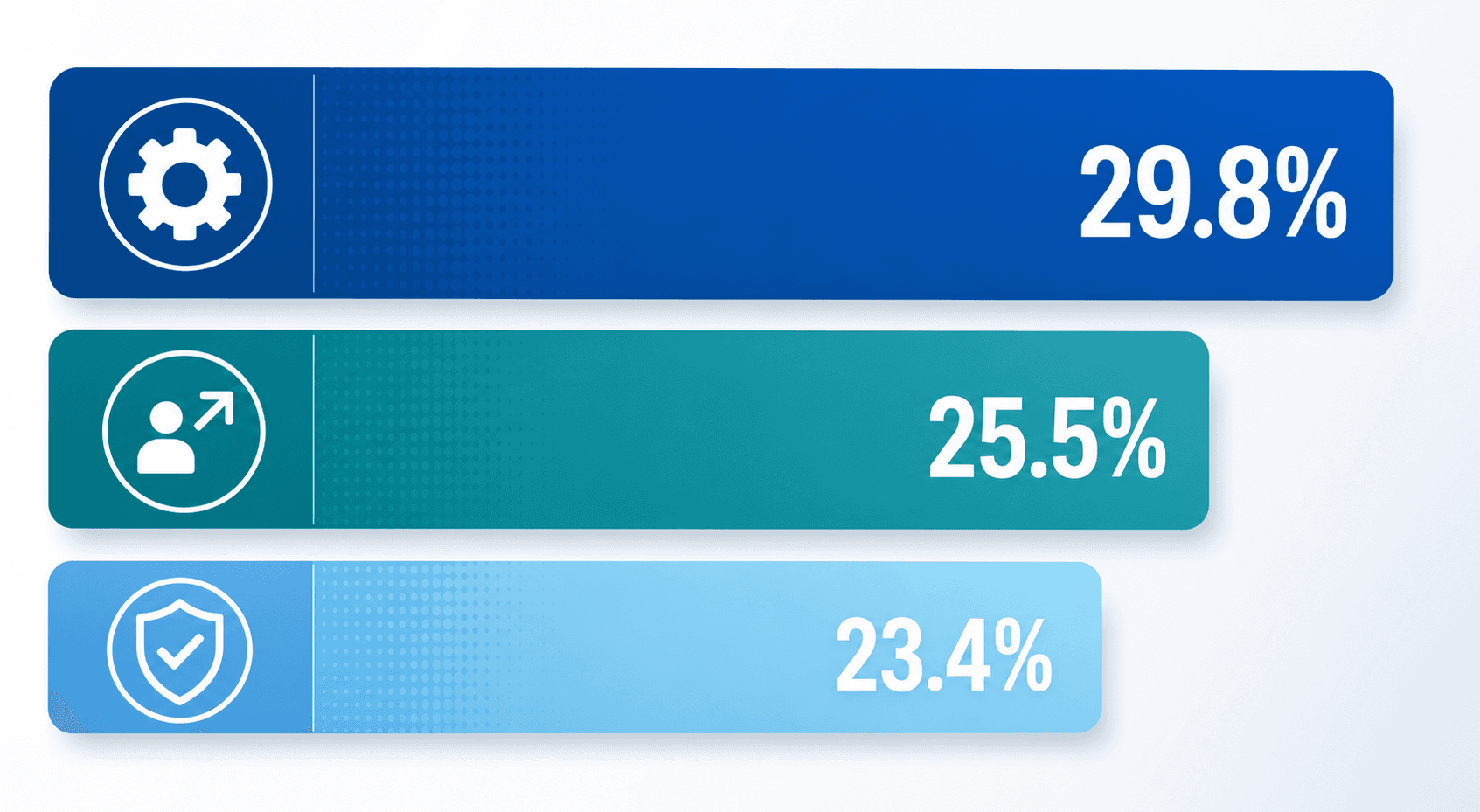
Technical Challenges (29.8%)
Technical obstacles were the most frequently cited barrier across the 47 reviewed studies. These include data quality and availability issues, model interpretability problems, integration with existing health IT infrastructure, and the computational resources required to train and deploy models at scale. The dominance of this category is not surprising: healthcare data is notoriously heterogeneous, fragmented across EHR systems, and subject to privacy regulations that limit data sharing.
Technology Adoption Barriers (25.5%)
Adoption barriers encompass clinician resistance, lack of trust in AI outputs, insufficient training, and workflow disruption. These are not merely cultural problems; they reflect legitimate concerns about how AI tools fit into clinical workflows that are already stretched thin. A tool that adds cognitive load or requires extra clicks, regardless of its technical performance, will face steep adoption resistance.
Reliability and Validity Concerns (23.4%)
Clinicians and administrators alike need assurance that an AI tool performs reliably across diverse patient populations and clinical settings. The review found that reliability and validity concerns — including questions about generalizability, performance degradation over time (model drift), and the lack of external validation — were the third most common barrier. This category is closely tied to the evidence-quality bottleneck discussed in the next section.
The distribution of challenges also varies by clinical domain. The same review found that psychiatry and cardiovascular medicine had the highest number of documented challenge categories — seven and six respectively — suggesting that certain specialties face a more complex set of obstacles than others.
The Evidence-Quality Bottleneck: Why Reporting Standards Matter
Even when AI research is published, its quality is often insufficient to support deployment decisions. The 2025 overview of 161 systematic reviews on AI in clinical medicine, led by Morone and colleagues, documented a series of reporting gaps that undermine the utility of the published literature.
| Reporting Dimension | Proportion of SRs Reporting It |
|---|---|
| All four key AI dimensions (input data, model type, training method, performance metrics) | 15.5% |
| Model training category | 25.6% |
| Any risk-of-bias analysis | Less than 50% |
| Risk-of-bias tools with AI-specific items | 39.2% |
| AI RCTs published after 2021 citing CONSORT-AI | 19% |
The finding that only 19% of AI-related randomized controlled trials published after 2021 cited the CONSORT-AI extension is particularly striking. CONSORT-AI was published in 2020 to address the unique reporting requirements of AI interventions — specifying how the AI tool was trained, what data it was validated on, how it was integrated into the clinical workflow, and what the human-AI interaction looked like. That fewer than one in five trials adhere to these guidelines means that the majority of published RCTs may lack the information needed to assess whether a tool is ready for deployment.
The implications for deployment are direct. An administrator evaluating an AI triage tool for chest X-rays cannot make an informed procurement decision if the published evidence does not specify the training dataset's demographic composition, the model's architecture, or the performance metrics used. The evidence-quality bottleneck is not an abstract academic concern; it is a practical barrier to adoption.
Data Challenges: Privacy, Silos, and the Promise of Federated Learning
Data-related obstacles cut across all three of the major barrier categories. Technical challenges arise because healthcare data is stored in fragmented, non-interoperable systems. Adoption barriers emerge when clinicians do not trust models trained on data that does not reflect their patient population. Reliability and validity concerns are amplified when models are trained on narrow, homogeneous datasets and then expected to perform across diverse real-world settings.
Privacy regulations — HIPAA in the United States, GDPR in Europe — impose necessary constraints on data sharing, but they also create silos that limit the size and diversity of training datasets. A model trained on data from a single academic medical center may not generalize to a community hospital with a different demographic profile, different imaging equipment, and different clinical workflows.
Federated learning has emerged as a promising technical solution to this problem. In a federated learning framework, the model is trained across multiple institutions without the raw data ever leaving each site's servers. Only model parameters — not patient data — are shared. This approach preserves privacy while enabling models to learn from more diverse datasets.
However, federated learning is not a panacea. It introduces its own technical challenges: communication overhead between sites, heterogeneity in data quality and labeling standards across institutions, and the difficulty of auditing model performance across all participating sites. As of mid-2026, federated learning remains a research tool rather than a widely deployed solution in clinical settings. Organizations exploring it should be prepared for significant engineering investment and should not expect plug-and-play deployment.
Navigating the Regulatory Landscape: 1,451 FDA-Authorized Devices and Counting
The regulatory environment for AI in healthcare has evolved rapidly, but its structure shapes — and in some ways limits — the path to clinical deployment. As of the end of 2025, the FDA had authorized 1,451 AI-enabled medical devices. The distribution across specialties and clearance pathways reveals important patterns.
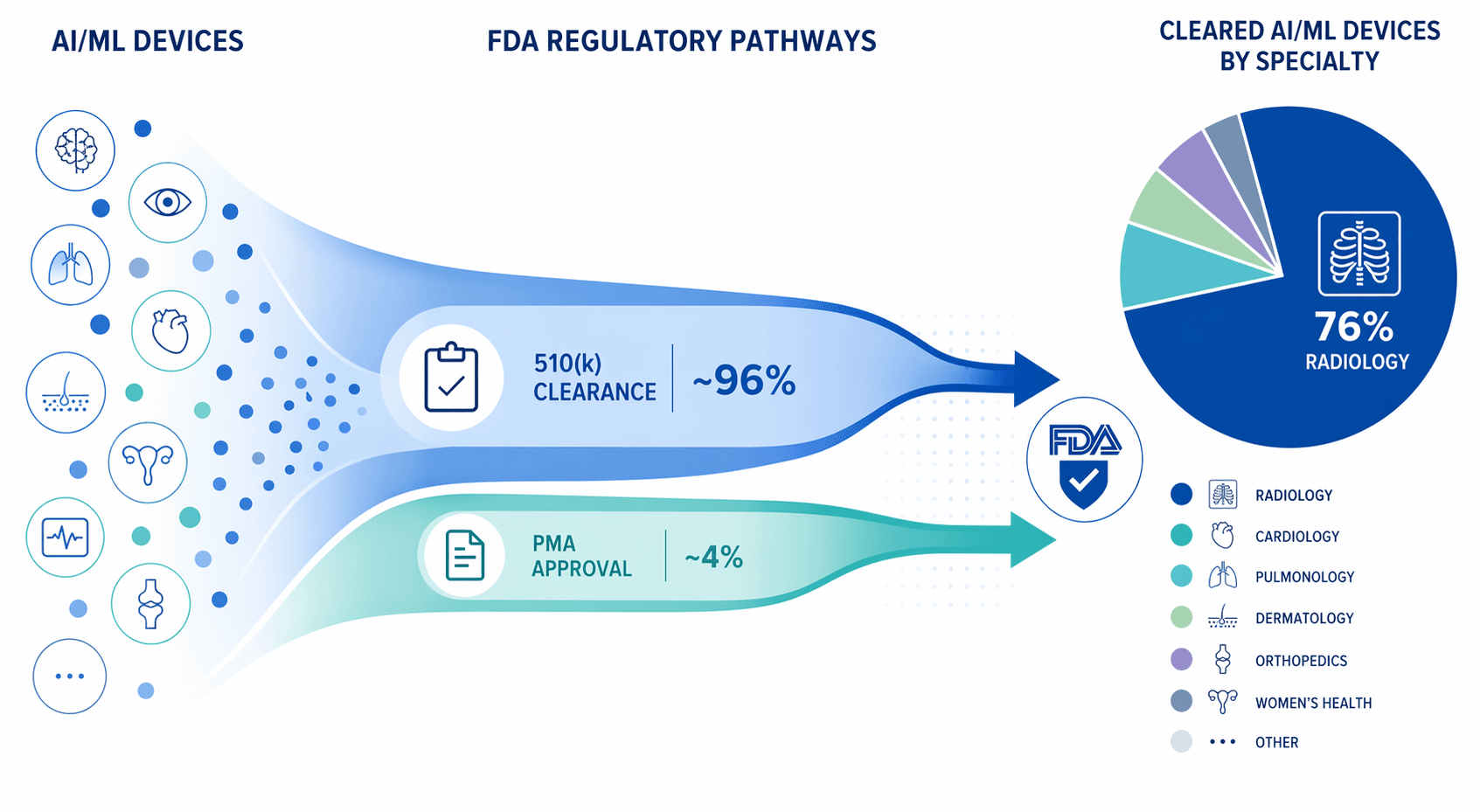
| Metric | Value |
|---|---|
| Total FDA-authorized AI devices (end of 2025) | 1,451 |
| Radiology devices | 1,104 (76%) |
| Devices cleared via 510(k) | Over 96% |
| Devices cleared in Q4 2025 | 72 |
| Radiology devices in Q4 2025 | 55 (76%) |
| Leading company (radiology authorizations) | GE HealthCare (120) |
| Second leading company | Siemens Healthineers (89) |
| Third leading company | Philips (50) |
The dominance of the 510(k) pathway — over 96% of all AI device clearances — has significant implications. Under 510(k), a device is cleared if it is "substantially equivalent" to a predicate device already on the market. This pathway is faster and less expensive than De Novo classification or premarket approval (PMA), but it also means that many AI devices are cleared for narrow indications that mirror their predicates. A device cleared for detecting pulmonary nodules on chest CT may not have been evaluated for detecting nodules on a different manufacturer's scanner or in a different patient population.
For procurement teams, this means that FDA clearance is a necessary but insufficient condition for deployment. The clearance letter states what the device is authorized to do, but it does not guarantee that the device will perform equivalently in your specific clinical context. Real-world evidence — post-market studies, local validation, and continuous performance monitoring — remains essential.
What Success Looks Like: Three Deployment Case Studies
Despite the barriers, a small number of AI deployments have demonstrated measurable, real-world impact. Three case studies — drawn from a 2025 narrative review in the Journal of Hospital Leadership — illustrate the conditions under which AI tools can succeed in clinical settings.
Case 1: Ambient AI Scribes at Kaiser Permanente

Kaiser Permanente deployed ambient large language model (LLM) scribes to automate clinical documentation during patient encounters. In a single year, the technology reclaimed 15,791 clinician hours — time that would otherwise have been spent on manual note-taking. The scribes listen to the clinician-patient conversation and generate structured clinical notes in real time, reducing the documentation burden that contributes to physician burnout.
The key success factors here include: a large, integrated health system with unified IT infrastructure; a clear, measurable outcome (clinician hours reclaimed); and a tool that directly addresses a well-documented pain point (documentation burden) rather than adding a new task to the workflow.
Case 2: AI-Assisted Mammography Screening in Germany
A German trial involving 463,094 mammograms evaluated AI-assisted reading in breast cancer screening. The results were striking: AI-assisted reading detected 17.6% more cancers (6.7 per 1,000 women, compared to 5.7 per 1,000 with standard double reading) without an increase in false positives. This is a rare example of an AI tool that simultaneously improved sensitivity and maintained specificity in a large-scale, real-world screening program.
The trial's success factors include: a well-defined, high-volume screening task with established performance benchmarks; integration into an existing double-reading workflow rather than replacing human readers; and a study design that allowed direct comparison of AI-assisted vs. standard reading across a very large sample.
Case 3: ICU Alarm Suppression with Machine Learning
In an intensive care unit setting, a machine-learning alarm suppressor reduced false alarms by 60% with no missed critical events. Alarm fatigue is a well-documented patient safety issue in ICUs, where non-actionable alarms desensitize clinicians and can lead to delayed responses to genuine emergencies. By filtering out alarms that the model identified as low-probability for true clinical deterioration, the system reduced noise without compromising safety.
The success factors here include: a clearly defined problem (alarm fatigue) with measurable outcomes (false alarm rate, missed events); a tool that reduces cognitive load rather than adding to it; and rigorous safety monitoring to ensure that no critical events were missed during deployment.
A Four-Phase Leadership Roadmap for Bridging the Gap
The case studies above share common elements: multidisciplinary oversight, iterative piloting, continuous auditing, and transparent governance. These are not accidental features; they are structural requirements for successful AI deployment. The following four-phase roadmap is designed for healthcare administrators and policy professionals who need a practical framework for moving from research to routine use.
| Phase | Focus | Key Actions | Typical Duration |
|---|---|---|---|
| Phase 1: Assess | Organizational readiness and governance | Establish a multidisciplinary AI committee (clinical, IT, legal, compliance); audit existing AI tools and data infrastructure; define success metrics and risk tolerance. | 2–4 months |
| Phase 2: Pilot | Structured evaluation in a controlled setting | Select one high-impact, low-risk use case; run a prospective pilot with pre-specified endpoints; collect data on workflow integration, clinician satisfaction, and performance metrics. | 4–8 months |
| Phase 3: Scale | Expand with continuous bias auditing | Deploy to additional units or sites; implement ongoing performance monitoring for model drift and demographic bias; establish a feedback loop for clinicians to report issues. | 6–12 months |
| Phase 4: Integrate | Embed into workflows with transparent governance | Integrate AI outputs into EHR workflows; publish governance policies and performance dashboards; conduct periodic external audits and update risk assessments. | Ongoing |
The multidisciplinary committee in Phase 1 is not a bureaucratic formality. It is the mechanism through which the three major barrier categories — technical, adoption, and validity — are addressed before they become obstacles. The committee should include not only IT and clinical leadership but also representation from legal, compliance, health equity, and patient experience. Without this breadth of input, a technically sound tool may fail on adoption grounds, or a clinically useful tool may run into regulatory or equity issues that could have been anticipated.
Phase 2's emphasis on prospective pilots with pre-specified endpoints addresses the evidence-quality bottleneck directly. Rather than relying on published literature that may not reflect your patient population, a well-designed pilot generates local evidence that can inform a go/no-go decision. The pilot should measure not only the AI tool's technical performance but also its impact on workflow, clinician time, and patient outcomes.
Continuous bias auditing in Phase 3 is essential because model performance can degrade or shift as patient populations change, new equipment is introduced, or clinical protocols are updated. A model that performed well in a pilot may develop systematic errors over time, particularly for underrepresented subgroups. Auditing should be automated where possible and should include regular reporting to the multidisciplinary committee.
Future Research Priorities and Conclusion
The translational gap in AI healthcare research will not close on its own. The volume of published studies will continue to grow, but without corresponding improvements in evidence quality, reporting standards, and implementation frameworks, the gap between research and deployment may widen.
Several priorities emerge from the evidence reviewed here:
- Improve CONSORT-AI adoption. With only 19% of AI RCTs citing the guideline, journals, funders, and institutional review boards should mandate adherence as a condition of publication or approval.
- Conduct more real-world evidence studies. The gap between controlled trial performance and real-world deployment outcomes is poorly understood. Prospective implementation studies with pragmatic endpoints are needed.
- Address algorithmic bias systematically. Most published studies do not report the demographic composition of their training or validation datasets. Without this information, bias cannot be assessed or mitigated.
- Develop standardized implementation frameworks. The four-phase roadmap proposed here is a starting point, but the field would benefit from validated, specialty-specific frameworks that account for differences in workflow, regulatory requirements, and patient populations.
The path from bench to bedside in AI healthcare is not blocked by a single obstacle but by a system of interconnected barriers: technical, organizational, evidential, and regulatory. Each barrier is surmountable, but only with deliberate, structured effort. The organizations that succeed will be those that invest in multidisciplinary governance, demand local evidence before scaling, and treat AI deployment as an ongoing process of evaluation and improvement — not as a one-time installation.
For a broader overview of current AI applications across clinical specialties, including the evidence base and deployment realities for each, see our structured brief on AI in healthcare clinical applications.
Comments
Join the discussion with an anonymous comment.