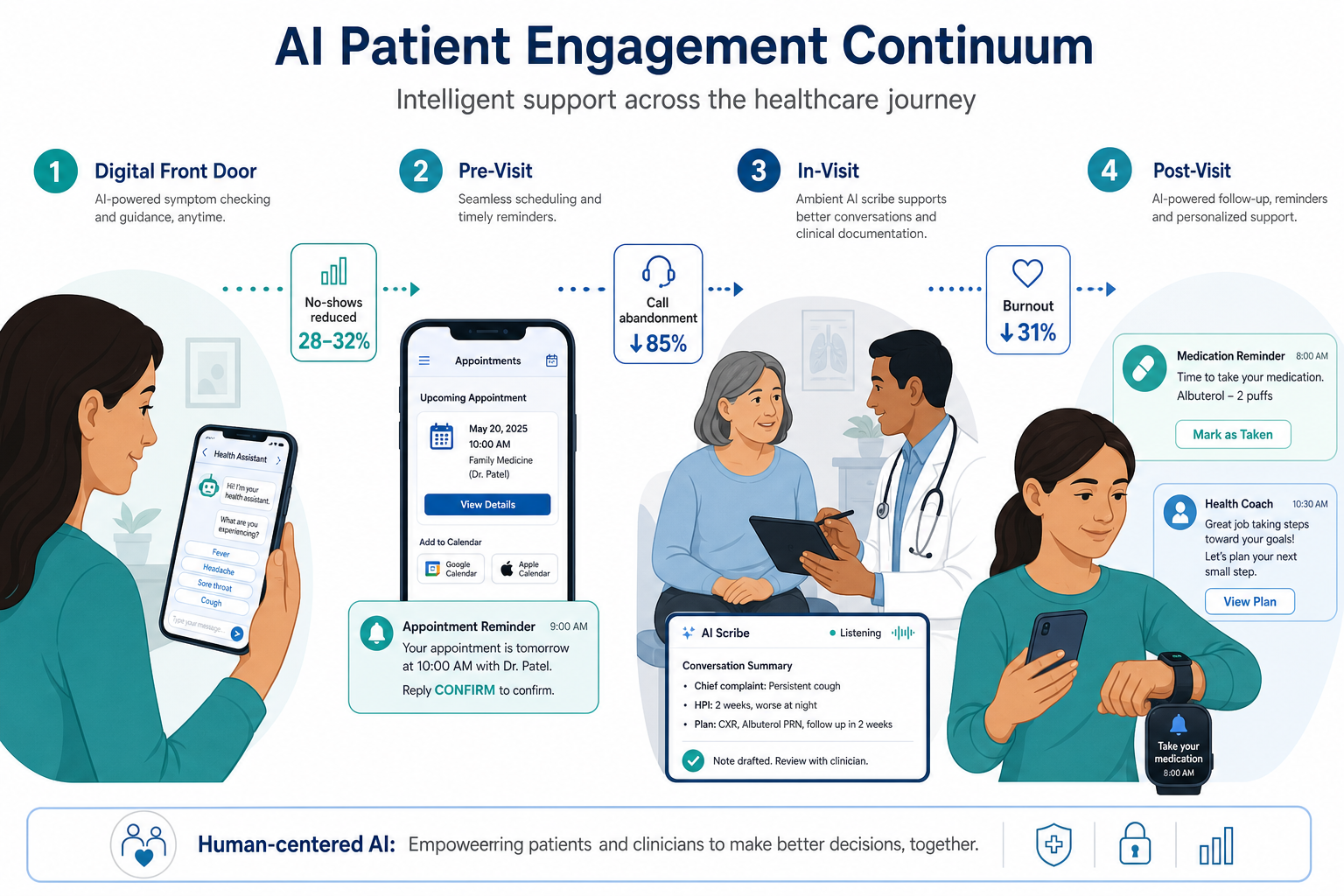
Introduction: Defining AI Patient Engagement and the Need for Evidence Grading
AI patient engagement encompasses a growing set of technologies — automated reminders, conversational agents, predictive analytics, and digital coaching platforms — designed to influence patient behavior across the care continuum. The promise is substantial: missed appointments alone cost the U.S. healthcare system an estimated $150 billion annually, and AI in healthcare operations could save up to $360 billion per year according to industry estimates. Yet the clinical evidence supporting these tools is far from uniform.
This article provides a structured, evidence-graded review of AI patient engagement outcomes across five distinct use cases: no-show prediction and appointment optimization, conversational AI for mental health therapy support, chronic disease self-management, clinical trial patient engagement, and AI-powered patient communication platforms. For each use case, we assess the strength of available evidence — study design, sample size, performance metrics, and known limitations — rather than treating all claims as equally valid.
The core thesis is straightforward: the clinical evidence for AI patient engagement is uneven across use cases. No-show reduction benefits from the strongest evidence base, including randomized controlled trials and real-world deployments. Mental health therapy support shows promising results from a single pre-registered RCT. Chronic disease self-management and clinical trial engagement remain at earlier stages of validation, with most applications lacking rigorous multi-site prospective studies. Understanding this evidence hierarchy is essential for clinicians and health systems making adoption decisions.

Use Case 1: No-Show Prediction and Appointment Optimization
No-show prediction and appointment optimization represents the most mature evidence tier in AI patient engagement. The clinical and financial problem is well-documented: patient no-shows cost the U.S. healthcare system $150 billion annually, with the average missed appointment costing $200. Independent practices lose an average of $150,000 per year from no-shows alone. Despite this burden, only 19% of medical group practices use AI for patient communication according to a 2025 MGMA survey, indicating a significant adoption gap.
AI-driven engagement sequences typically employ a three-touch approach: immediate confirmation after booking, a 48-hour reminder with rescheduling options, and a same-day check-in prompt. When deployed with conversational AI, these sequences have demonstrated 28-32% reductions in no-show rates within 60 days. This range draws from multiple sources, including academic studies and real-world implementations.
| Source | Setting | Key Finding | Evidence Type |
|---|---|---|---|
| Health Catalyst case study | Memorial Hospital Gulfport | 28% no-show reduction; $804K additional revenue over 7 months | Real-world deployment |
| UAB automated voice outreach | Endoscopy/colonoscopy scheduling | 75% lower cancellation rate | Single-institution outcome |
| AI-powered 3-touch sequences | Multi-site (academic + vendor data) | 28-32% no-show reduction within 60 days | Combined academic and vendor claims |
| MGMA Stat 2025 | National practice survey | 27% of leaders cite no-shows as top 2026 operational focus | Industry survey |
The University of Alabama at Birmingham (UAB) provides a notable single-institution example: automated voice outreach for patients scheduled for endoscopy or colonoscopy resulted in a 75% lower cancellation rate. At Memorial Hospital Gulfport, a Health Catalyst case study documented a 28% reduction in no-shows and $804,000 in additional revenue over seven months. These figures, while compelling, come from single-site implementations rather than multi-center trials.
For a deeper dive into conversational AI's specific role in no-show reduction, including specialty-specific variation and detailed ROI analysis, see our companion article: Conversational AI for No-Show Reduction: Clinical Evidence and ROI Across Specialties.
Use Case 2: Conversational AI for Mental Health Therapy Support
Mental health therapy support represents a promising but early-stage evidence tier. The most rigorous study to date is a January 2026 pre-registered randomized controlled trial published in Communications Medicine (Nature Portfolio) that evaluated Limbic Care, a generative AI-enabled cognitive-behavioral therapy (CBT) application. The trial enrolled 540 participants and compared the AI-driven intervention against standard digital CBT workbooks over six weeks.
| Metric | AI-Driven CBT (Limbic Care) | Digital Workbook (Control) | Statistical Significance |
|---|---|---|---|
| Engagement frequency | 2.4x higher | Baseline | Significant |
| Engagement duration | 3.8x longer | Baseline | Significant |
| Anxiety reduction (GAD-7) | Comparable | Comparable | No significant difference |
| Depression reduction (PHQ-9) | Comparable | Comparable | No significant difference |
| Adverse events | No significant difference | No significant difference | BF01 = 8.878 (evidence of equivalence) |
The primary finding was that participants assigned to the AI-driven CBT app demonstrated 2.4 times higher engagement frequency and 3.8 times longer engagement duration compared to those using digital workbooks. Importantly, the study found comparable safety profiles — there was no significant difference in adverse events between groups, with a Bayes factor of 8.878 supporting evidence of equivalence. Symptom reduction on the GAD-7 (anxiety) and PHQ-9 (depression) scales was also comparable between arms.
Exploratory analyses suggested that participants who engaged more deeply with AI-driven guided sessions showed greater anxiety reduction and improved wellbeing, hinting at a dose-response relationship that warrants further investigation.
Use Case 3: Chronic Disease Self-Management
Chronic disease self-management represents an emerging evidence tier. A 2025 narrative review published in Frontiers in Public Health identified four primary roles for AI in chronic care: personalized decision support, continuous monitoring and risk prediction, conversational agents for coaching and adherence, and AI-enabled mHealth platforms. However, the review itself is narrative rather than systematic, and most applications remain in feasibility or pilot stages.
Among chronic conditions, diabetes has the strongest evidence base. Predictive models integrating continuous glucose monitor (CGM) data have achieved 0.814 accuracy for next-day hypoglycemia prediction. For cardiovascular disease, wearable-based AI screening studies — including the Apple Heart Study (419,000 participants) and the Fitbit Heart Study (455,000 participants) — have demonstrated atrial fibrillation detection feasibility with positive predictive values ranging from 84% to 98%. AI-powered digital pain coaches tested in a prospective multicenter trial showed significant improvements in pain interference, physical function, and psychological distress over 12 weeks.
| Condition | AI Application | Key Evidence | Evidence Stage |
|---|---|---|---|
| Diabetes | Predictive models using CGM data | 0.814 accuracy for next-day hypoglycemia prediction | Feasibility / Pilot |
| Atrial fibrillation | Wearable-based AI screening | 84-98% PPV (Apple Heart Study, Fitbit Heart Study) | Large-scale feasibility |
| Chronic pain | AI-powered digital pain coach | Significant improvement in pain interference, physical function, psychological distress (12-week prospective multicenter trial) | Prospective single trial |
| General chronic disease | Conversational agents, mHealth platforms | Four AI roles identified (narrative review) | Framework / Pilot |
Recurrent challenges identified across the literature include data privacy concerns, algorithmic bias, the digital divide affecting access to AI-enabled tools, and a general lack of long-term effectiveness data. Most importantly, no AI-driven chronic disease self-management application has yet been validated in a multi-site randomized controlled trial with diverse patient populations and long-term follow-up.
Use Case 4: Clinical Trial Patient Engagement
Clinical trial patient engagement represents the most limited evidence tier among the five use cases reviewed. Current applications are largely framework-level, with AI being explored for several discrete functions within the clinical trial lifecycle:
- Patient recruitment via EHR scanning to identify eligible candidates
- Patient motivation and retention through push notifications and chatbot interactions
- Safety monitoring through automated adverse event detection
- Data collection via guided electronic patient-reported outcome (ePRO) capture and wearable integration
These use cases are described in industry literature and vendor materials, but no RCT-level evidence currently exists demonstrating that AI-driven engagement improves clinical trial recruitment rates, retention, or data quality compared to standard approaches. The absence of peer-reviewed evidence in this domain is notable given the high cost of patient recruitment and retention in clinical trials.
Patient trust remains a significant barrier to AI adoption in clinical trial contexts. A survey cited by ObvioHealth found that 42% of patients welcome AI's assistance in healthcare decisions (from a 2019 survey). More recently, a July 2025 PatientPoint survey of 2,000 Americans found that only 19% trust AI to diagnose and care for them, and patients trust their doctor 4 times more than AI chatbots. These trust dynamics are particularly relevant for clinical trial engagement, where patient willingness to participate depends heavily on perceived credibility and transparency.
Use Case 5: AI-Powered Patient Communication Platforms
AI-powered patient communication platforms occupy a promising-to-moderate evidence tier, supported primarily by real-world deployment case studies rather than controlled trials. The most substantial evidence comes from a PwC case study documenting the deployment of conversational AI across 50+ health system sites via Salesforce Health Cloud.
| Metric | Pre-AI Baseline | Post-AI Deployment | Improvement |
|---|---|---|---|
| Call abandonment rate | Not disclosed | 85% reduction | 85% relative reduction |
| Self-service resolution | Not available | 11% of callers resolved issues without agent | New capability |
| Staff hours saved | Baseline | 3,000+ hours per month | Reallocated to clinical activities |
| Patient communication channels | Phone only | Multi-channel (voice, text, web) | Expanded access |
The implementation reduced call abandonment by 85%, with 11% of callers resolving their issues through self-service without needing to speak to a human agent. The health system saved over 3,000 hours per month, freeing up staff capacity for clinical activities. The UAB example — a 75% lower cancellation rate from automated voice outreach — further supports the potential of AI-driven communication platforms, though as a single-institution outcome.
Market projections underscore growing interest in this space. Frost & Sullivan estimates the global conversational AI market in healthcare will reach $2.34 billion by 2027. However, market size estimates vary considerably between research firms, and these projections should be treated as directional rather than definitive.
Evidence Maturity Assessment: Cross-Use-Case Comparison
The following matrix provides a structured comparison of evidence maturity across all five use cases, graded on a four-tier scale: Strong, Promising, Emerging, and Limited. This cross-cutting assessment is the article's core differentiator — a synthesis that existing same-site content does not provide.

| Use Case | Evidence Maturity | Best Available Evidence | Key Limitation |
|---|---|---|---|
| No-Show Reduction | Strong | 28-32% reduction (RCTs + real-world deployments) | Single-site case studies; vendor-reported data mixed with academic |
| Mental Health Therapy | Promising | 2.4x frequency, 3.8x duration (RCT, n=540) | Single RCT; industry-funded; no multi-site replication |
| Patient Communication Platforms | Promising | 85% call abandonment reduction (case study, 50+ sites) | Unnamed health system; no controlled trial |
| Chronic Disease Self-Management | Emerging | Narrative review; 0.814 hypoglycemia prediction accuracy | No multi-site RCTs; narrative review methodology |
| Clinical Trial Engagement | Limited | Framework-level use cases; no RCT data | No peer-reviewed evidence for AI-driven engagement outcomes |
This assessment reveals a clear pattern: use cases that address well-defined, high-volume operational problems with clear ROI (no-show reduction, communication platforms) have attracted the most investment and generated the strongest evidence. Use cases that involve more complex clinical workflows and longer-term outcomes (chronic disease self-management, clinical trial engagement) remain at earlier stages of validation, despite their potentially greater clinical impact.
Limitations, Evidence Gaps, and Future Directions
Several common limitations cut across all five use cases and should inform how readers interpret the evidence:
- Industry funding: The most rigorous study in this review — the Limbic Care RCT — was funded by the intervention developer, with some authors as employees or equity holders. While peer-reviewed and pre-registered, this funding structure is common across the AI patient engagement literature and raises questions about publication bias.
- Lack of multi-site prospective validation: No use case in this review has been validated in a multi-site randomized controlled trial with diverse patient populations. The strongest evidence (no-show reduction) comes from single-site case studies and vendor-reported data.
- Narrative vs. systematic review methodology: The chronic disease self-management review is narrative without a PRISMA framework, limiting its methodological rigor.
- Patient trust barriers: Only 19% of Americans trust AI to diagnose and care for them (July 2025 survey), and 88% prefer receiving medical information directly from their doctor. These trust dynamics may limit patient willingness to engage with AI-driven tools, particularly in clinical trial and chronic disease contexts.
- Low adoption rates: Only 19% of medical practices currently use AI for patient communication (MGMA 2025), suggesting that even the strongest evidence has not translated into widespread adoption.
Market size discrepancies further complicate the landscape. Different research firms produce widely varying estimates — Research Nester projected the AI patient engagement market at $7.86 billion in 2025 with a 19.4% CAGR, while Research and Markets estimated $11.28 billion in 2026 with a 21.7% CAGR. These discrepancies reflect differing methodologies and definitions, and readers should treat all market projections with appropriate caution.
For readers interested in the financial and operational ROI perspective, see our companion article: The ROI of AI Patient Engagement: Evidence, Outcomes, and the Business Case for Investment. For a detailed treatment of regulatory and evidence gaps specific to conversational AI, see: The Evidence Gap and Regulatory Landscape for Conversational AI in Healthcare.
Comments
Join the discussion with an anonymous comment.