

Introduction: The Promise and the Evidence Gap Across Conditions
Conversational AI — chatbots and voice-based agents that interact with patients in natural language — has been proposed as a scalable solution for chronic disease self-management. The logic is straightforward: patients with diabetes, heart failure, COPD, and asthma require ongoing monitoring, medication adjustments, and lifestyle support between clinic visits, and a conversational agent could deliver this at low marginal cost. But the evidence supporting this promise is not uniform across conditions.
A 2025 narrative review by Du et al. surveying AI applications in chronic care found that diabetes has the strongest maturation in monitoring and predictive analytics, with integrated coaching systems and AI-driven clinical decision support. Heart failure and COPD platforms, by contrast, remain at feasibility-to-pilot stages, with most studies reporting technical metrics or engagement outcomes rather than clinical endpoint improvements. This disparity matters for clinicians and researchers making adoption or investment decisions.
This article builds a condition-specific evidence hierarchy for conversational AI in chronic disease self-management. It contrasts the relatively robust randomized controlled trial (RCT) evidence for diabetes chatbots with the feasibility-stage evidence for heart failure, COPD, and asthma. The goal is not to dismiss emerging applications but to provide a framework for distinguishing between conditions where conversational AI is ready for cautious clinical adoption and those where it remains investigational. For a broader view of conversational AI applications across healthcare, see our analysis of conversational AI for no-show reduction, which covers a different use case with its own evidence base.
Diabetes: The Strongest RCT Evidence for Conversational AI
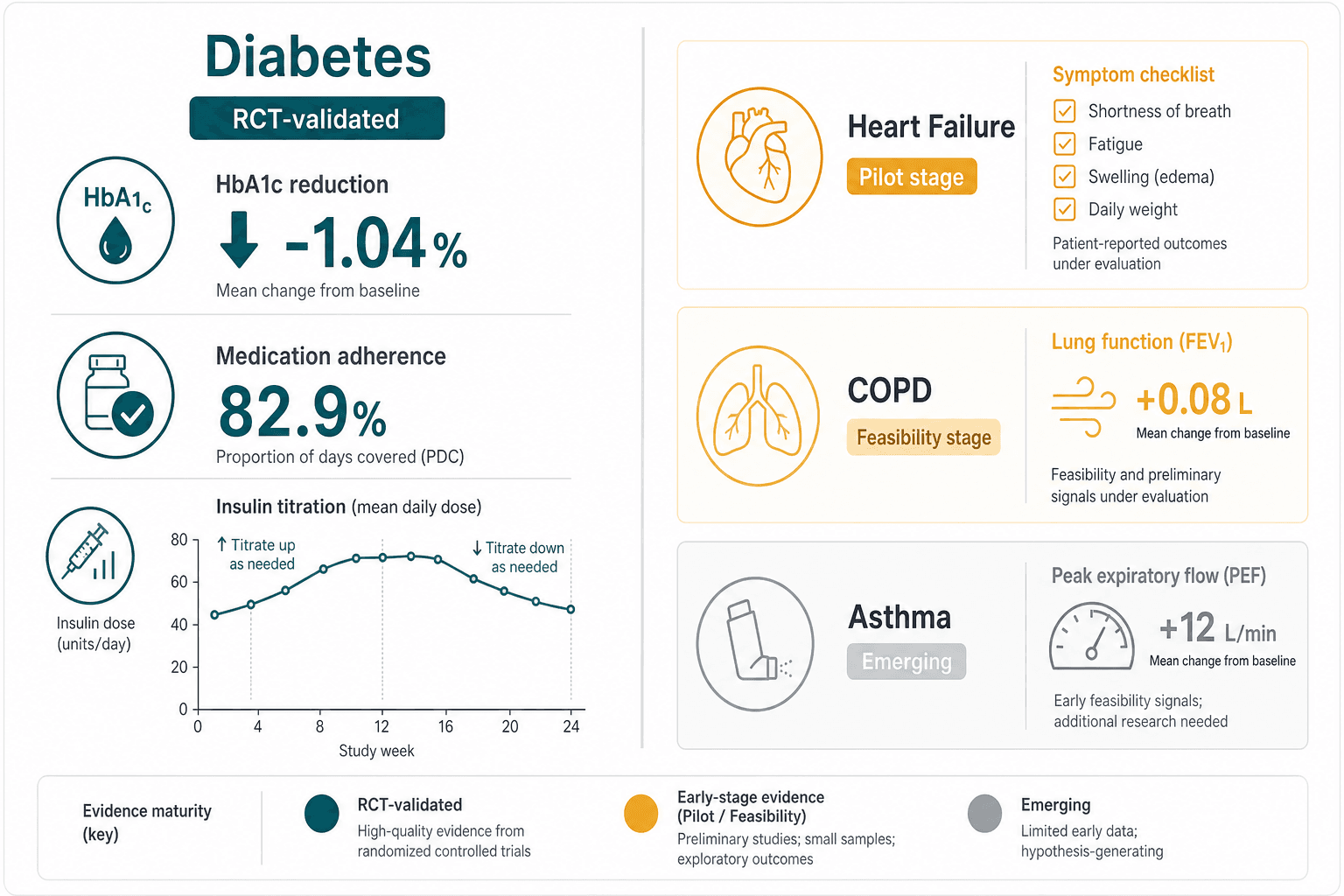
Diabetes is the only chronic condition where conversational AI has been evaluated in multiple RCTs with clinically meaningful endpoints. A 2025 systematic review by Shegal et al. identified 16 studies involving 9,076 participants across 13 countries. Eleven of those studies assessed effectiveness, and most reported improvements in glycemic control, medication adherence, health behaviors, or mental health outcomes.
Key RCT Findings
The most frequently cited outcome is HbA1c reduction. Across the studies reviewed by Shegal et al., conversational agent interventions produced HbA1c drops ranging from 0.3% to 1.0%. A 2025 trial by Nassar et al. reported a mean HbA1c decrease of −1.04%, with 87% of active users reporting increased self-care confidence. These effect sizes are clinically relevant — a 0.5% reduction in HbA1c is associated with reduced microvascular complication risk in type 2 diabetes.
Medication adherence data are equally striking. The VBAI trial (Nayak et al., 2023), published in JAMA Network Open, compared a conversational agent for insulin titration against standard care. The chatbot group achieved 82.9% insulin adherence versus 50.2% in the control group, and the median time to reach optimal insulin dosing was 15 days compared with 56 days. These are not marginal improvements — they represent a fundamental shift in how patients manage a complex daily medication regimen.
Not all trials have been uniformly positive. The My Diabetes Coach (MDC) trial (Gong et al., 2020), one of the earliest and most cited RCTs in this space, found improved health-related quality of life but no statistically significant difference in HbA1c between the chatbot and control groups. This heterogeneity is important: it suggests that conversational AI may benefit some patient subgroups more than others, and that the specific design of the agent — its interactivity, personalization, and integration with clinical workflows — matters as much as the technology itself.
| Study | Year | Design | Sample Size | Key Outcome |
|---|---|---|---|---|
| Nassar et al. | 2025 | RCT | Not specified in review | HbA1c reduction −1.04%; 87% reported increased self-care confidence |
| Nayak et al. (VBAI trial) | 2023 | RCT | Not specified in review | 82.9% vs 50.2% insulin adherence; 15 vs 56 days to optimal dosing |
| Gong et al. (MDC trial) | 2020 | RCT | Not specified in review | Improved HRQoL; no significant HbA1c difference |
| Shegal et al. (systematic review) | 2025 | Systematic review of 16 studies | 9,076 participants across 13 countries | HbA1c reductions 0.3%–1.0%; improved medication adherence and health behaviors |
For clinicians managing patients with diabetes, conversational AI tools represent a potentially valuable addition to the care team — but they are not a replacement for clinical judgment. The evidence supports their use as adjuncts for medication adherence support and self-management education, particularly for patients struggling with insulin titration or lifestyle modifications. For a related AI application addressing diabetes complications, see our analysis of AI diabetic retinopathy screening at community health centers, which covers a different but complementary AI tool for diabetes care.
Heart Failure: Emerging Platforms, Limited Chatbot-Specific RCT Evidence
Heart failure self-management requires daily weight monitoring, symptom tracking, medication adherence, and timely escalation when decompensation occurs. Several digital health platforms now incorporate conversational agents for symptom check-ins and patient education. However, the evidence base for chatbot-specific interventions in heart failure is substantially thinner than for diabetes.
The Du et al. 2025 narrative review characterizes heart failure AI platforms as being at the feasibility-to-pilot stage. Most published studies report patient-reported outcomes and engagement metrics — such as the number of symptom check-ins completed or patient satisfaction scores — rather than hard clinical endpoints like hospitalization rates, mortality, or ejection fraction changes. No large-scale RCT has demonstrated that a conversational agent, as distinct from a broader remote monitoring program, reduces heart failure readmissions.
- Current platforms typically combine symptom check-ins with risk stratification models, but the conversational agent component is often one part of a multi-modal intervention, making it difficult to isolate its effect.
- Outcome measures in published studies are predominantly patient-reported: quality of life scores, self-care confidence, and usability ratings.
- Sample sizes are small, and few studies include a control group receiving standard care without the conversational agent.
- No study has yet demonstrated that a heart failure chatbot reduces 30-day readmission rates or all-cause mortality — the endpoints that matter most to cardiologists and health systems.
This does not mean heart failure chatbots lack potential. Patients with heart failure often struggle with the complexity of daily self-monitoring and medication management, and a well-designed conversational agent could plausibly improve adherence and early detection of decompensation. But the evidence simply has not caught up to the promise. Clinicians evaluating heart failure chatbots for adoption should ask whether the platform has published any peer-reviewed data on clinical outcomes, not just engagement metrics.
COPD: Virtual Agents for Exacerbation Action Plans and Monitoring
Chronic obstructive pulmonary disease (COPD) self-management centers on recognizing early signs of exacerbation, adhering to inhaler regimens, and following personalized action plans. Several research groups have developed virtual agents to support these tasks, typically delivered via smartphone applications with text-based or voice-based interaction.
The evidence for COPD conversational AI is, like heart failure, predominantly at the feasibility stage. The Du et al. review notes that COPD platforms remain in early development, with most studies focused on usability testing and technical validation rather than clinical effectiveness. A 2021 systematic review by Griffin et al. of conversational agents for chronic disease self-management included only 12 studies total, and the majority targeted mental health rather than physical chronic diseases. Only one study in that review focused on diabetes; none focused specifically on COPD.
- Published COPD chatbot studies typically report usability outcomes (e.g., system usability scale scores, task completion rates) and engagement metrics (e.g., daily log-in rates, number of symptom reports submitted).
- Clinical outcomes, when reported, are limited to patient-reported outcomes such as COPD Assessment Test (CAT) scores or modified Medical Research Council (mMRC) dyspnea scores.
- No RCT has demonstrated that a conversational agent reduces COPD exacerbation rates, hospitalizations, or mortality.
- Sample sizes in published studies are small — typically fewer than 100 participants — and follow-up periods are short.
The gap between promise and proven benefit is particularly wide in COPD because exacerbation prevention requires not just monitoring but timely clinical action. A chatbot can remind a patient to use their inhaler or report worsening symptoms, but it cannot prescribe antibiotics or corticosteroids — those decisions require a clinician. The value proposition for COPD chatbots may ultimately depend on integration with telemedicine or remote monitoring programs that include a human-in-the-loop for escalation decisions.
Asthma: Minimal Chatbot-Specific Evidence
Asthma occupies the lowest tier in the evidence hierarchy. There is minimal chatbot-specific evidence for asthma self-management. The Griffin et al. 2021 systematic review, which remains one of the most comprehensive surveys of conversational agents for chronic disease, identified no studies focused on asthma. The Du et al. 2025 review similarly does not highlight asthma as a domain with meaningful conversational AI evidence.
This evidence gap is not necessarily a reflection of the technology's potential. Asthma self-management involves several tasks that conversational agents could theoretically support: inhaler adherence tracking, symptom diary maintenance, recognition of worsening control, and adherence to action plans. Several digital health platforms for asthma exist, but they typically use rule-based algorithms or simple reminders rather than natural language conversational agents.
The honest assessment is that asthma conversational AI is at a pre-evidence stage. No published study has evaluated a chatbot for asthma self-management in a controlled trial with clinically meaningful endpoints. Clinicians and researchers should treat any claims about asthma chatbot effectiveness as speculative until peer-reviewed evidence emerges.
Evidence Hierarchy Table: Condition-by-Condition Comparison
The following table summarizes the evidence for conversational AI across the four conditions, providing a structured comparison that clinicians and researchers can use to assess readiness for adoption or further investigation.
| Condition | Study Type Available | Total Participants (Published Studies) | Key Outcomes | Evidence Quality Rating |
|---|---|---|---|---|
| Diabetes | Multiple RCTs; systematic review (16 studies) | 9,076 (Shegal et al. 2025 review) | HbA1c reductions 0.3%–1.0%; 82.9% vs 50.2% insulin adherence; improved HRQoL in some trials | Strong — multiple RCTs with clinically meaningful endpoints; however, only 25% assessed safety |
| Heart Failure | Feasibility/pilot studies; narrative review context only | Small samples (<100 per study typical) | Patient-reported outcomes; engagement metrics; no demonstrated reduction in hospitalizations or mortality | Weak — no chatbot-specific RCTs with clinical endpoints |
| COPD | Feasibility/pilot studies; no condition-specific systematic review | Small samples (<100 per study typical) | Usability outcomes; patient-reported symptom scores; no demonstrated reduction in exacerbations | Weak — predominantly usability and feasibility data |
| Asthma | No published chatbot-specific studies identified | None | No published clinical outcomes for conversational AI in asthma | Very weak — no evidence base to evaluate |
Implications for Clinical Adoption and Research Prioritization
The evidence hierarchy presented here has direct implications for clinicians, health system administrators, and researchers evaluating conversational AI for chronic disease management.
For Clinicians: When to Consider Adoption
Diabetes is the only condition where the evidence supports cautious clinical adoption of conversational AI as an adjunct to standard care. The HbA1c reductions and adherence improvements demonstrated in RCTs are clinically meaningful, and the safety profile, while underreported, has not revealed major harms in published studies. Clinicians managing patients with type 2 diabetes who struggle with medication adherence or insulin titration may reasonably consider referring them to a validated conversational AI program.
For heart failure, COPD, and asthma, the evidence does not yet support routine clinical adoption of conversational AI for self-management. Patients may benefit from engagement with these tools in research settings or pilot programs, but clinicians should not expect — and should not promise — improvements in clinical outcomes such as hospitalization rates or exacerbation frequency. For a broader perspective on how AI tools are being evaluated across primary care settings, see our evidence-graded guide to AI in primary care.
For Researchers: Where to Invest Effort
The evidence hierarchy reveals several clear research priorities:
- Safety reporting must become standard in diabetes chatbot trials. The finding that only 25% of studies assessed safety (Shegal et al. 2025) is a critical gap. Future RCTs should include adverse event monitoring, hypoglycemia tracking, and clear protocols for handling chatbot-generated recommendations that conflict with clinician guidance.
- Heart failure and COPD need chatbot-specific RCTs with hard clinical endpoints. The field cannot continue to rely on feasibility studies and patient-reported outcomes. Researchers should design trials with hospitalization rates, exacerbation frequency, and mortality as primary endpoints.
- Asthma needs foundational evidence. Before any clinical adoption can be considered, the field needs at least one well-designed feasibility study with usability and engagement outcomes, followed by a pilot RCT with symptom control as the primary endpoint.
- Comparative effectiveness studies are needed across conditions. The field would benefit from head-to-head trials comparing conversational AI against other self-management support modalities (e.g., nurse-led telephone coaching, mobile app-based education, in-person diabetes education) to establish whether the conversational agent format itself adds value.
Distinguishing Self-Management from Clinical Decision Support
A critical distinction that clinicians must make is between conversational AI for self-management and conversational AI for clinical decision support (CDS). Self-management tools help patients follow treatment plans; CDS tools help clinicians make diagnostic or therapeutic decisions. The evidence hierarchy presented here applies only to self-management. For a detailed analysis of how conversational AI functions in CDS workflows and the regulatory considerations involved, see our article on AI clinical decision support in primary care.
The distinction matters because the evidence standards are different. A self-management chatbot that provides incorrect insulin dosing advice could cause harm, but the risk is generally lower than a CDS tool that leads a clinician to make an incorrect diagnosis. The FDA's January 2026 updated CDS guidance, which expands enforcement discretion for certain single-output recommendations, does not apply to self-management tools in the same way. Clinicians should be aware that the regulatory landscape for conversational AI is evolving differently for these two use cases.
The Asymmetry of AI Influence
Clinicians should also be aware of the asymmetric influence that AI-generated recommendations can have on decision-making. Research has shown that clinicians may be more likely to follow an AI recommendation to act (e.g., prescribe a medication) than to withhold action, even when the evidence base for the recommendation is weak. This asymmetry is particularly relevant for conversational AI in chronic disease, where the chatbot may suggest medication adjustments or lifestyle changes that a patient then requests from their clinician. For a deeper exploration of this phenomenon, see our analysis of the asymmetric influence of clinical decision support on primary care physicians.
Comments
Join the discussion with an anonymous comment.